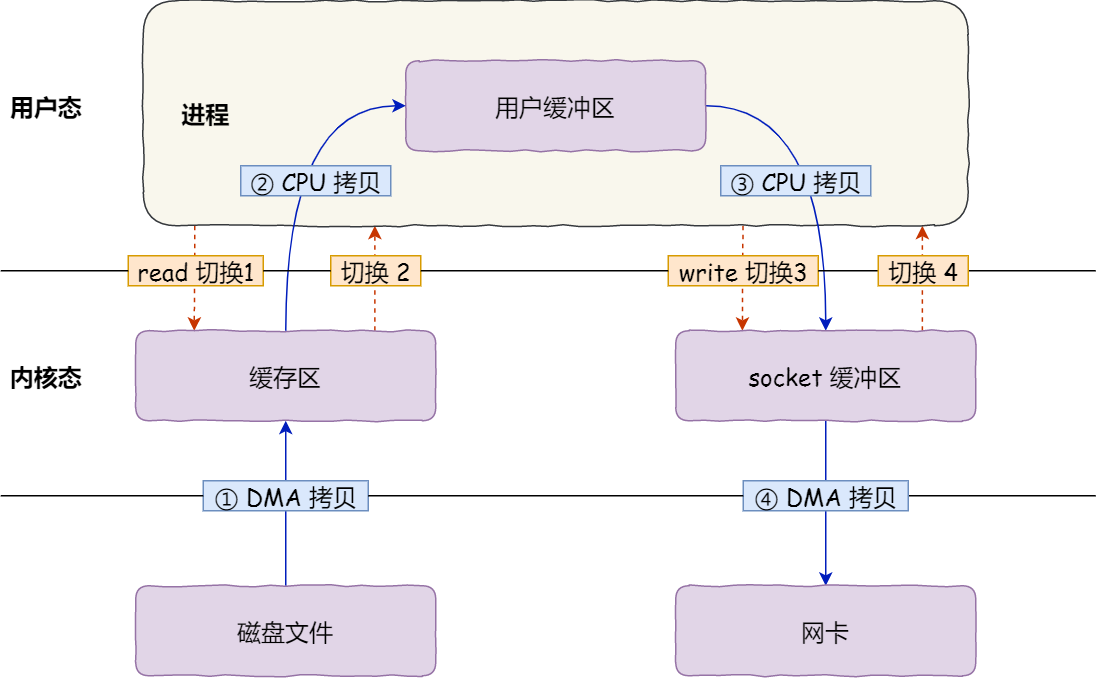
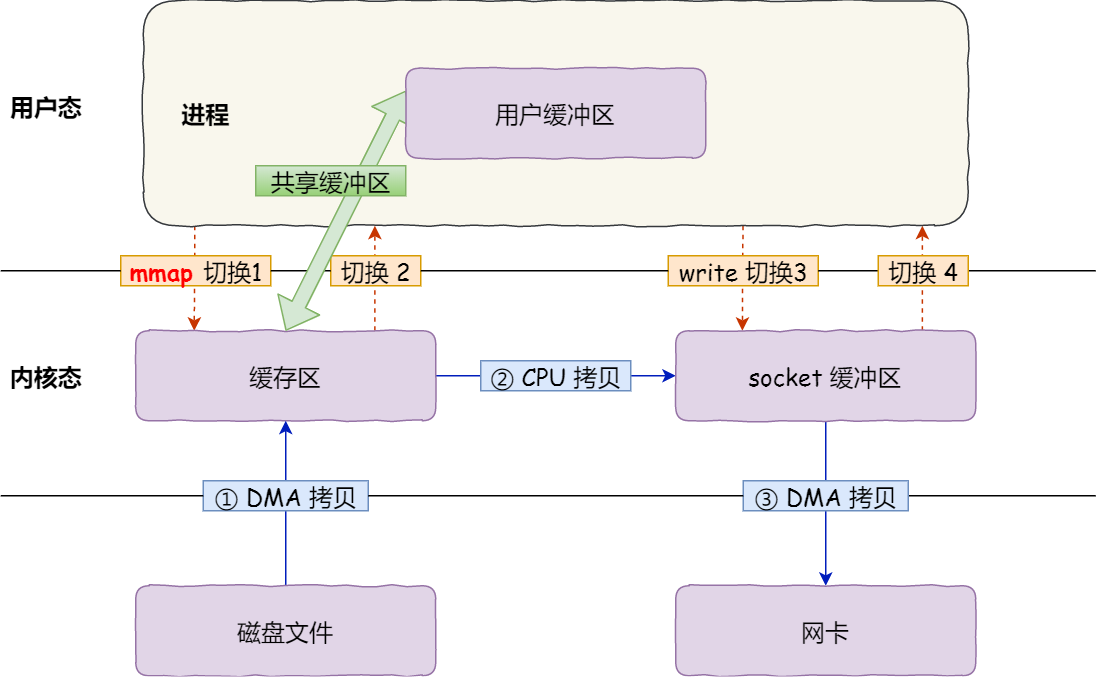
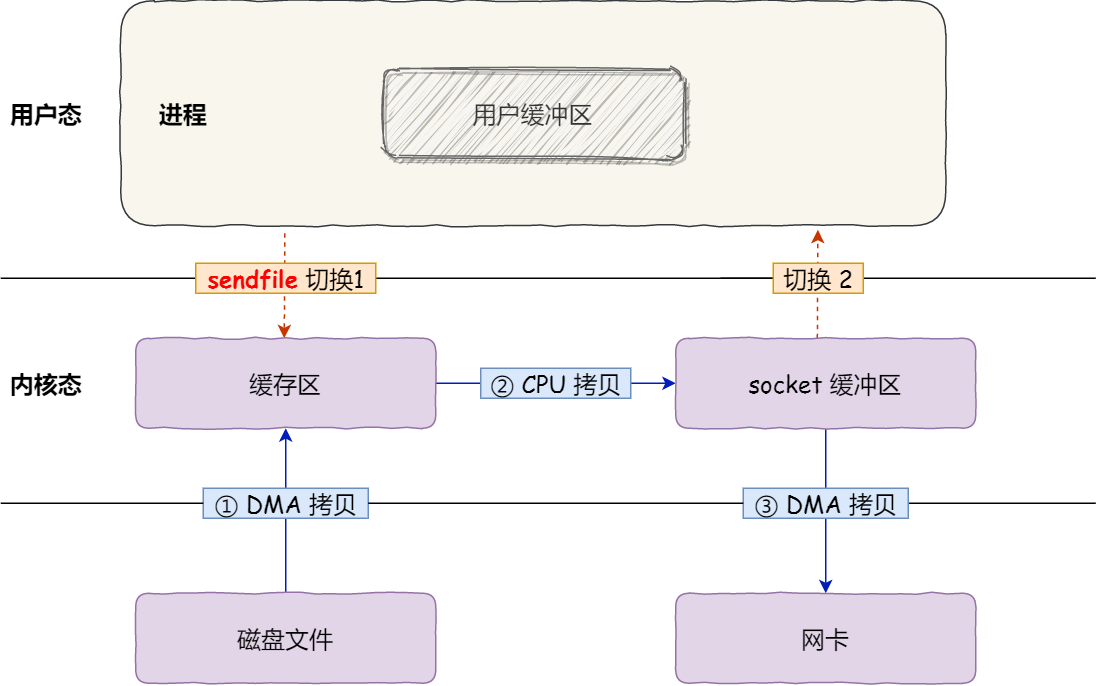
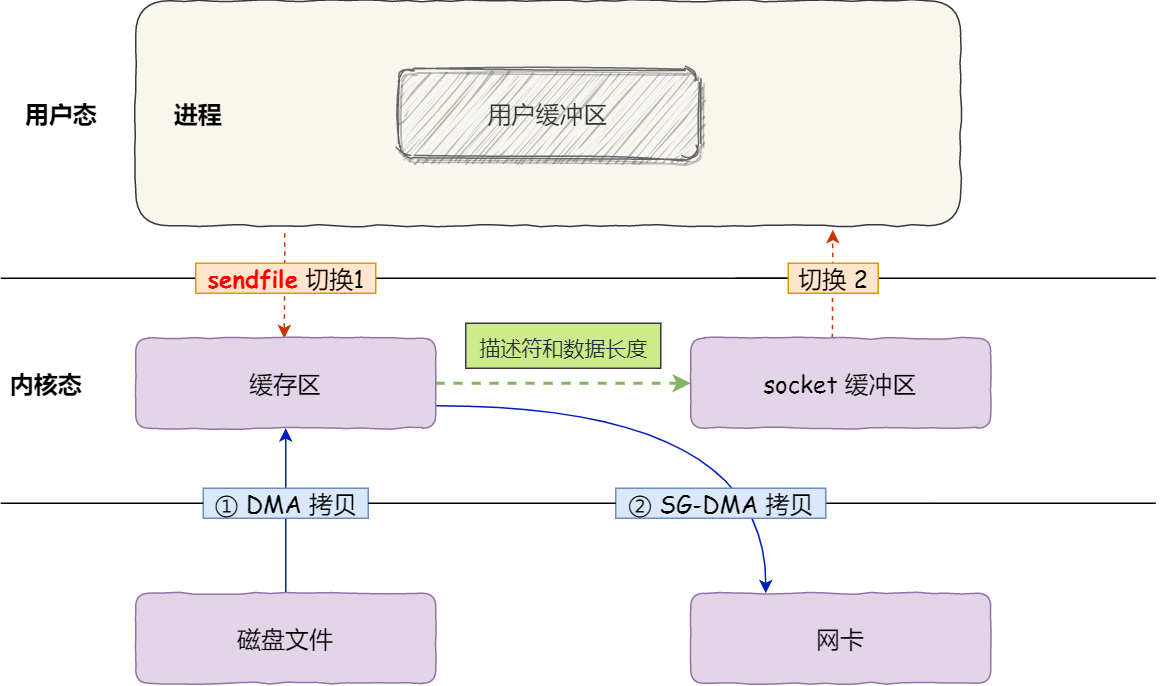
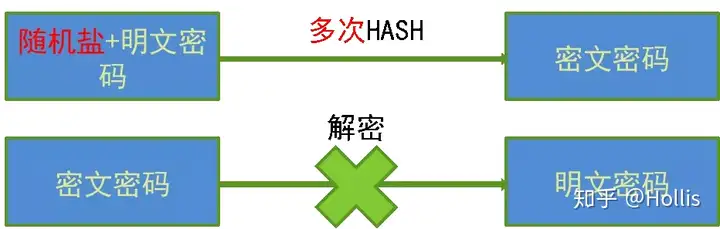
ifndef 由语言本身提供支持,但是 program once 一般由编译器提供支持,也就是说,有可能出现编译器不支持的情况(主要是比较老的编译器)。
通常运行速度上 ifndef 一般慢于 program once,特别是在大型项目上, 区别会比较明显,所以越来越多的编译器开始支持 program once。
ifndef 作用于某一段被包含(define 和 endif 之间)的代码, 而 program once 则是针对包含该语句的文件, 这也是为什么 program once 速度更快的原因。
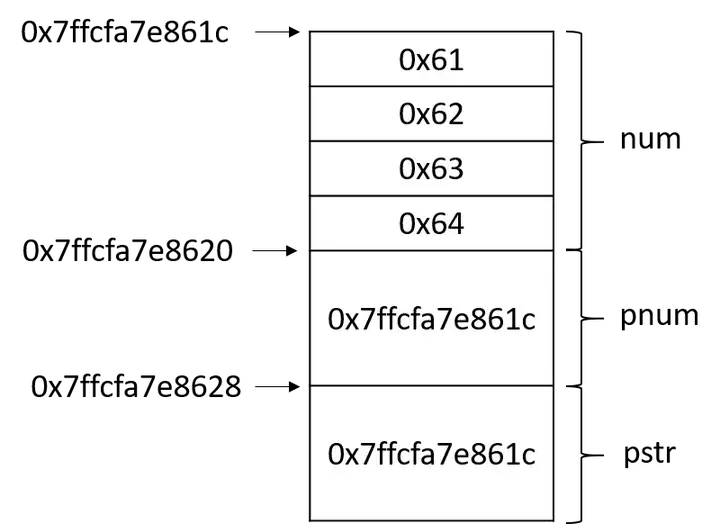
指针数组和数组指针
数组指针,是指向数组的指针,而指针数组则是指该数组的元素均为指针。
数组指针,是指向数组的指针,其本质为指针,形式如下。如 int (*p)[n],p即为指向数组的指针,()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。数组指针是指向数组首元素的地址的指针,其本质为指针,可以看成是二级指针,一般用作二维数组。
1
类型名 (*数组标识符)[数组长度]
指针数组,在C语言和C++中,数组元素全为指针的数组称为指针数组,其中一维指针数组的定义形式如下。指针数组中每一个元素均为指针,其本质为数组。如 int *p[n], []优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1时,则p指向下一个数组元素,这样赋值是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]…p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
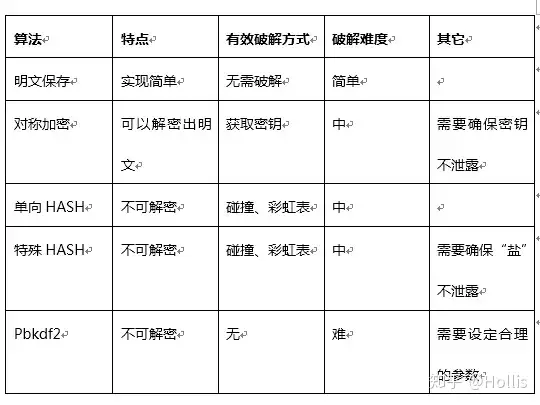
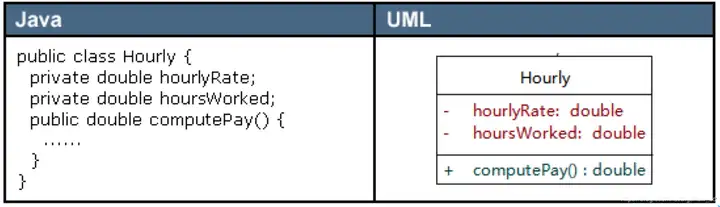
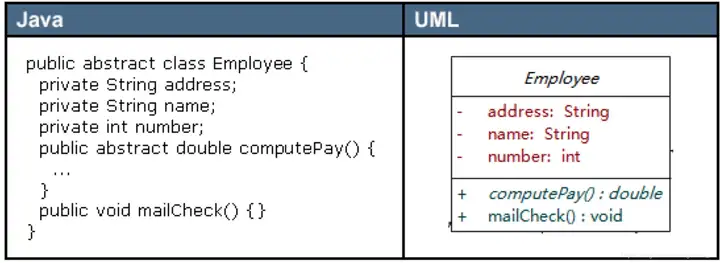
简单数据类型(包括基本数据类型和不需要构造函数的类型) 简单类型直接调用 operator new 分配内存; 可以通过new_handler 来处理 new 失败的情况; new 分配失败的时候不像 malloc 那样返回 NULL,它直接抛出异常(bad_alloc)。要判断是否分配成功应该用异常捕获的机制;
复杂数据类型(需要由构造函数初始化对象) new 复杂数据类型的时候先调用operator new,然后在分配的内存上调用构造函数。
比如table 是一个数组,那么如何最快的将元素 e 放入数组 ? 当然是找到元素 e 在 table 中对应的位置 index ,然后 table[index] = e; 就好了;如何找到 e 在 table 中的位置了 ? 我们知道只能通过数组下标(索引)操作数组,而数组的下标类型又是 int ,如果 e 是 int 类型,那好说,就直接用 e 来做数组下标(若 e > table.length,则可以 e % table.length 来获取下标),可 key - value 中的 key 类型不一定,所以我们需要一种统一的方式将 key 转换成 int ,最好是一个 key 对应一个唯一的 int (目前还不可能, int有范围限制,对转换方法要求也极高),所以引入了 hash 方法。拿到了 key 对应的 哈希值h 之后,我们最容易想到的对 value 的 put 操作如下:
静态优先级是指进程在创建时就确定的优先级,一旦确定就不会发生变化。通常情况下,静态优先级由进程的创建者指定,可以通过系统调用如 nice() 或 setpriority() 来设置。在 Linux 系统中,进程的静态优先级范围是从 -20(最高优先级)到 19(最低优先级),默认值为 0。
动态优先级则是指进程在运行时根据系统负载情况和进程运行状态等动态调整的优先级。在 Linux 系统中,动态优先级主要由 CFS 调度器进行控制,CFS 调度器使用一种称为虚拟运行时间(virtual runtime)的机制来计算进程的运行时间,并根据进程的虚拟运行时间来决定其动态优先级。当进程的虚拟运行时间越长时,其动态优先级就会越低,从而使得其他优先级更高的进程能够获得更多的 CPU 时间。
需要注意的是,静态优先级和动态优先级并不是相互独立的,而是相互影响的。在 CFS 调度器中,进程的静态优先级会被用来计算其初始的虚拟运行时间,从而影响其动态优先级的计算。因此,静态优先级越高的进程通常会获得更多的 CPU 时间,而动态优先级则可以在系统负载高峰时更加灵活地分配 CPU 时间,以保证系统的响应性能和公平性。
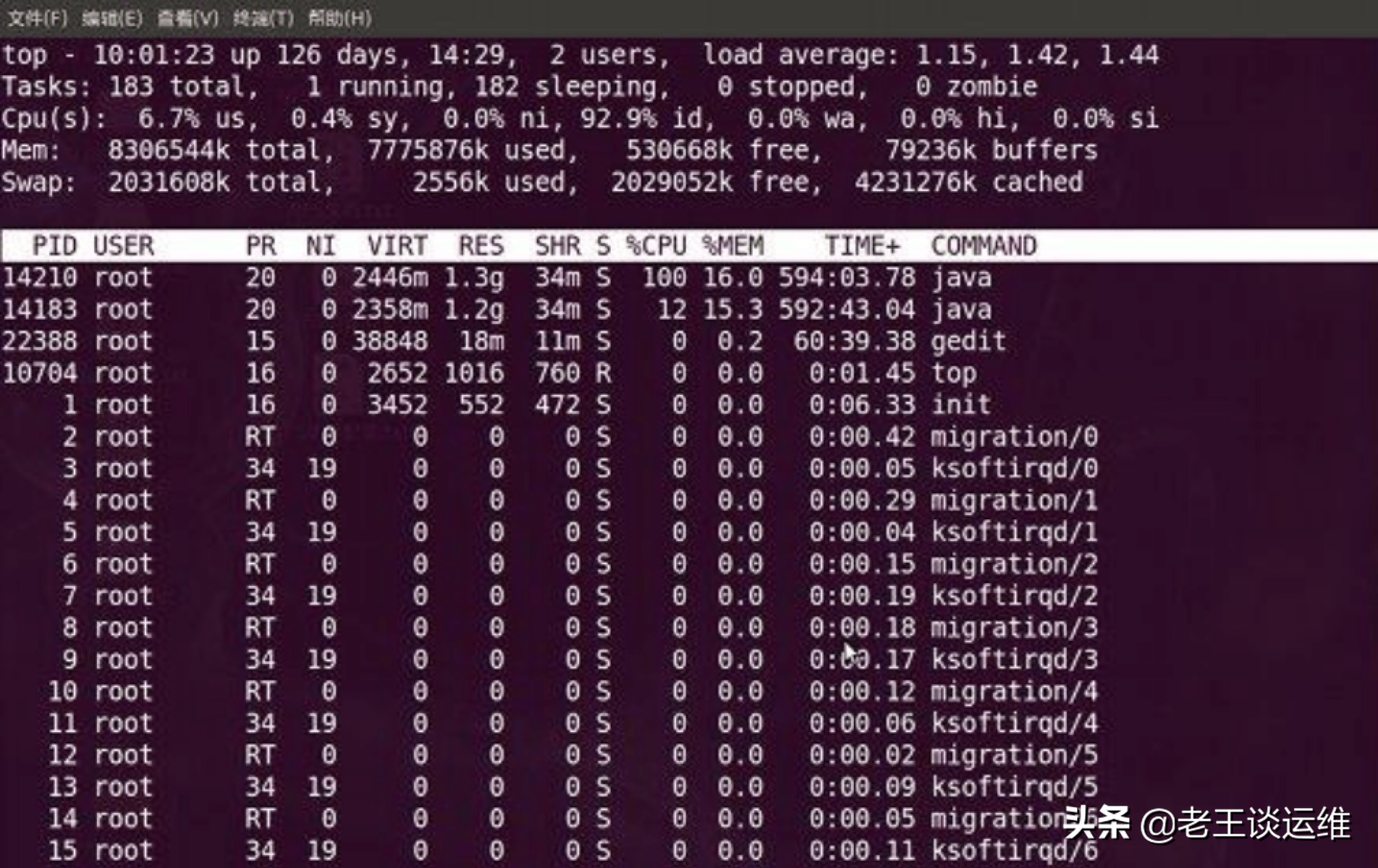
C++ 程序占cpu过高如何排查
1.定位程序
监控cpu运行状,显示进程运行信息列表:top -c
按CPU使用率排序,键入大写的P
此时知道了最高的进程的PID
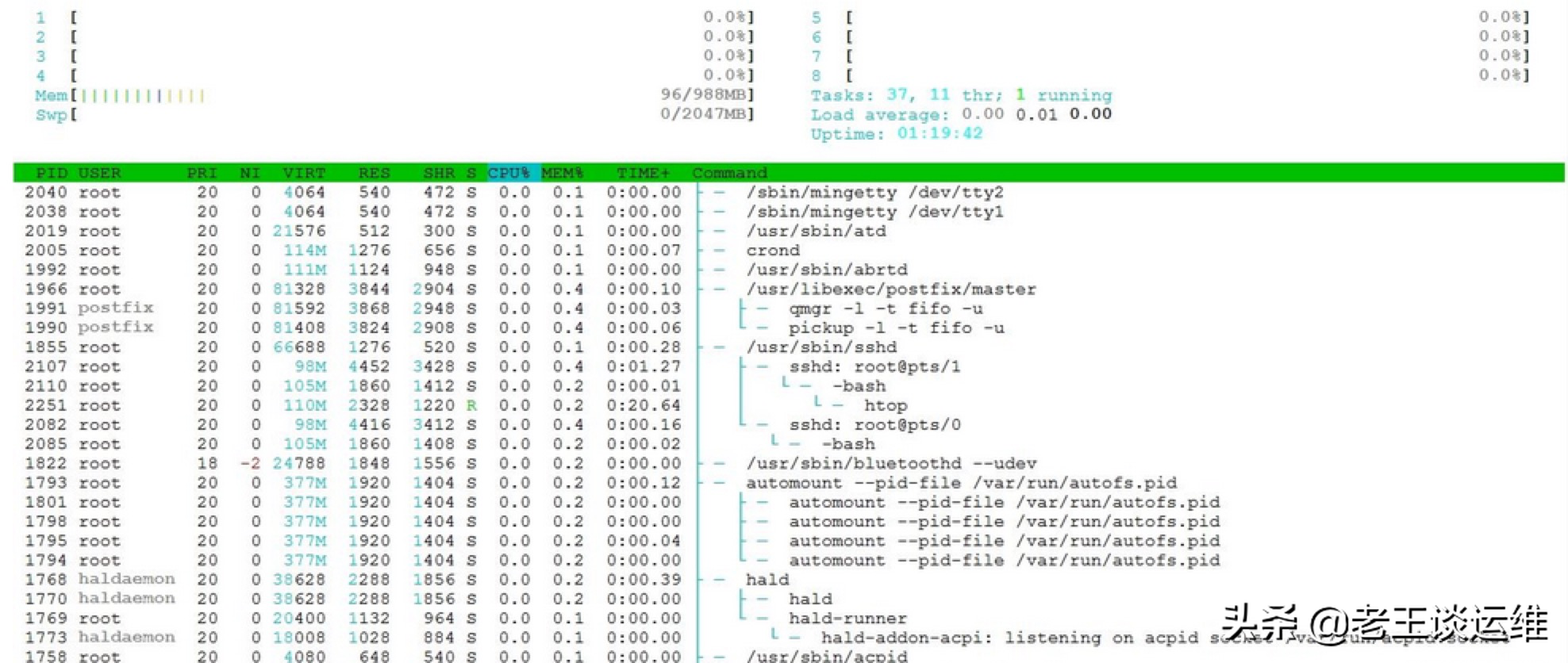
2.查看进程中线程的信息
top -Hp 进程号。 同样输入大写P,top的输出会按使用cpu多少排序,获取最高的那个线程号(H是线程模式)
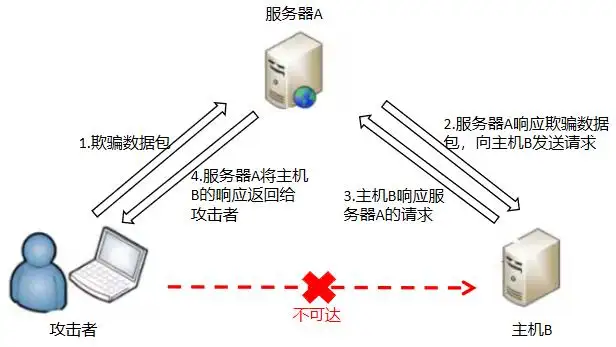
这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码: src=”http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory ”,并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 url 就会从 Bob 的浏览器发向银行,而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。这时,悲剧发生了,这个 url 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。等以后 Bob 发现账户钱少了,即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。而 Mallory 则可以拿到钱后逍遥法外。
Base = Basically Available + Soft state + Eventually consistent 基本可用性+软状态+最终一致性,由eBay架构师DanPritchett提出。Base是对CAP中一致性A和可用性C权衡的结果,源于提出者自己在大规模分布式系统上实践的总结。核心思想是无法做到强一致性,但每个应用都可以根据自身的特点,采用适当方式达到最终一致性。
传统的TPC/IP存在的问题主要是指I/O bottleneck瓶颈问题。在高速网络条件下与网络I/O相关的主机处理的高开销限制了可以在机器之间发送的带宽。这里感兴趣的高额开销是数据移动操作和复制操作。具体来讲,主要是传统的TCP/IP网络通信是通过内核发送消息。Messaging passing through kernel这种方式会导致很低的性能和很低的灵活性。性能低下的原因主要是由于网络通信通过内核传递,这种通信方式存在的很高的数据移动和数据复制的开销。并且现如今内存带宽性相较如CPU带宽和网络带宽有着很大的差异。很低的灵活性的原因主要是所有网络通信协议通过内核传递,这种方式很难去支持新的网络协议和新的消息通信协议以及发送和接收接口。
//我们想用一个函数封装write函数,比如logoinfo调用level1的write,并且还要能判断loglevel支不支持 //但函数封装变参函数,为了传递可变参数,实际上还要修改write的实现,不如用宏来实现,使用##__VA_ARGS__传递可变参数,让编译器把宏替换为真实的函数 //##__VA_ARGS__的优点是,对于宏调用,如果format是一个字符串也即后面没有可变参数,## 操作将使预处理器(preprocessor)去除掉它前面的那个逗号。 //宏与类无关了,这里必须isopen了才能使用 #define LOG_BASE(level, format, ...) \ do {\ Log* log = Log::instance();\ if (log->isopen() && log->getlevel() <= level) {\ log->write(level, format, ##__VA_ARGS__); \ }\ } while(0);
#define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0); #define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0); #define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0); #define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0);
intmain(){ int min = 0,max = 100; random_device seed;//硬件生成随机数种子 ranlux48 engine(seed());//利用种子生成随机数引擎 uniform_int_distribution<int> distrib(min, max);//设置随机数范围,并为均匀分布 int random = distrib(engine);//随机数 }
} clientState state = clientState::noLogin; string prompt = promptMap[state]; boolcheckCmd(int cmdvalue) { //最开始只考虑是否登录 if (cmdvalue == 0 || cmdvalue == 1) { if (state != clientState::noLogin) { cerr << "error> Have signed in yet!" << endl; returnfalse; } } else { if (state == clientState::noLogin) { cerr << "error> Not signed in yet!" << endl; returnfalse; } }
//如果正在等待,只允许break if (state == clientState::isWaiting && cmdvalue != 6) { cerr << "error> Only break or @break can input because you are waiting for something!" << endl; returnfalse; }
case2: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [search] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case3: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [chat] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input break or @break to back to command line..." << endl; break; }
case4: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [accept] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case5: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [reject] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case6: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [break] is wrong!" << endl; break; } else { //做处理 state = clientState::cmdLine; prompt = promptMap[state]; break; }
case7: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [send] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << " " << cmdvec[2] << endl; break; }
case8: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [sendfile] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case9: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptfile] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case10: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectfile] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case11: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [getfile] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case12: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptget] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case13: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectget] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case14: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsid] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case15: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsname] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case16: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [re] is wrong!" << endl; reflag = false;//虽然是re,但是命令有问题 break; } else//即使是错误命令也存,用户可能头铁...就想再试一次 { //做处理 if (!strcmp(cmdtmp, "no cmd"))//如果还没有命令 { cerr << "error> No command yet!" << endl; } else { cout << "reEX> " << cmdtmp;//不用换行,cmdtmp自然有个'\n' //strcpy已不可用,不指定长度不安全。使用strlen要+1,因为长度不包含结束符,要补上去 strcpy_s(cmdbuf, strlen(cmdtmp) + 1, cmdtmp); reflag = true;//表明不必把cmdbuf置零 } break; }
case17: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [exit] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << endl; break; }
case18: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [hisir] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case20: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [oyasumi] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
} clientState state = clientState::noLogin; string prompt = promptMap[state]; boolcheckCmd(int cmdvalue) { //最开始只考虑是否登录 if (cmdvalue == 0 || cmdvalue == 1) { if (state != clientState::noLogin) { cerr << "error> Have signed in yet!" << endl; returnfalse; } } else { if (state == clientState::noLogin) { cerr << "error> Not signed in yet!" << endl; returnfalse; } } //如果正在chatting,不允许再chat if (state == clientState::isChatting && cmdvalue == 3) { cerr << "error> You are chatting with "<<chatSname<<"! You can break to chat with other." << endl; returnfalse; } //如果正在等待,只允许break if (state == clientState::isWaiting && cmdvalue != 6) { cerr << "error> Only break or @break can input because you are waiting for something!" << endl; returnfalse; }
case2: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [search] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case3: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [chat] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input break or @break to back to command line..." << endl;
case4: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [accept] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case5: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [reject] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case6: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [break] is wrong!" << endl; break; } else { //做处理 state = clientState::cmdLine; prompt = promptMap[state]; break; }
case7: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [send] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << " " << cmdvec[2] << endl; break; }
case8: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [sendfile] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case9: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptfile] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case10: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectfile] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case11: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [getfile] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case12: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptget] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case13: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectget] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case14: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsid] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case15: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsname] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case16: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [re] is wrong!" << endl; reflag = false;//虽然是re,但是命令有问题 break; } else//即使是错误命令也存,用户可能头铁...就想再试一次 { //做处理 if (!strcmp(cmdtmp, "no cmd"))//如果还没有命令 { cerr << "error> No command yet!" << endl; } else { cout << "reEX> " << cmdtmp;//不用换行,cmdtmp自然有个'\n' //strcpy已不可用,不指定长度不安全。使用strlen要+1,因为长度不包含结束符,要补上去 strcpy_s(cmdbuf, strlen(cmdtmp) + 1, cmdtmp); reflag = true;//表明不必把cmdbuf置零 } break; }
case17: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [exit] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << endl; break; }
case18: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [hisir] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case20: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [oyasumi] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
} clientState state = clientState::noLogin; string prompt = promptMap[state]; boolcheckCmd(int cmdvalue) { //最开始只考虑是否登录 if (cmdvalue == 0 || cmdvalue == 1) { if (state != clientState::noLogin) { cerr << "error> Have signed in yet!" << endl; returnfalse; } } else { if (state == clientState::noLogin) { cerr << "error> Not signed in yet!" << endl; returnfalse; } } //如果正在chatting,不允许再chat if (state == clientState::isChatting && cmdvalue == 3) { cerr << "error> You are chatting with " << chatSname << "! You can break to chat with other." << endl; returnfalse; }
//如果正在等待,只允许break if (state == clientState::isWaiting && cmdvalue != 6) { cerr << "error> Only break or @break can input because you are waiting for something!" << endl; returnfalse; }
case2: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [search] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case3: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [chat] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input break or @break to back to command line..." << endl;
case4: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [accept] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case5: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [reject] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case6: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [break] is wrong!" << endl; break; } else { //做处理 state = clientState::cmdLine; prompt = promptMap[state]; break; }
case7: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [send] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << " " << cmdvec[2] << endl; break; }
case8: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [sendfile] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case9: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptfile] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case10: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectfile] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case11: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [getfile] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case12: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptget] is wrong!" << endl; break; } else { //做处理 //send...waiting state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case13: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectget] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case14: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsid] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case15: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsname] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case16: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [re] is wrong!" << endl; reflag = false;//虽然是re,但是命令有问题 break; } else//即使是错误命令也存,用户可能头铁...就想再试一次 { //做处理 if (!strcmp(cmdtmp, "no cmd"))//如果还没有命令 { cerr << "error> No command yet!" << endl; } else { cout << "reEX> " << cmdtmp;//不用换行,cmdtmp自然有个'\n' //strcpy已不可用,不指定长度不安全。使用strlen要+1,因为长度不包含结束符,要补上去 strcpy_s(cmdbuf, strlen(cmdtmp) + 1, cmdtmp); reflag = true;//表明不必把cmdbuf置零 } break; }
case17: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [exit] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << endl; break; }
case18: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [hisir] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case20: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [oyasumi] is wrong!" << endl; break; } else { //做处理 cout << "test> " << cmdvec[0] << " " << cmdvec[1] << endl; break; }
case2: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [search] is wrong!" << endl; break; } else { //做处理 //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 if(strcmp(recvbuf, "faliure")==0) { cout << "sid does not exist!" << endl; } else { cout << recvbuf <<endl; } break; }
case3: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [chat] is wrong!" << endl; break; } else { //做处理 //send...waiting //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; chattarg = cmdvec[1]; cout << "waiting> Waiting for a response, you can input break or @break to back to command line..." << endl; //响应在接收线程处理! /* Sleep(3000);//阻塞3秒,假装等待连接 state = clientState::isChatting; //chatSname = ... prompt = promptMap[state] + chatSname + "> "; */ break; }
case4: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [accept] is wrong!" << endl; break; } else { //做处理 //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 break; }
case5: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [reject] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 break; }
case6: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [break] is wrong!" << endl; break; } else { //做处理,break也需要发送,这样服务器才能知道用户从某请求的等待中退出了 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 state = clientState::cmdLine; prompt = promptMap[state]; break; }
case7: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [send] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 break; }
case8: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [sendfile] is wrong!" << endl; break; } else { //做处理 //send...waiting //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case9: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptfile] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 //...还需要用一个线程来接收,文件名通过请求表维护 break; }
case10: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectfile] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 break; }
case11: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [getfile] is wrong!" << endl; break; } else { //做处理 //send...waiting //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case12: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptget] is wrong!" << endl; break; } else { //做处理 //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 break; }
case13: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectget] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 break; }
case14: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsid] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 //需要接收响应,因为sid是全局唯一的,可能设置失败! recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf <<endl; break; }
case15: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsname] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 //这里接收响应是为了增加用户体验,服务器返回一个成功信息 //因为设置相对频率较少,这不是什么很大的负担 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf <<endl; break; }
case16: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [re] is wrong!" << endl; reflag = false;//虽然是re,但是命令有问题 break; } else//即使是错误命令也存,用户可能头铁...就想再试一次 { //做处理 if (!strcmp(cmdtmp, "no cmd"))//如果还没有命令 { cerr << "error> No command yet!" << endl; } else { cout << "reEX> " << cmdtmp;//不用换行,cmdtmp自然有个'\n' //strcpy已不可用,不指定长度不安全。使用strlen要+1,因为长度不包含结束符,要补上去 strcpy_s(cmdbuf, strlen(cmdtmp) + 1, cmdtmp); reflag = true;//表明不必把cmdbuf置零 } break; }
case17: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [exit] is wrong!" << endl; break; } else { //做处理,或许需要告知服务器退出,先这样 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 exitflag = true; cout << "The client now exits!" <<endl; break; }
case18: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [hisir] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf <<endl; break; }
case20: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [oyasumi] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()),0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf <<endl; exitflag = true; break; }
} clientState state = clientState::noLogin; string prompt = promptMap[state]; string chattarg = ""; bool chooseflag = false; boolcheckCmd(int cmdvalue) { //最开始只考虑是否登录 if (cmdvalue == 0 || cmdvalue == 1) { if (state != clientState::noLogin) { cerr << "error> Have signed in yet!" << endl; returnfalse; } } else { if (state == clientState::noLogin) { cerr << "error> Not signed in yet!" << endl; returnfalse; } } //如果正在chatting,不允许再chat if (state == clientState::isChatting && cmdvalue == 3) { cerr << "error> You are chatting with " << chatSname << "! You can break to chat with other." << endl; returnfalse; }
//如果正在等待,只允许break if (state == clientState::isWaiting && cmdvalue != 6) { cerr << "error> Only break or @break can input because you are waiting for something!" << endl; returnfalse; }
returntrue; }
boolisNumber(constchar* buf)//判断字符传是否为数字 { for (int i = 0; buf[i] != '\n'; i++)//以\n结尾 if (buf[i] < '0' || buf[i]>'9')//每个字符都要是数字 returnfalse; returntrue; }
voidrun(SOCKET connfd) { //一个汉字两字节,可能需要更大的buf char cmdbuf[256]; char cmdtmp[256] = "no cmd"; char recvbuf[256]; bool reflag = false; bool exitflag = false;//函数退出信号 cout << prompt << flush; //根据bool或运算顺序,如果用上一次的结果(reflag==true),就不接收字符 while (reflag || fgets(cmdbuf, sizeof(cmdbuf), stdin) != NULL)//gets已不被编译器支持,不太安全 { if (chooseflag)//如果在选择文件。接收线程会把这个flag改成true,并且打印提示符enter file number> { if (isNumber(cmdbuf)) { //要进行数字的范围判断,用stoi int num = stoi(cmdbuf); if (num > fileNumber || num < 1) { cerr << "Please enter a number in the range!" << endl; memset(cmdbuf, 0, sizeof(cmdbuf)); cout << prompt << flush; continue; } send(connfd, cmdbuf, sizeof(cmdbuf), 0);//发送 memset(cmdbuf, 0, sizeof(cmdbuf)); //...还需要用一个线程来接收
case2: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [search] is wrong!" << endl; break; } else { //做处理 //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 if (strcmp(recvbuf, "faliure") == 0) { cout << "sid does not exist!" << endl; } else { cout << recvbuf << endl; } break; }
case3: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [chat] is wrong!" << endl; break; } else { //做处理 //send...waiting //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送
state = clientState::isWaiting; prompt = promptMap[state]; chattarg = cmdvec[1]; cout << "waiting> Waiting for a response, you can input break or @break to back to command line..." << endl;
case4: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [accept] is wrong!" << endl; break; } else { //做处理 //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case5: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [reject] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case6: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [break] is wrong!" << endl; break; } else { //做处理,break也需要发送,这样服务器才能知道用户从某请求的等待中退出了 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 state = clientState::cmdLine; prompt = promptMap[state]; break; }
case7: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [send] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case8: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [sendfile] is wrong!" << endl; break; } else { //做处理 //send...waiting //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case9: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptfile] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 //...还需要用一个线程来接收,文件名通过请求表维护 break; }
case10: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectfile] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case11: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [getfile] is wrong!" << endl; break; } else { //做处理 //send...waiting //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case12: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptget] is wrong!" << endl; break; } else { //做处理 //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case13: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectget] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case14: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsid] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 //需要接收响应,因为sid是全局唯一的,可能设置失败! recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; break; }
case15: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsname] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 //这里接收响应是为了增加用户体验,服务器返回一个成功信息 //因为设置相对频率较少,这不是什么很大的负担 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; break; }
case16: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [re] is wrong!" << endl; reflag = false;//虽然是re,但是命令有问题 break; } else//即使是错误命令也存,用户可能头铁...就想再试一次 { //做处理 if (!strcmp(cmdtmp, "no cmd"))//如果还没有命令 { cerr << "error> No command yet!" << endl; } else { cout << "reEX> " << cmdtmp;//不用换行,cmdtmp自然有个'\n' //strcpy已不可用,不指定长度不安全。使用strlen要+1,因为长度不包含结束符,要补上去 strcpy_s(cmdbuf, strlen(cmdtmp) + 1, cmdtmp); reflag = true;//表明不必把cmdbuf置零 } break; }
case17: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [exit] is wrong!" << endl; break; } else { //做处理,或许需要告知服务器退出,先这样 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 exitflag = true; cout << "The client now exits!" << endl; break; }
case18: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [hisir] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; break; }
case20: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [oyasumi] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; exitflag = true; break; }
当用户在waiting状态下break,服务器标记用户回到cmdLine,而对方还没有接收到这个消息就accept了,由于用户已经回到cmdLine状态了,这个accept是失效的,因此服务器通过cmdLine状态得知这一事件,向accept一方发回一个@#break now,让其退回命令行状态(如果是chatting的话)并打印”the peers break before you accept”。如果是reject就不管
当用户在waiting状态下break,服务器还没标记用户回到cmdLine,对方就发了accept,此时由于服务器发现用户还在waiting,就把accept转过去了,但用户已经回到命令行了。在接收线程里,如果用户不在等待状态则accept是无效的,因此只用考虑向accept发送处理。服务器把accept转过去后,标记的用户的状态要么返回cmdLine(sendfile这些被accept就标记为cmdLine),要么进入chatting状态。然后服务器又收到break信息,前面说到在chatting状态收到break,服务器发一个@#break now。则如果accept方目前在chatting,也可以退出;否则用户应该在cmdLine状态,这样收到@#break now,给accept方打印一个信息”the peers break before you accept”。
case2: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [search] is wrong!" << endl; break; } else { //做处理 //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 if (strcmp(recvbuf, "faliure") == 0) { cout << "sid does not exist!" << endl; } else { cout << recvbuf << endl; } break; }
case3: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [chat] is wrong!" << endl; break; } else { //做处理 //send...waiting //发送cmdstr就不用做头尾空格去除 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送
state = clientState::isWaiting; prompt = promptMap[state]; chattarg = cmdvec[1]; cout << "waiting> Waiting for a response, you can input break or @break to back to command line..." << endl;
case4: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [accept] is wrong!" << endl; break; } else { //做处理 //发送cmdstr就不用做头尾空格去除 if(reqTable.checkReq(cmdvec[1]) == "chat") { send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 reqTable.deleteReq(cmdvec[1]); } else cerr << "error> "<<cmdvec[1]<<" did not send a chat request!" << endl; break; }
case5: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [reject] is wrong!" << endl; break; } else { //做处理 if(reqTable.checkReq(cmdvec[1]) == "chat") { send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 reqTable.deleteReq(cmdvec[1]); } else cerr << "error> "<<cmdvec[1]<<" did not send a chat request!" << endl; break; }
case6: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [break] is wrong!" << endl; break; } else { //做处理,break也需要发送,这样服务器才能知道用户从某请求的等待中退出了 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 state = clientState::cmdLine; prompt = promptMap[state]; break; }
case7: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [send] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 break; }
case8: if (cmdvec.size() != 3) { cerr << "error> The number of parameters for [sendfile] is wrong!" << endl; break; } else { //做处理 //send...waiting //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case9: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptfile] is wrong!" << endl; break; } else { //做处理 if(reqTable.checkReq(cmdvec[1]) == "sendfile") { send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 reqTable.deleteReq(cmdvec[1]); string filename = reqTable.getName(); //...还需要用一个线程来接收,文件名通过请求表维护 } else cerr << "error> "<<cmdvec[1]<<" did not send a sendfile request!" << endl; break; }
case10: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectfile] is wrong!" << endl; break; } else { //做处理 if(reqTable.checkReq(cmdvec[1]) == "sendfile") { send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 reqTable.deleteReq(cmdvec[1]); } else cerr << "error> "<<cmdvec[1]<<" did not send a sendfile request!" << endl; break; }
case11: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [getfile] is wrong!" << endl; break; } else { //做处理 //send...waiting //响应在接收线程处理! send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 state = clientState::isWaiting; prompt = promptMap[state]; cout << "waiting> Waiting for a response, you can input @break to back to command line..." << endl; break; }
case12: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [acceptget] is wrong!" << endl; break; } else { //做处理 //响应在接收线程处理! if(reqTable.checkReq(cmdvec[1]) == "getfile") { //还要发资源列表 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 reqTable.deleteReq(cmdvec[1]); } else cerr << "error> "<<cmdvec[1]<<" did not send a getfile request!" << endl; break; }
case13: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [rejectget] is wrong!" << endl; break; } else { //做处理 if(reqTable.checkReq(cmdvec[1]) == "getfile") { send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 reqTable.deleteReq(cmdvec[1]); } else cerr << "error> "<<cmdvec[1]<<" did not send a getfile request!" << endl; break; }
case14: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsid] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 //需要接收响应,因为sid是全局唯一的,可能设置失败! recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; break; }
case15: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [setsname] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 //这里接收响应是为了增加用户体验,服务器返回一个成功信息 //因为设置相对频率较少,这不是什么很大的负担 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; break; }
case16: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [re] is wrong!" << endl; reflag = false;//虽然是re,但是命令有问题 break; } else//即使是错误命令也存,用户可能头铁...就想再试一次 { //做处理 if (!strcmp(cmdtmp, "no cmd"))//如果还没有命令 { cerr << "error> No command yet!" << endl; } else { cout << "reEX> " << cmdtmp;//不用换行,cmdtmp自然有个'\n' //strcpy已不可用,不指定长度不安全。使用strlen要+1,因为长度不包含结束符,要补上去 strcpy_s(cmdbuf, strlen(cmdtmp) + 1, cmdtmp); reflag = true;//表明不必把cmdbuf置零 } break; }
case17: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [exit] is wrong!" << endl; break; } else { //做处理,或许需要告知服务器退出,先这样 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 exitflag = true; cout << "The client now exits!" << endl; break; }
case18: if (cmdvec.size() != 2) { cerr << "error> The number of parameters for [hisir] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; break; }
case20: if (cmdvec.size() != 1) { cerr << "error> The number of parameters for [oyasumi] is wrong!" << endl; break; } else { //做处理 send(connfd, cmdstr.c_str(), int(cmdstr.size()), 0);//发送 recv(connfd, recvbuf, sizeof(recvbuf), 0);//同步接收,是阻塞的 cout << recvbuf << endl; exitflag = true; break; }
/* * The headers are converted to a string to send * The maximum number of digits in 32-bit decimal is 10 digits: 4,294,967,296 * The maximum number of digits in 64-bit decimal is 20 digits: 18,446,744,073,709,551,616 * The maximum number of digits in 16-bit decimal is 5 digits: 65,536 * There are 8 bits of identification * There are also 6 spaces */ int MyUdpSeg::maxHeadSize = 10 + 20 + 20 + 5 + 5 + 8 + 6;
//Constructor 1: Construct class objects based on data MyUdpSeg::MyUdpSeg(constchar* buf, num_type Number, off_type Offset, len_type Length, tag_type Tag, win_type Window, id_type Id) : data(buf), number(Number), offset(Offset), window(Window), length(Length), id(Id), tag(Tag) {}
//Constructor 2: Construct class objects based on the complete UDP packet segment(string) MyUdpSeg::MyUdpSeg(string& udpSeg) { vector<string> vec = parse(udpSeg); // error packet segment if (vec.size() < 6) { length = 0; //Indicates that this is a useless package return; } /* * have not string to unsigned int or size_t function * but string to unsigned long is satisfiable * just make sure it doesn't overflow * use forced transformation to ignore warnings */ number = num_type(stoul(vec[0])); offset = off_type(stoul(vec[1])); window = win_type(stoul(vec[2])); length = len_type(stoul(vec[3])); id = id_type(stoul(vec[4])); tag = tag_type(vec[5]); if (vec.size() > 6) //if arry data. ACK may not carry data data = vec[6]; }
//Constructor 3: Retransmit, adjust the number MyUdpSeg::MyUdpSeg(MyUdpSeg& udpSeg, num_type Number) : data(udpSeg.data), number(Number), offset(udpSeg.offset), window(udpSeg.window), length(udpSeg.length), id(udpSeg.id), tag(udpSeg.tag) {}
//parse the string vector<string> MyUdpSeg::parse(string& str) { //Note that there are also spaces in the data, so parse up to six times //Data should not be sliced int spaceNum = 6;
str = str + " "; //add an space vector<string> res; size_t pos = 0; size_t pos1; while ((pos1 = str.find(' ', pos)) != string::npos) { if (spaceNum-- == 0) break;
res.push_back(str.substr(pos, pos1 - pos)); while (str[pos1] == ' ') pos1++; pos = pos1; } //Get complete data string data = str.substr(pos); if (data != "") res.push_back(data);
return res; //move construction }
//convert to string to send data string MyUdpSeg::seg_to_string() { string res; res += to_string(number) + " "; res += to_string(offset) + " "; res += to_string(window) + " "; res += to_string(length) + " "; res += to_string(id) + " "; res += tag.to_string() + " "; //std::bitset::to_string() res += data; return res; }
structtimerNode { MyUdpSeg::num_type number; //segment number MyUdpSeg::off_type offset; //data offset chrono::system_clock::time_point time; //start time bool timeout; //timeout flag timerNode(MyUdpSeg::num_type Number, MyUdpSeg::off_type Offset) : number(Number), offset(Offset),time(chrono::system_clock::now()), timeout(false) {} timerNode(const timerNode& node) : number(node.number), offset(node.offset),time(node.time), timeout(false) {} booloperator==(MyUdpSeg::num_type Number) { return number == Number; } //for find() function or remove() };
classTimerList { public: using node_type = timerNode; using rtt_type = unsignedint; using rto_type = double; using timerIter = list<node_type>::iterator; private: list<node_type> timerList; public: TimerList(){} ~TimerList(){} //insert by node voidinsertTimer(const node_type& node); //insert by number voidinsertTimer(MyUdpSeg::num_type Number, MyUdpSeg::off_type Offset);
//delete by number, return RTT/ms rtt_type deleteTimer(MyUdpSeg::num_type Number);
//deal with timeout packets, return numbers vector<MyUdpSeg::num_type> tick(rto_type RTO);
//return size size_tsize(){ return timerList.size(); } private: //delete all by offset, call by "rtt_type deleteTimer(MyUdpSeg::num_type Number);" voiddeleteTimer_(MyUdpSeg::off_type Offset); };
voidTimerList::insertTimer(const node_type& node) { timerList.push_back(node); // call move or copy constructor function, not need to construct } voidTimerList::insertTimer(MyUdpSeg::num_type Number, MyUdpSeg::off_type Offset) { timerList.emplace_back(Number, Offset); //call constructor function }
TimerList::rtt_type TimerList::deleteTimer(MyUdpSeg::num_type Number) { //find the node timerIter iter = find(timerList.begin(), timerList.end(), Number); //O(n) if (iter == timerList.end()) //not found return0; //zero used to error detect
//delete node with the same offset deleteTimer_(offset);
return RTT; }
voidTimerList::deleteTimer_(MyUdpSeg::off_type Offset) { for (timerIter iter = timerList.begin(); iter != timerList.end();) { if ((*iter).offset == Offset) iter = timerList.erase(iter); //erase return next iterator else iter++; } }
vector<MyUdpSeg::num_type> TimerList::tick(rto_type RTO) { if (RTO <= 0) return{};
vector<MyUdpSeg::num_type> number_retrans; for (timerIter iter = timerList.begin(); iter != timerList.end(); iter++) { if ((*iter).timeout == true) continue; else { chrono::system_clock::time_point nowtime = chrono::system_clock::now(); rtt_type interval = rtt_type(chrono::duration_cast<chrono::milliseconds>(nowtime - (*iter).time).count()); if (interval > RTO) //need to retransmit { number_retrans.push_back((*iter).number); (*iter).timeout = true; } } } return number_retrans; }
//lambda for remove_if auto pred_lambda = [](bufferNode& bufNode, MyUdpSeg::off_type offset) -> bool// "-> bool" is omittable { return bufNode.udpSeg.getOffset() == offset; }; auto pred = bind(pred_lambda,std::placeholders::_1, myOffset);
//the simplified form is as follows auto pred = bind([](bufferNode& bufNode, MyUdpSeg::off_type offset) { //lambda return bufNode.udpSeg.getOffset() == offset; }, placeholders::_1, myOffset); //parameters
classBufferList { public: using node_type = bufferNode; using bufferIter = list<node_type>::iterator; using node_return_type = pair<node_type&, bool>; private: list<node_type> bufferList; public: BufferList(){} ~BufferList(){}
//insert node voidinsertNode(MyUdpSeg& UdpSeg); voidinsertNode(MyUdpSeg&& UdpSeg); voidinsertNode(MyUdpSeg& UdpSeg, MyUdpSeg::num_type Number); voidsortInsertNode(MyUdpSeg& UdpSeg); //insert sorted by offset(used by recvbuf)
//delete by number voiddeleteNode(MyUdpSeg::num_type Number);
//get node by number, return pair: reference、bool (to check node) node_return_type getNode(MyUdpSeg::num_type Number); /* * Note for getNode function: * For each return value, initialize it with a new variable * Do not assign a value to pair again after initialization, it will act on the initialized node */