前言 看完了webserver的c++11(14)的写法并添加了大量注释后,也要开始自己手写一个了。整体的逻辑还没有研究透彻,虽然在写完注释后对思路已经挺清楚了,但是细节上还是很欠缺。
这一篇博客是为动手撸一个服务器而准备的,在这篇博客里,会动手写一些基本的模块,并进行正确性验证。
变量命名没有很规范,因为有时想随意一点,有时又觉得想认真点,(●’◡’●)
环境:ubuntu20.04,c++11及以上(14更好,c++11的话编译器会对lambda表达式按值捕获发出警告,尽管代码还是能正确运行)
线程池 线程池是最简单的,就先从这入手。
考虑整体的思路:
首先有一个池初始化若干个线程,每个线程配备一个运行的work函数,这个work函数要循环取任务去执行。
取任务就有个任务队列,在设计任务队列前,我们想一下任务的形式是什么,要传什么样的什么类型的任务进来。
一种选择是传入一个类对象,然后调用类对象的一些工作处理函数,并且还能根据类对象的一些参数来进行不同的处理。
上面的方式也许是传统的c98的模式,它并不是那么的具有鲁棒性,因为尽管可以通过模板传入不同的类对象,但是类对象必须拥有一个处理函数。如果只是运行这些处理函数,为什么不直接传入一个函数进来呢,这样就可以执行任意的工作了。
c++11开始,std::function<>就提供了我们想要的功能,无论是函数指针还是函数对象等,都可以使用一个function对象保存然后传入。而那些细节处理交由上层,函数执行所需要的参数由std::bind来绑定给function对象,function本身不需要额外参数,更有灵活性。
因此,我们的任务队列的元素就是std::function。然后,在取队列元素时和加入队列元素时,都需要互斥。队列是一个无界生产者,当队列大小为0时,一般用一个信号量阻塞即可,但我们也知道可以用条件变量来完成这件事,因此这里会用条件变量。
在取任务时,首先互斥锁住(判断是否非空前就要锁),然后如果队列非空就取一个任务,解锁,执行任务。如果没有任务,就阻塞,这里用条件变量阻塞。因为要锁和解锁以及给条件变量使用,所以用unique_lock好,但unique_lock不要写在while内,这样会重复定义。
这里先不考虑左值右值,因为本身项目中就不需要用到,从理论上讲考虑的话就更灵活,但没有实例还是不好理解,就先不用了。
现在,我们可以开始写代码了,这里提一下头文件(注意标准库一般都是std命名空间):
1 2 3 4 5 <mutex>:互斥锁等 <thread>:线程 <condition_variable>:条件变量 <functional>:std::function <queue>:队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #ifndef THREADPOOL_H #define THREADPOOL_H #include <mutex> #include <thread> #include <condition_variable> #include <functional> #include <queue> #include <cassert> class threadpool { private : std::mutex mtx; std::queue<std::function<void ()>> taskQueue; std::condition_variable cond; public : threadpool (int threadnum = 8 ) { assert (threadnum > 0 ); for (int i=0 ;i<threadnum;i++) std::thread ([&]{ std::unique_lock<std::mutex> locker (mtx); while (true ) { if (!taskQueue.empty ()) { auto task = taskQueue.front (); taskQueue.pop (); locker.unlock (); task (); locker.lock (); } else cond.wait (locker); } }).detach (); } void addTask (std::function<void ()> task) { std::lock_guard<std::mutex> locker (mtx) ; taskQueue.emplace (task); cond.notify_one (); } ~threadpool () { } }; #endif
上面的版本基本上已经写好了一个线程池,但还有析构函数没有写。析构函数要析构什么呢,这里好像并没有要手动释放的东西——没有手动使用堆空间,不需要delete。但别忘了,我们的线程是分离的,这里没有去join回收,线程使用的全局变量会产生所谓的detch陷阱。
当进程要退出时,不会再添加任务了,我们更希望线程把这些已有任务都做完再退出,但是主进程退出了会把队列、互斥锁、条件变量都析构掉,使得线程调用这些资源会出错,这就是detch()带来的陷阱。在讨论解决方案前,我们再想想为什么要使用detch():其实就是为了把已有的任务都做完。
为了做完这些任务,我们就得把线程访问的资源放在堆空间上,这样才不会在进程退出时析构掉资源。因为每个线程都访问这三个资源,因此再用一个结构体封装,线程捕获结构体指针就可以了。为了控制堆上的资源,我们还可以使用共享指针(共享很显然,因为这些线程用的是同一个)。
创建共享指针的方式有两种,一种是用new,一种是用make_shared函数。尽量使用make_shared,因为new本质上会分配两次内存,一个是new的对象,一个是shared_ptr本身new的计数器(控制块)。而使用make_shared申请一个单独的内存块来存放对象和控制块,更高效,且因为没有顺序是同一时间开辟空间的,具有异常安全。C++11 make_shared - 简书 (jianshu.com)
使用make_shared函数要显式指出类型,因为返回值是shared_ptr<T>,返回值类型无法推导,要make_shared<T>指出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #ifndef THREADPOOL_H #define THREADPOOL_H #include <mutex> #include <thread> #include <condition_variable> #include <functional> #include <queue> #include <cassert> class threadpool { private : struct pool { std::mutex mtx; std::queue<std::function<void ()>> taskQueue; std::condition_variable cond; }; std::shared_ptr<pool> pool_; public : threadpool (int threadnum = 8 ):pool_ (std::make_shared <pool>()) { assert (threadnum > 0 ); for (int i=0 ;i<threadnum;i++) std::thread ([pool_t = pool_]{ std::unique_lock<std::mutex> locker (pool_t ->mtx); while (true ) { if (!pool_t ->taskQueue.empty ()) { auto task = pool_t ->taskQueue.front (); pool_t ->taskQueue.pop (); locker.unlock (); task (); locker.lock (); } else pool_t ->cond.wait (locker); } }).detach (); } void addTask (std::function<void ()> task) { std::lock_guard<std::mutex> locker (pool_->mtx) ; pool_->taskQueue.emplace (task); pool_->cond.notify_one (); } ~threadpool () { } }; #endif
现在,我们已经解决了detach陷进,只要线程执行完任务,我们就退出线程,那么我们的析构函数只需要传递一个信号,让线程得知主进程已经退出了,线程根据信号作出反应即可。注意,因为线程要把工作做完再退出,所以优先级是!empty(),如果没有任务,我们是先看要不要退出,再进行等待,所以在if-else中插入一个else if判断即可。
注意,线程有可能卡在条件变量的wait处,所以析构函数还要唤醒所有的线程,让它们处理任务(如果有)并退出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #ifndef THREADPOOL_H #define THREADPOOL_H #include <mutex> #include <thread> #include <condition_variable> #include <functional> #include <queue> #include <cassert> class threadpool { private : struct pool { std::mutex mtx; std::queue<std::function<void ()>> taskQueue; std::condition_variable cond; bool isclose = false ; }; std::shared_ptr<pool> pool_; public : threadpool (int threadnum = 8 ):pool_ (std::make_shared <pool>()) { assert (threadnum > 0 ); for (int i=0 ;i<threadnum;i++) std::thread ([pool_t = pool_]{ std::unique_lock<std::mutex> locker (pool_t ->mtx); while (true ) { if (!pool_t ->taskQueue.empty ()) { auto task = pool_t ->taskQueue.front (); pool_t ->taskQueue.pop (); locker.unlock (); task (); locker.lock (); } else if (pool_t ->isclose) break ; else pool_t ->cond.wait (locker); } }).detach (); } void addTask (std::function<void ()> task) { std::lock_guard<std::mutex> locker (pool_->mtx) ; pool_->taskQueue.emplace (task); pool_->cond.notify_one (); } ~threadpool () { pool_->isclose = true ; pool_->cond.notify_all (); } }; #endif
test 以上基本就大功告成了,现在,我们来写一个test文件。
为了确认线程是否正确退出,我们在else if那打印退出信息:
1 2 3 4 else if (pool_t ->isclose){ std::cout<<"thread exit!" <<std::endl; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include "threadpool.h" #include <unistd.h> #include <iostraem> #include <pthread.h> using namespace std;void task (int id) cout<<"this is [" <<id<<"] task" <<endl; sleep (id); cout<<"[" <<id<<"] task quit!" <<endl; } int main () threadpool threadp (10 ) ; for (int i=5 ;i<20 ;i++) threadp.addTask (bind (task,i)); pthread_exit (NULL ); return 0 ; }
注意std::thread内部调用了pthread,linux不一定把pthread作为默认库,所以编译时候要链接,编译的命令为:
1 g++ -std=c++14 -o test_threadpool test_threadpool.cpp -lpthread
再者,当主进程return后,即使子线程是detch的,也会被系统回收资源。在 《UNIX 网络编程》卷一 第 537 页,有这么一句话:
1 如果进程的main函数返回或者任何线程调用了 exit, 整个进程就终止,其中包括它的任何线程。
程序return,间接调用了exit()函数,因为一个线程调用exit函数,导致整个进程的退出。要想系统并不回收进程的所有资源,可以调用pthread_exit();然后等其他线程终止退出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 sun2@ubuntu:~/Desktop/websever_test$ g++ -std=c++14 -o test_threadpool test_threadpool.cpp -lpthread sun2@ubuntu:~/Desktop/websever_test$ ./test_threadpool this is [5 ] taskthis is [6 ] taskthis is [7 ] taskthis is [8 ] taskthis is [9 ] taskthis is [10 ] taskthis is [11 ] taskthis is [12 ] taskthis is [13 ] taskthis is [14 ] task[5 ] task quit! this is [15 ] task[6 ] task quit! this is [16 ] task[7 ] task quit! this is [17 ] task[8 ] task quit! this is [18 ] task[9 ] task quit! this is [19 ] task[10 ] task quit! thread exit! [11 ] task quit! thread exit! [12 ] task quit! thread exit! [13 ] task quit! thread exit! [14 ] task quit! thread exit! [15 ] task quit! thread exit! [16 ] task quit! thread exit! [17 ] task quit! thread exit! [18 ] task quit! thread exit! [19 ] task quit! thread exit!
日志系统 这一块比较复杂,分解知识点,一点点细学。
时间类chrono 这个在日志系统用了一点,不过也可以用来输出时间,就在这里学习了。
Duration 1 2 3 4 template <class Rep , class Period = std::ratio<1 >> class duration;template <std::intmax_t Num, std::intmax_t Denom = 1 > class ratio;
ratio表示每个时钟周期的秒数,其中第一个模板参数Num代表分子,Denom代表分母,分母默认为1,ratio代表的是一个分子除以分母的分数值,比如ratio<2>代表一个时钟周期是两秒,ratio<60>代表了一分钟,ratio<60*60>代表一个小时,ratio<60*60*24>代表一天。而ratio<1, 1000>代表的则是1/1000秒即一毫秒,ratio<1, 1000000>代表一微秒,ratio<1, 1000000000>代表一纳秒。标准库为了方便使用,就定义了一些常用的时间间隔,如时、分、秒、毫秒、微秒和纳秒,在chrono命名空间下,它们的定义如下:
1 2 3 4 5 6 7 8 9 10 typedef duration <Rep, ratio<3600 ,1 >> hours;typedef duration <Rep, ratio<60 ,1 >> minutes;typedef duration <Rep, ratio<1 ,1 >> seconds;typedef duration <Rep, ratio<1 ,1000 >> milliseconds;typedef duration <Rep, ratio<1 ,1000000 >> microseconds;typedef duration <Rep, ratio<1 ,1000000000 >> nanoseconds; std::this_thread::sleep_for (std::chrono::seconds (3 )); std::this_thread::sleep_for (std::chrono:: milliseconds (100 ));
chrono还提供了获取时间间隔的时钟周期个数的方法count() ,count()返回的间隔要向0取整,可以为负数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <chrono> #include <iostream> int main () std::chrono::milliseconds ms{3 }; std::chrono::microseconds us = 2 *ms; std::chrono::duration<double , std::ratio<1 , 30 >> hz30 (3.5 ); std::cout << "3 ms duration has " << ms.count () << " ticks\n" << "6000 us duration has " << us.count () << " ticks\n" } 输出: 3 ms duration has 3 ticks6000 us duration has 6000 ticks
时间间隔之间可以做运算,比如下面的例子中计算两端时间间隔的差值:
1 2 3 4 5 std::chrono::minutes t1 ( 10 ) ; std::chrono::seconds t2 ( 60 ) ; std::chrono::seconds t3 = t1 - t2; std::cout << t3.count () << " second" << std::endl;
其中,t1 是代表 10 分钟、t2 是代表 60 秒,t3 则是 t1 減去 t2,也就是 600 - 60 = 540 秒。通过t1-t2的count输出差值为540个时钟周期即540秒(因为每个时钟周期为一秒)。
还可以通过**duration_cast<>()**来将当前的时钟周期转换为其它的时钟周期,比如我可以把秒的时钟周期转换为分钟的时钟周期,然后通过count来获取转换后的分钟时间间隔:
1 2 3 cout << chrono::duration_cast <chrono::minutes>( t3 ).count () <<” minutes”<< endl; 将会输出: 9 minutes
使用转型后,数值就不一定是整数个tick()了,比如t2=30s时,转型后就是9分半,这时使用count()会向下取整,只取到9。
clock 谈到时间,总需要找一个时钟作为参照。clock就是这个时钟,在计算机中一般都会有一套或多套时钟系统供程序使用。在std::chrono库中,有3种时钟:
system_clock
steady_clock
hight_definition_clock
1 2 3 4 5 6 7 8 struct system_clock { typedef long long rep;typedef ratio_multiply<ratio<_XTIME_NSECS_PER_TICK, 1 >, nano> period;typedef chrono::duration<rep, period> duration;typedef chrono::time_point<system_clock> time_point;static constexpr bool is_steady = false ;
一般情况下,他们3个没有太大的区别,hight_definition_clock、steady_clock仅仅是system_clock的typedef,但是有为什么要区分呢,因为在有些情况下,他们是存在差异的。
情况1:system_clock和steady_clock的差异
比如windows系统可以提供时钟,如果认为时间不准,我们还可以进行调整。在没有调整时间前,system_clock和steady_clck是一样的,他们的读数都是单调匀速增加的;但是如果调整时间后,它们两者的读数就会出现差异,system_clock的读数就会出现跳变,而steady_clock依然保持线性单调递增,不受clock调整的影响,这个特点非常方便我们统计时间耗时(duration)。
情况2:system_clock与hight_definition_clock的差异
如果系统提供的时钟(clock)不止一种,有的时钟精度高(分辨率),有的精度低,hight_definition_clock使用时精度最高的clock,但是system_clock就不一定了。
clock主要用于获取当前的时间,通过now()方法获取,返回一个time_point,方法如下:
1 std::chrono::system_clock::time_point current_time = std::chrono::system_clock::now ();
还有两个函数方法:to_time_t():参数是time_point,转换到time_t;from_time_t():从time_t转换过来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <chrono> #include <iostream> int main () std::chrono::duration<int , std::ratio<60 *60 *24 > > one_day (1 ); std::chrono::system_clock::time_point today = std::chrono::system_clock::now (); std::time_t time_t_today = std::chrono::system_clock::to_time_t (today); std::cout << "now time stamp is " << time_t_today << std::endl; std::cout << "now time is " << ctime (&time_t_today) << std::endl; std::chrono::system_clock::time_point tomorrow = today + one_day; std::time_t time_t_tomorrow = std::chrono::system_clock::to_time_t (tomorrow); std::cout << "tomorrow time stamp is " << time_t_tomorrow << std::endl; std::cout << "tomorrow time is " << ctime (&time_t_tomorrow) << std::endl; std::chrono::system_clock::time_point next_hour = today + std::chrono::hours (1 ); std::time_t time_t_next_hour = std::chrono::system_clock::to_time_t (next_hour); std::chrono::system_clock::time_point next_hour2 = std::chrono::system_clock::from_time_t (time_t_next_hour); std::time_t time_t_next_hour2 = std::chrono::system_clock::to_time_t (next_hour2); std::cout << "tomorrow time stamp is " << time_t_next_hour2 << std::endl; std::cout << "tomorrow time is " << ctime (&time_t_next_hour2) << std::endl; return 0 ; } now time stamp is 1586662332 now time is Sun Apr 12 11 :32 :12 2020 tomorrow time stamp is 1586748732 tomorrow time is Mon Apr 13 11 :32 :12 2020 tomorrow time stamp is 1586665932 tomorrow time is Sun Apr 12 12 :32 :12 2020
time_point time_point是具体的时间,比如某年某月某日几点几分几秒,time_point依赖于clock的计时,可以用clock内部定义的time_point,也可以用自己定义的time_point。
1 2 template <class Clock , class Duration = typename Clock::duration> class time_point;
time_point有一个函数time_from_epoch()用来获得1970年1月1日到time_point时间经过的duration。举个例子,如果timepoint以天为单位,函数返回的duration就以天为单位。
由于各种time_point表示方式不同,chrono也提供了相应的转换函数 time_point_cast。
1 2 template <class ToDuration , class Clock , class Duration >time_point<Clock,ToDuration> time_point_cast (const time_point<Clock,Duration>& tp) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include <ratio> #include <chrono> int main () using namespace std::chrono; typedef duration<int ,std::ratio<60 *60 *24 >> days_type; time_point<system_clock,days_type> today = time_point_cast <days_type>(system_clock::now ()); std::cout << today.time_since_epoch ().count () << " days since epoch" << std::endl; return 0 ; }
小结 这部分主要是三种类型穿插,让人比较迷糊。一般的用法就是:
使用一个时钟的time_point,通过now()方法获取
要想直接输出就把获取的time_point通过to_time_t()转换后输出,这里还可以进一步用ctime函数格式化(返回char*)。注意time_point不能直接输出。
如果要继续处理,有两种运算方式
定义duration,与time_point进行运算(一般是求和),运算后又是一个time_point,time_point之间本身可以大小比较
time_point之间作差,返回一个duration,可以用duration_cast转换类型,调用count()计算有多少tick。如果不转类型,system_clock的time_point一般是纳秒,用count的话很大。
test 主要实现几个实例吧:
实现时间格式化输出:
实现时间点大小比较
实现时间点运算count。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <chrono> using namespace std;void printft (chrono::system_clock::time_point time) time_t tt = chrono::system_clock::to_time_t (time); cout <<"time:" << tt <<endl << "ctime:" <<ctime (&tt)<<endl<<endl; } int main () chrono::system_clock::time_point nowtime = chrono::system_clock::now (); cout<<"--------------now time----------------------" <<endl; printft (nowtime); chrono::hours twoh (2 ) ; chrono::time_point<chrono::system_clock> twohtime = nowtime+twoh; cout<<"--------------two hours after----------------------" <<endl; printft (twohtime); typedef chrono::duration<int , std::ratio<60 *60 *24 > > day; day twod (2 ) ; chrono::time_point<chrono::system_clock> twodtime = nowtime+twod; cout<<"--------------two days after----------------------" <<endl; printft (twodtime); cout<<"--------------time_point之间比较大小----------------------" <<endl; const char *str = (twodtime>nowtime)?"大" : "小" ; cout<<"两天后时间比两天前要" <<str<<endl; cout<<"--------------timepoint之间作差转型查看时间点间隔tick----------------------" <<endl; cout<<"两天后和两天前间隔 " <<chrono::duration_cast <chrono::hours>(twodtime-nowtime).count ()<<" 小时" <<endl; cout<<"system_clock time_point不转换类型tick:" <<(twodtime-nowtime).count ()<<endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 g++ -std=c++14 -o chrono_test chrono_test.cpp sun2@ubuntu:~/Desktop/websever_test/chrono_test$ ./chrono_test --------------now time---------------------- time:1664526100 ctime:Fri Sep 30 01 :21 :40 2022 --------------two hours after---------------------- time:1664533300 ctime:Fri Sep 30 03 :21 :40 2022 --------------two days after---------------------- time:1664698900 ctime:Sun Oct 2 01 :21 :40 2022 --------------time_point之间比较大小---------------------- 两天后时间比两天前要大 --------------timepoint之间作差转型查看时间点间隔tick---------------------- 两天后和两天前间隔 48 小时 system_clock time_point不转换类型tick:172800000000000
可变参宏va_list 变长参数 在无法给出所有传递给函数的参数的类型和数目时,可以使用省略号(…)指定函数参数表。有如下几种形式:
1 2 3 void fun1 (int a, double b, ...) void fun2 (int a ...) void fun3 (...)
最典型的应用就是printf函数,printf的声明和调用方法如下:
1 2 int printf ( const char *format [,argument]... ) printf ("My name is %s, age %d." , "AnnieKim" , 24 );
通常情况下,第一个参数是必不可少的,因为它可以得到函数参数的地址入口,这样就可以取之后的参数。
宏 1 2 3 4 5 6 7 8 9 10 11 12 可变参数是由宏实现的,但是由于硬件平台的不同,编译器的不同,宏的定义也不相同 头文件<stdarg.h> typedef char * va_list; #define _INTSIZEOF(n) ((sizeof(n)+sizeof(int)-1)&~(sizeof(int) - 1) ) #define va_start(ap,v) ( ap = (va_list)&v + _INTSIZEOF(v) ) #define va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) ) #define va_end(ap) ( ap = (va_list)0 )
基本使用步骤:
定义一个va_list类型的变量,变量是指向参数的指针。
va_start初始化刚定义的变量,第二个参数是最后一个 显式声明的参数。
va_arg返回变长参数的值,第二个参数是该变长参数的类型 。
va_end将第一步定义的va_list变量重置为NULL。
注意问题:
(1)可变参数的类型和个数完全由程序代码控制,它并不能智能地识别不同参数的个数和类型;
(2)如果我们不需要一一详解每个参数,只需要将可变列表拷贝至某个缓冲,可用vsprintf函数;
(3)因为编译器对可变参数的函数的原型检查不够严格,对编程查错不利.不利于我们写出高质量的代码;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int vsprintf (char *str, const char *format, va_list arg) #include <stdio.h> #include <stdarg.h> char buffer[80]int vspfunc (char *format, ...) va_list aptr; int ret; va_start (aptr, format); ret = vsprintf (buffer, format, aptr); va_end (aptr); return (ret); } int main () int i = 5 ; float f = 27.0 ; char str[50 ] = "runoob.com" ; vspfunc ("%d %f %s" , i, f, str); printf ("%s\n" , buffer); return (0 ); } 5 27.000000 runoob.com
还有vsnprintf,多了个size,size说明了str最多可写的字节,防止越界
1 int vsnprintf (char *str, size_t size, const char *format, va_list ap)
test 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <iostream> #include <stdarg.h> #include <string> void valist1 (const char * str1,...) va_list vaList; va_start (vaList,str1); std::string str = str1; while (str!="break" ) { std::cout<<str<<std::endl; str = va_arg (vaList, const char *); } va_end (vaList); } void valist2 (int arglen ,const char * str1,...) va_list vaList; va_start (vaList,str1); std::string str = str1; for (int i=1 ;i<arglen;i++) { std::cout<<str<<std::endl; str = va_arg (vaList, const char *); } std::cout<<str<<std::endl; va_end (vaList); } int main () std::cout<<std::endl; valist1 ("hello" ,"myfriend" ,"nihaoya" ,"break" ); std::cout<<std::endl; valist2 (5 ,"hi" ,"wish you" ,"happy" ,"health" ,"every day" ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 sun2@ubuntu:~/Desktop/websever_test/valist$ g++ -std=c++14 -o valist_test valist_test.cpp sun2@ubuntu:~/Desktop/websever_test/valist$ ./valist_test hello myfriend nihaoya hi wish you happy health every day
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> #include <stdarg.h> void vsptest (char * buffer,const char * format,...) va_list vaList; va_start (vaList,format); vsprintf (buffer,format,vaList); va_end (vaList); } void vsnptest (char * buffer,size_t size,const char * format,...) va_list vaList; va_start (vaList,format); vsnprintf (buffer,size,format,vaList); va_end (vaList); } int main () std::cout<<"----------测试vsprintf-------------" <<std::endl; char buffer1[50 ]; const char *format1 = "%s is %d years old, %s" ; vsptest (buffer1,format1,"jy" ,20 ,"good!" ); std::cout<<buffer1<<std::endl<<std::endl; std::cout<<"----------测试vsnprintf-------------" <<std::endl; char buffer2[50 ]; const char *format2 = "%s is %d years old, %s" ; vsnptest (buffer2,10 ,format2,"xuepi" ,20 ,"nice!" ); std::cout<<"只有10的buffer size: " <<buffer2<<std::endl; vsnptest (buffer2,50 ,format2,"xuepi" ,20 ,"nice!" ); std::cout<<"拥有50的buffer size: " <<buffer2<<std::endl<<std::endl; std::cout<<"----------测试vsnprintf,并且size超出了buffer的大小-------------" <<std::endl; char buffer3[10 ]; vsnptest (buffer3,50 ,format2,"xuepi" ,20 ,"nice!" ); std::cout<<buffer3<<std::endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sun2@ubuntu:~/Desktop/websever_test/valist$ g++ -std=c++14 -o vstest vstest.cpp sun2@ubuntu:~/Desktop/websever_test/valist$ ./vstest ----------测试vsprintf------------- jy is 20 years old, good! ----------测试vsnprintf------------- 只有10 的buffer size: xuepi is 拥有50 的buffer size: xuepi is 20 years old, nice! ----------测试vsnprintf,并且size超出了buffer的大小------------- xuepi is 20 years old, nice!
小结 四部曲,其中va_arg和vsprintf互相替换,看要哪个。va_arg就只能传一样的参数类型,可以做运算,vsprintf可以传不同的类型但是最后要写入一个char*的buffer。
也可以两个同时用,取完va_arg的参数,剩下的给vsprintf。
vsprintf和vsnprintf返回写入的字节数。
阻塞队列 阻塞队列本质上是在队列的基础上封装,添加阻塞的功能。主要就是一个普通的queue,然后用互斥锁和条件变量保护。条件变量是因为这个阻塞队列可以看成一个缓冲区,然后要生产者和消费者,因此条件变量替代信号量管理缓冲区。
当缓冲区已满时,生产者需要等待,由于是多个生产者竞争,所以要使用while-wait的等待方式。一旦push任务成功,就唤醒一个消费者线程。
当缓冲区已空时,消费者需要等待,和前面的方式一样。消费者还要支持超时处理,等待时间太长就不等待。
基本的操作都很简单,麻烦的地方在于关闭时的处理,要让在阻塞的线程退出,且不允许再操作,调用push和pop直接返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 #ifndef BLOCKQUEUE_H #define BLOCKQUEUE_H #include <mutex> #include <queue> #include <condition_variable> #include <cassert> #include <chrono> template <class T >class blockqueue { private : std::queue<T> que; std::mutex mux; std::condition_variable condprod; std::condition_variable condcons; size_t size; public : blockqueue (int maxsize = 1024 ):size (maxsize) { assert (maxsize>0 ); } ~blockqueue () { close (); } void close () void clear () bool empty () bool full () void push (const T &task) T pop () ; T pop (int timeout) ; }; template <class T >bool blockqueue<T>::empty (){ std::lock_guard<std::mutex> locker (mux) ; return que.empty (); } template <class T >bool blockqueue<T>::full (){ std::lock_guard<std::mutex> locker (mux) ; return que.size ()>=size; } template <class T >void blockqueue<T>::push (const T &task){ std::unique_lock<std::mutex> locker (mux) ; while (que.size ()>=size) condprod.wait (locker); que.push (task); condcons.notify_one (); } template <class T >T blockqueue<T>::pop () { std::unique_lock<std::mutex> locker (mux) ; while (que.empty ()) condcons.wait (locker); T task = que.front (); que.pop (); condprod.notify_one (); return task; } template <class T >T blockqueue<T>::pop (int timeout) { std::unique_lock<std::mutex> locker (mux) ; while (que.empty ()) if (condcons.wait_for (locker,std::chrono::seconds (timeout)) == std::cv_status::timeout) return T (0 ); T task = que.front (); que.pop (); condprod.notify_one (); return task; } template <class T >void blockqueue<T>::close (){ std::lock_guard<std::mutex> locker (mux) ; clear (); } template <class T >void blockqueue<T>::clear (){ std::queue<T> empty; std::swap (empty, que); } #endif
上面是一个较为完整的阻塞队列了,也是一般思考的形式,但还是有些没有完成的地方和不足。
首先我们思考一下,上层取任务的形式应该是循环pop,那么这个pop函数就需要返回一个成功或失败(在close后)的信息才能让上层线程结束循环,并且由于增加了超时处理,等待失败我们想什么都不返回,这和现在的代码不太相同。因此更好的方式是返回bool值,而取出的任务以引用参数形式传出。
1 2 3 4 5 6 7 8 9 10 11 12 13 template <class T >bool blockqueue<T>::pop (T& task, int timeout){ std::unique_lock<std::mutex> locker (mux) ; while (que.empty ()) if (condcons.wait_for (locker,std::chrono::seconds (timeout)) == std::cv_status::timeout) return false ; task = que.front (); que.pop (); condprod.notify_one (); return true ; }
然后,我们思考一下怎么通知pop和push在close后直接退出,通常的方式是使用一个close信号,像线程池那样。最简单的方式就是在pop和push入口处设置判断,如果close就直接返回false(push直接return,不做任何事情)。然而:
当上层一直调用完pop后,线程会卡在wait处,或者正在准备调用再次pop。
如果有生产者一直没抢夺到互斥锁,而被消费者占用,那么在上层pop结束后,很多的push可能会导致队列又满,从而push线程阻塞在wait处。
我们先处理pop函数,我们必须唤醒所有在等待的消费者线程,然后让线程得知已close退出;对于没有在等待而是准备进入的线程,因为队列是空,不能让其进入while,否则会阻塞:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <class T >bool blockqueue<T>::pop (T& task, int timeout){ std::unique_lock<std::mutex> locker (mux) ; while (que.empty () and !isclose) if (condcons.wait_for (locker,std::chrono::seconds (timeout)) == std::cv_status::timeout) return false ; if (isclose) return false ; task = que.front (); que.pop (); condprod.notify_one (); return true ; }
现在我们处理push函数
在关闭前,所有任务会被执行完然后消费者阻塞,这个操作由上层循环查看队列是否为空来做;注意这是日志系统析构时的操作,而消费者线程的循环是看pop的返回值,这样可以一直阻塞取任务直到超时或者close。在判断是否为空这个过程,既可以push也可以pop。
为空后在调用close前,有一段真空期可以push,同时也可以pop,这可能导致有些生产者阻塞了;
然后上层在执行完任务后调用close,close去抢占互斥锁,清空队列(那些真空期push的),设置信号,唤醒所有的消费者线程让它们退出。
由于队列清空了,此时while会被break,则唤醒阻塞的生产者并让其退出,且退出不写在while里,因为后来的生产者不会进入while,写外面让它们直接退出。这样维持队列是空,接下来的消费者线程因为进入while也退出了。
1 2 3 4 5 6 7 8 9 10 11 12 template <class T >void blockqueue<T>::push (const T &task){ std::unique_lock<std::mutex> locker (mux) ; while (que.size ()>=size) condprod.wait (locker); if (isclose) return ; que.push (task); condcons.notify_one (); }
现在close函数就出来了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <class T >void blockqueue<T>::close (){ std::lock_guard<std::mutex> locker (mux) ; que.clear (); isclose = true ; condprod.notify_all (); condcons.notify_all (); }
现在是最终版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 #ifndef BLOCKQUEUE_H #define BLOCKQUEUE_H #include <mutex> #include <queue> #include <condition_variable> #include <cassert> #include <chrono> template <class T >class blockqueue { private : std::queue<T> que; std::mutex mux; std::condition_variable condprod; std::condition_variable condcons; size_t size; bool isclose; public : blockqueue (int maxsize = 1024 ):size (maxsize),isclose (false ) { assert (maxsize>0 ); } ~blockqueue () { close (); } void close () void clear () bool empty () bool full () void push (const T &task) bool pop (T& task) bool pop (T& task, int timeout) }; template <class T >bool blockqueue<T>::empty (){ std::lock_guard<std::mutex> locker (mux) ; return que.empty (); } template <class T >bool blockqueue<T>::full (){ std::lock_guard<std::mutex> locker (mux) ; return que.size ()>=size; } template <class T >void blockqueue<T>::push (const T &task){ std::unique_lock<std::mutex> locker (mux) ; while (que.size ()>=size) condprod.wait (locker); if (isclose) return ; que.push (task); condcons.notify_one (); } template <class T >bool blockqueue<T>::pop (T& task){ std::unique_lock<std::mutex> locker (mux) ; while (que.empty () and !isclose) condcons.wait (locker); if (isclose) return false ; task = que.front (); que.pop (); condprod.notify_one (); return true ; } template <class T >bool blockqueue<T>::pop (T& task, int timeout){ std::unique_lock<std::mutex> locker (mux) ; while (que.empty () and !isclose) if (condcons.wait_for (locker,std::chrono::seconds (timeout)) == std::cv_status::timeout) return false ; if (isclose) return false ; task = que.front (); que.pop (); condprod.notify_one (); return true ; } template <class T >void blockqueue<T>::close (){ std::lock_guard<std::mutex> locker (mux) ; clear (); isclose = true ; condprod.notify_all (); condcons.notify_all (); } template <class T >void blockqueue<T>::clear (){ std::queue<T> empty; std::swap (empty, que); } #endif
test 日志主要是写入字符串,这里就模拟字符串放入阻塞队列,然后取出打印
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include <iostream> #include <thread> #include "blockqueue.h" #include <string> #include <pthread.h> #include <unistd.h> using namespace std;int main () shared_ptr<blockqueue<string>> blockque (new blockqueue <string>(1024 )); thread ([blockque_ = blockque]{ string str; while (blockque_->pop (str)) { cout<<"thread1 pop: " <<str<<endl; sleep (3 ); } }).detach (); thread ([blockque_ = blockque]{ string str; while (blockque_->pop (str)) { cout<<"thread2 pop: " <<str<<endl; sleep (3 ); } }).detach (); thread ([blockque_ = blockque]{ for (int i=0 ;i<20 ;i++) { string str; str = "theard number[" + to_string (i)+"]" ; blockque_->push (str); cout<<"push: " <<str<<endl; sleep (1 ); } }).detach (); thread ([blockque_ = blockque]{ for (int i=20 ;i<40 ;i++) { string str; str = "theard number[" + to_string (i)+"]" ; blockque_->push (str); cout<<"push: " <<str<<endl; sleep (1 ); } }).detach (); sleep (2 ); while (!blockque->empty ()); blockque->close (); thread ([blockque_ = blockque]{ for (int i=20 ;i<40 ;i++) { string str; str = "theard number[" + to_string (i)+"]" ; blockque_->push (str); } }).detach (); string s = (blockque->empty ())?"true" :"false" ; cout<<"close 之后 push,现在阻塞队列是否为空:" << s <<endl; pthread_exit (NULL ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 sun2@ubuntu:~/Desktop/websever_test/blockqueue$ g++ -std=c++14 -o blockque_test blockque_test.cpp -lpthread sun2@ubuntu:~/Desktop/websever_test/blockqueue$ ./blockque_test push: theard number[0 ] thread1 pop: theard number[0 ] push: theard number[20 ] thread2 pop: theard number[20 ] push: theard number[1 ] push: theard number[21 ] push: theard number[22 ] push: theard number[2 ] thread1 pop: theard number[1 ] thread2 pop: theard number[21 ] push: theard number[23 ] push: theard number[3 ] push: theard number[24 ] push: theard number[4 ] push: theard number[25 ] push: theard number[5 ] thread1 pop: theard number[22 ] thread2 pop: theard number[2 ] push: theard number[26 ] push: theard number[6 ] push: theard number[27 ] push: theard number[7 ] push: theard number[28 ] push: theard number[8 ] thread1 pop: theard number[23 ] thread2 pop: theard number[3 ] push: theard number[29 ] push: theard number[9 ] push: theard number[30 ] push: theard number[10 ] push: theard number[31 ] push: theard number[11 ] thread1 pop: theard number[24 ] thread2 pop: theard number[4 ] push: theard number[32 ] push: theard number[12 ] push: theard number[33 ] push: theard number[13 ] push: theard number[34 ] push: theard number[14 ] thread1 pop: theard number[25 ] thread2 pop: theard number[5 ] push: theard number[35 ] push: theard number[15 ] push: theard number[36 ] push: theard number[16 ] push: theard number[37 ] push: theard number[17 ] thread2 pop: theard number[26 ] thread1 pop: theard number[6 ] push: theard number[38 ] push: theard number[18 ] push: theard number[39 ] push: theard number[19 ] thread1 pop: theard number[27 ] thread2 pop: theard number[7 ] thread1 pop: theard number[28 ] thread2 pop: theard number[8 ] thread1 pop: theard number[29 ] thread2 pop: theard number[9 ] thread1 pop: theard number[30 ] thread2 pop: theard number[10 ] thread1 pop: theard number[31 ] thread2 pop: theard number[11 ] thread1 pop: theard number[32 ] thread2 pop: theard number[12 ] thread1 pop: theard number[33 ] thread2 pop: theard number[13 ] thread1 pop: theard number[34 ] thread2 pop: theard number[14 ] thread1 pop: theard number[35 ] thread2 pop: theard number[15 ] thread1 pop: theard number[36 ] thread2 pop: theard number[16 ] thread1 pop: theard number[37 ] thread2 pop: theard number[17 ] thread1 pop: theard number[38 ] thread2 pop: theard number[18 ] thread1 pop: theard number[39 ] thread2 pop: theard number[19 ] close 之后 push,现在阻塞队列是否为空:true
可以看到pop和push都顺利完成,且close之后进程能正常退出,且任务不会再push进去,效果还可以。
小结 我们再来梳理一下close部分:
在调用close前,日志系统会使用循环判断empty(),必须要队列为空即任务做完才close。
当empty的时候,有的消费者线程会阻塞,有的消费者线程可能还没结束执行,准备重新进入。而生产者依旧可以放入任务,并且消费者也可以执行任务。
一旦close函数抢占到了互斥锁,接下来所有的push和pop都是禁止的:
首先close会把队列清空,无论是原来已经执行完了,还是生产者在真空期放了些任务进去但没做的(关闭后放进来的不算)
然后唤醒所有在等待的消费者,清空后队列大小是0:
对于生产者,在真空期可能会大量放入任务导致阻塞,这里要唤醒;也有的后来想push的,因为队列大小是0不会进入while,直接根据close信号退出。
对于消费者,把阻塞的线程唤醒退出,但注意有的消费者可能正准备从头进入,唤醒后由于队列是空不能在让其进入while阻塞,不然会死锁。因此while的判断要加入close信号,要退出就不进入等待,直接退出。
这样阻塞队列就关闭了,遗留的任务会写完,在阻塞的线程会退出,想调用的线程也会直接退出。
write write()函数是日志系统中最重要的函数,进行主要的业务处理。我们给日志系统几点要求:
分级别,比如info、debug、warning、error,可以设定日志系统的等级,级别越低,能写入的越多。这要求write函数传入一个指示level的变量。
像printf一样支持各种形式的信息,比如float、char*、int,这可以使用可变参宏来实现,只需要向write函数传入一个format,然后传入一系列参数即可。
不把所有的日志都只写入一个文件:
当换了一天时,关闭原来的文件,新建一个文件,这要求系统记录day信息;
当一天的日志行数(一个文件行数)过多时,换一个文件;
文件命名的一个实例为:2022-10-03_log0.txt;其中log0表示这是这一天的第一份文件
一行日志信息的一个实例为:[info]2022-10-03_21:25:09:this is info
首先要处理一下时间的格式化,前面使用的ctime函数可以获得我们想要的信息,但并不是这里提到的格式化,并且我们还需要单独的day的信息。一个想法是使用一个结构体,解析ctime的返回值,把年月日时分秒存在结构体里。实际上这个结构体在c++中已经有了,是time.h中的tm结构体。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #ifndef _TM_DEFINED struct tm { int tm_sec; int tm_min; int tm_hour; int tm_mday; int tm_mon; int tm_year; int tm_wday; int tm_yday; int tm_isdst; }; #define _TM_DEFINED #endif
需要特别注意的是,年份是从1900年起至今多少年,而不是直接存储如2011年,月份从0开始的,0表示一月,星期也是从0开始的, 0表示星期日,1表示星期一。
一般有两个函数来支持tm结构体:
1 2 struct tm * gmtime (const time_t *timer); struct tm * localtime (const time_t * timer);
日历时间(Calendar Time)是通过time_t数据类型来表示的,用time_t表示的时间(日历时间)是从一个时间点(例如:1970年1月1日0时0分0秒)到此时的秒数。
gmtime()函数是将日历时间转化为世界标准时间(即格林尼治时间),并返回一个tm结构体来保存这个时间
localtime()函数是将日历时间转化为本地时间。比如现在用gmtime()函数获得的世界标准时间是2005年7月30日7点18分20秒,那么我用localtime()函数在中国地区获得的本地时间会比时间标准时间晚8个小时,即2005年7月30日15点18分20秒。
则一般的使用方式就是:
1 2 3 4 5 6 7 8 #include "time.h" #include "stdio.h" struct tm *local;time_t t;t=time (NULL ); local = localtime (&t); printf ("Local hour is: %d\n" ,local->tm_hour);
现在开始写一个write函数,我们假设上层已经保存了day信息、定义了最大行数和当前行数,且打开了一个文件fp。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #include <mutex> #include "time.h" #include <stdarg> #include <string> #include <stdio.h> #include <cassert> using namespace std;void write (int level, const char * format,...) struct tm *nowtime; time_t t; t = time (NULL ); nowtime = localtime (&t); unique_lock<mutex> locker (mux) ; linecounts++; if (logday != nowtime->tm_mday || linecounts == maxlines) { char newname[36 ]; if (logday != nowtime->tm_mday) { logday = nowtime->tm_mday; linecounts = 0 ; filenum = 0 ; snprintf (newname, 36 , "%d-%02d-%02d_log%05d.txt" ,nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); } else { linecounts = 0 ; filenum++; snprintf (newname, 36 , "%d-%02d-%02d_log%05d.txt" ,nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); } fflush (logfp); fclose (logfp); logfp = fopen (newname,"w" ); assert (logfp != nullptr ); } locker.unlock (); char infobuffer[128 ]; char timebuffer[36 ]; string allinfo; switch (level) { case 0 : allinfo += "[debug]" ; break ; case 1 : allinfo += "[info]" ; break ; case 2 : allinfo += "[warning]" ; break ; case 3 : allinfo += "[error]" ; break ; default : allinfo += "[info]" ; break ; } snprintf (timebuffer,36 , "%d-%02d-%02d_%02d:%02d:%02d:" , nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, nowtime->tm_hour,nowtime->tm_min,nowtime->tm_sec); allinfo += string (timebuffer); va_list vaList; va_start (vaList,format); vsnprintf (infobuffer,128 ,format,vaList); va_end (vaList); allinfo += string (infobuffer)+"\n" ; fputs (allinfo.c_str (),logfp); }
对于异步线程的push,这里可以做一些思考:
如果异步是像上面这种形式,那么工作线程可能会因为一个loginfo就阻塞,反倒不如直接写入;
但如果要阻塞时不阻塞直接写入,就会导致时间顺序不对;
一种解决方案是,直接再创建一个线程执行push,让线程阻塞;但这样的结果就是每个工作线程可能因为info又创建一个线程;
这样的结果就是资源相当浪费(不是不可行,前面的close的操作也支持了这样的push),或许不如就让时间顺序不一致。即当阻塞队列满了就执行同步写(不过这样前面对close里push讨论的很多就没意义辣)
或许最好的办法就是让阻塞队列长度和异步线程个数取得平衡,反正就是工作函数不要因为一个push阻塞了。
test 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <iostream> #include <mutex> #include "time.h" #include <stdarg.h> #include <string> #include <stdio.h> #include <cassert> using namespace std;const int maxlines = 256 ;int linecounts = 0 ;int logday = 123 ;int filenum = 0 ;mutex mux; FILE *logfp = fopen ("tmp.txt" ,"w" ); void write (int level, const char * format,...) struct tm *nowtime; time_t t; t = time (NULL ); nowtime = localtime (&t); unique_lock<mutex> locker (mux) ; linecounts++; if (logday != nowtime->tm_mday || linecounts == maxlines) { char newname[36 ]; if (logday != nowtime->tm_mday) { logday = nowtime->tm_mday; linecounts = 0 ; filenum = 0 ; snprintf (newname, 36 , "%d-%02d-%02d_log%05d.txt" ,nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); } else { linecounts = 0 ; filenum++; snprintf (newname, 36 , "%d-%02d-%02d_log%05d.txt" ,nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); } fflush (logfp); fclose (logfp); logfp = fopen (newname,"w" ); assert (logfp != nullptr ); } locker.unlock (); char infobuffer[128 ]; char timebuffer[36 ]; string allinfo; switch (level) { case 0 : allinfo += "[debug]" ; break ; case 1 : allinfo += "[info]" ; break ; case 2 : allinfo += "[warning]" ; break ; case 3 : allinfo += "[error]" ; break ; default : allinfo += "[info]" ; break ; } snprintf (timebuffer,36 , "%d-%02d-%02d_%02d:%02d:%02d:" , nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, nowtime->tm_hour,nowtime->tm_min,nowtime->tm_sec); allinfo += string (timebuffer); va_list vaList; va_start (vaList,format); vsnprintf (infobuffer,128 ,format,vaList); va_end (vaList); allinfo += string (infobuffer)+"\n" ; fputs (allinfo.c_str (),logfp); } int main () int level; for (int i=0 ;i<1024 ;i++) { level = i%4 ; write (level,"hello, this is num [%d], for %s %d" ,i,"level" ,level); } fclose (logfp); return 0 ; }
1 2 3 sun2@ubuntu:~/Desktop/websever_test/logwrite$ g++ -std=c++14 -o write write_test.cpp sun2@ubuntu:~/Desktop/websever_test/logwrite$ ./write
日志系统log 上面的write其实有些bug,就是当调用write时,先判断要不要切换文件,再看是写还是放入阻塞队列。这对于同步写是对的,但对于异步写,可能异步线程还没写完一个文件,就被write函数切换了文件,这实际上是不对的,因为放入阻塞队列不代表写进文件了,这里再把write操作解耦,分同步异步。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #ifndef LOG_H #define LOG_H #include <mutex> #include "time.h" #include <stdarg.h> #include <string> #include <stdio.h> #include <cassert> #include <thread> #include <dirent.h> #include <sys/stat.h> #include "blockqueue.h" using namespace std;class Log { private : Log (); public : Log (Log const &) = delete ; Log& operator =(Log const &) = delete ; ~Log (); static Log* instance () void init (int level=1 , const char * fpath = "./log" ,int maxqueue_size=1024 ,int threadnum=1 ) void setlevel (int level) int getlevel () return loglevel;} bool isopen () return logisopen;} void createthread (int threadnum) static void logthread () void write (int level, const char *format,...) void close () private : void asyncwrite () void changefile (struct tm *nowtime) struct tm * gettime (); private : static const int maxlines = 52000 ; FILE *logfp; int linecounts; int filenum; const char * path; int logday; bool isasync; bool logisopen; int loglevel; unique_ptr<blockqueue<string>> blockque; mutex mux; }; #define LOG_BASE(level, format, ...) \ do {\ Log* log = Log::instance();\ if (log->isopen() && log->getlevel() <= level) {\ log->write(level, format, ##__VA_ARGS__); \ }\ } while(0); #define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0); #define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0); #define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0); #define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0); #endif
关于为什么要用do-while(0)使用宏,主要是希望多语句宏函数在大部分时刻正确展开执行:(29条消息) 宏定义为什么要使用do{……}while(0)形式_土豆爸爸的博客-CSDN博客 。宏的换行用\。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 #include "log.h" using namespace std;Log* Log::instance () static Log instance; return &instance; } struct tm * Log::gettime (){ struct tm *nowtime; time_t t; t = time (NULL ); nowtime = localtime (&t); return nowtime; } void Log::changefile (struct tm *nowtime) linecounts++; if (logday != nowtime->tm_mday || linecounts == maxlines) { char newname[48 ]; if (logday != nowtime->tm_mday) { logday = nowtime->tm_mday; linecounts = 0 ; filenum = 0 ; snprintf (newname, 48 , "%s/%d-%02d-%02d_log%05d.txt" , path, nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); } else { linecounts = 0 ; filenum++; snprintf (newname, 48 , "%s/%d-%02d-%02d_log%05d.txt" , path, nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); } fflush (logfp); fclose (logfp); logfp = fopen (newname,"w" ); assert (logfp != nullptr ); } } void Log::write (int level, const char *format,...) struct tm *nowtime = gettime (); char infobuffer[128 ]; char timebuffer[36 ]; string allinfo; switch (level) { case 0 : allinfo += "[debug]" ; break ; case 1 : allinfo += "[info]" ; break ; case 2 : allinfo += "[warning]" ; break ; case 3 : allinfo += "[error]" ; break ; default : allinfo += "[info]" ; break ; } snprintf (timebuffer,36 , "%d-%02d-%02d_%02d:%02d:%02d:" , nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, nowtime->tm_hour,nowtime->tm_min,nowtime->tm_sec); allinfo += string (timebuffer); va_list vaList; va_start (vaList,format); vsnprintf (infobuffer,128 ,format,vaList); va_end (vaList); allinfo += string (infobuffer)+"\n" ; if (isasync && !blockque->full ()) blockque->push (allinfo); else { lock_guard<mutex> locker (mux); changefile (nowtime); fputs (allinfo.c_str (),logfp); fflush (logfp); } } Log::Log () { linecounts = -1 ; filenum = 0 ; isasync = false ; blockque = nullptr ; logday = 0 ; logfp = nullptr ; logisopen = false ; } void Log::close () logisopen = false ; if (isasync) { while (!blockque->empty ()); blockque->close (); } if (logfp) { lock_guard<mutex> locker (mux) ; fflush (logfp); fclose (logfp); logfp = nullptr ; } } Log::~Log () { close (); } void Log::logthread () Log::instance ()->asyncwrite (); } void Log::init (int level, const char * fpath,int maxqueue_size,int threadnum) if (logisopen == true ) return ; logisopen = true ; loglevel = level; if (maxqueue_size>0 ) { isasync = true ; unique_ptr<blockqueue<string>> que (new blockqueue <string>(maxqueue_size)); blockque = move (que); createthread (threadnum); } else isasync = false ; struct tm *nowtime; time_t t; t = time (NULL ); nowtime = localtime (&t); logday = nowtime->tm_mday; path = fpath; char filename[48 ]; snprintf (filename, 48 , "%s/%d-%02d-%02d_log%05d.txt" , path, nowtime->tm_year+1900 , nowtime->tm_mon+1 , nowtime->tm_mday, filenum); if (opendir (path) == NULL ) mkdir (path,0777 ); logfp = fopen (filename,"w" ); assert (logfp!=nullptr ); } void Log::asyncwrite () string str; while (blockque->pop (str)) { struct tm * nowtime = gettime (); lock_guard<mutex> locker (mux) ; changefile (nowtime); fputs (str.c_str (),logfp); fflush (logfp); } } void Log::createthread (int threadnum) for (int i=0 ;i<threadnum;i++) { thread (logthread).detach (); } }
test 所有的都准备完成了,这里分同步和异步测试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include "log.h" #include <thread> #include <pthread.h> #include <unistd.h> using namespace std;int main () cout<<"----------同步测试------------------" <<endl; Log::instance ()->init (0 ,"./同步log" ,0 ,0 ); thread ([]{ for (int i=0 ;i<70 ;i++) { LOG_DEBUG ("num %d debug" ,i); sleep (1 ); } }).detach (); thread ([]{ for (int i=0 ;i<70 ;i++) { LOG_INFO ("num %d info" ,i); sleep (1 ); } }).detach (); thread ([]{ for (int i=0 ;i<20 ;i++) { LOG_ERROR ("num %d ERROR" ,i); sleep (1 ); } }).detach (); thread ([]{ for (int i=0 ;i<70 ;i++) { LOG_WARN ("num %d warn" ,i); sleep (1 ); } }).detach (); cout<<"------主线程退出---------" <<endl; pthread_exit (NULL ); return 0 ; }
1 2 3 4 5 6 sun2@ubuntu:~/Desktop/websever_test/log$ g++ -std=c++14 -o test test.cpp log.cpp -lpthread sun2@ubuntu:~/Desktop/websever_test/log$ ./test ----------同步测试------------------ ------主线程退出---------
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> #include "log.h" #include <thread> #include <pthread.h> #include <unistd.h> using namespace std;int main () cout<<"----------异步测试------------------" <<endl; Log::instance ()->init (0 ,"./异步log" ,100 ,2 ); thread ([]{ for (int i=0 ;i<70 ;i++) { LOG_DEBUG ("num %d debug" ,i); sleep (1 ); } }).detach (); thread ([]{ for (int i=0 ;i<70 ;i++) { LOG_INFO ("num %d info" ,i); sleep (1 ); } }).detach (); thread ([]{ for (int i=0 ;i<20 ;i++) { LOG_ERROR ("num %d ERROR" ,i); sleep (1 ); } }).detach (); thread ([]{ for (int i=0 ;i<70 ;i++) { LOG_WARN ("num %d warn" ,i); sleep (1 ); } }).detach (); cout<<"------主线程退出---------" <<endl; pthread_exit (NULL ); return 0 ; }
为了更有测试效果,我们在asyncwrite函数里加一个打印
1 2 3 4 5 6 7 8 9 10 11 12 void Log::asyncwrite () string str; while (blockque->pop (str)) { cout<<"async doing: " <<str<<endl; struct tm * nowtime = gettime (); lock_guard<mutex> locker (mux) ; changefile (nowtime); fputs (str.c_str (),logfp); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sun2@ubuntu:~/Desktop/websever_test/log$ g++ -std=c++14 -o test2 test2.cpp log.cpp -lpthread sun2@ubuntu:~/Desktop/websever_test/log$ ./test2 ----------异步测试------------------ ------主线程退出--------- async doing: [debug]2022 -10 -04 _06:41 :07 :num 0 debug async doing: [info]2022 -10 -04 _06:41 :07 :num 0 info async doing: [warning]2022 -10 -04 _06:41 :07 :num 0 warn async doing: [error]2022 -10 -04 _06:41 :07 :num 0 ERROR async doing: [debug]2022 -10 -04 _06:41 :08 :num 1 debug async doing: [info]2022 -10 -04 _06:41 :08 :num 1 info ...
异步测试效果还是不错的,但是最后一个文件因为日志系统没有析构,导致缓冲区没有flush,所以最后一个文件没有写入,并且异步线程也不会自动退出。现在我们再修改一下test文件。注:现在已经改为每写一行fflush一次,因为当logerror时上层往往随后会终止程序,要记录必须刷新。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include "log.h" #include <thread> #include <pthread.h> #include <unistd.h> using namespace std;int main () cout<<"----------异步测试------------------" <<endl; Log::instance ()->init (0 ,"./异步log" ,100 ,2 ); thread ([]{ for (int i=0 ;i<70000 ;i++) { LOG_DEBUG ("num %d debug" ,i); } }).detach (); thread ([]{ for (int i=0 ;i<70000 ;i++) { LOG_INFO ("num %d info" ,i); } }).detach (); thread ([]{ for (int i=0 ;i<20000 ;i++) { LOG_ERROR ("num %d ERROR" ,i); } }).detach (); thread ([]{ for (int i=0 ;i<70000 ;i++) { LOG_WARN ("num %d warn" ,i); } }).detach (); sleep (1 ); Log::instance ()->close (); cout<<"------主线程退出---------" <<endl; pthread_exit (NULL ); return 0 ; }
这里让生产者线程快速产生大量的任务,让异步线程工作,然后等一段时间(主要是让生产者线程产生完工作,不至于调用时阻塞队列还是空的),再手动调用close。现在,所有的文件都写成功,并且异步线程退出成功。
如果让每个异步线程写一行都停一会(sleep(1)),使得在调用close后任务还没写完,可以发现close会等待异步线程把任务做完,说明关闭日志系统很成功。
关于close和析构 对于阻塞队列和日志系统,都使用了析构函数调用close,实际上日志系统的close函数是我新增的,因为我需要手动在程序里close,没办法让主线程退出时而异步线程还存在时析构而调用close。这是因为:
日志系统的static变量,只有当程序全部退出才会析构。
这会导致一些问题,就是手动close之后,主线程和异步线程都退出了会导致析构再调用一次close。在阻塞队列里,两次close不会导致什么问题,但在日志系统会有问题:free(): double free detected in tcache 2,即释放已释放的资源。在close函数中,原本没有这一行:logfp = nullptr;,而fclose并不会把fp置为nullptr,那么第二次close函数的if(logfp)就成立,又调用一次fclose,导致报错。
这里引起了一些思考:在服务器运行的时候,没有什么办法让服务器主动退出调用析构函数,ctrl+c会直接终止进程。在最初版本的tinywebsever中是捕获了ctrl+c的信号,处理成stop的一个flag通知服务器结束,c++11的版本直接不能通知服务器停下,必须强行终止。
因此,不如都手动close,而析构函数不做处理。可以使用一个线程接收终止输入,需要终止时就让这个线程调用一系列的close函数,让其他线程退出,之后调用析构函数就不会产生二次close的冲突。
这是否会浪费RAII带来的作用呢?
注意,我们手动调用close只是为了让线程不会阻塞,因为线程存在时又不会析构,不析构就没办法close然后就矛盾了。对于不会引起阻塞的类,还是可以放在析构函数里的。比如日志系统就需要手动调用close,这可能会导致一些其他资源需要在日志系统前关闭,那就导致这些资源也需要在日志系统close前手动close。
数据库 头文件#include <mysql/mysql.h>
数据库的一个连接句柄的初始化有三步
定义一个sql指针:MYSQL *sql = nullptr;
用这个指针初始化一个sql结构体,返回一个指向这个结构体的指针:sql = mysql_init(sql);
init后就connect,连接数据库,返回一个可用连接sql = mysql_real_connect(sql, host,user, pwd,dbName, port, unix_socket, client_flag);
host是主机名或IP,如果“host”是NULL或字符串”localhost”,连接将被视为与本地主机的连接。
如果unix_socket不是NULL,该字符串描述了应使用的套接字或命名管道。注意,“host”参数决定了连接的类型。
client_flag的值通常为0,其他标志可以实现特定的功能
然后这个sql句柄就可以用来执行语句了,最后在不使用的时候还需要调用mysql_close(sql);释放连接。并且,为了避免在使用库完成应用程序后发生内存泄漏(例如,在关闭与服务器的连接之后),可以显式调用mysql_library_end()。这样可以执行内存 Management 以清理和释放库使用的资源。
上面就是一个连接的建立,对于多个连接,我们可以把多个连接初始化后放入一个队列里,这样就构成了一个连接池。对于这样一个共享的连接池,就需要互斥操作。而这一个队列又和阻塞队列不同,队列是可能空的但不可能会因为满而阻塞——可用的连接是一定的,push回去不会多。在阻塞队列中使用了两个条件变量管理了空/满缓冲区的阻塞,这里只需要管理空,也即pop操作的阻塞。可以用一个条件变量,也可以用一个信号量。两种方法都比较简单,不过为了熟悉一下条件变量,还是使用条件变量(信号量就使用sem_post(&semId_)、sem_wait(&semId_)、sem_init(&semId_, 0, MAX_CONN_))。
当上层需要登录或注册时,会尝试获取一个连接,然后使用完后释放连接。这里的问题是,当没有连接可用时,是阻塞等待还是直接返回错误。或许使用折中会好一点,即用cond.wait_for()阻塞一段时间。当释放一个连接后就尝试唤醒一个阻塞的线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #ifndef SQLCONNPOOL_H #define SQLCONNPOOL_H #include <mysql/mysql.h> #include <mutex> #include <queue> #include <condition_variable> using namespace std;class Sqlconnpool { private : mutex mux; condition_variable cond; queue<MYSQL*> connque; int maxconn; int freecount; Sqlconnpool (); ~Sqlconnpool (){} public : Sqlconnpool (const Sqlconnpool&) = delete ; Sqlconnpool& operator =(const Sqlconnpool&) = delete ; void close () static Sqlconnpool* instance () MYSQL* getconn (int timeout) ; void freeconn (MYSQL* conn) void init (const char * host,int port,const char * user,const char * pwd,const char * dbname,int connsize=10 ) int conncount () }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 #include "sqlconnpool.h" #include <chrono> #include <cassert> #include "log.h" using namespace std;Sqlconnpool::Sqlconnpool () { maxconn = 0 ; freecount = 0 ; } Sqlconnpool* Sqlconnpool::instance () static Sqlconnpool instance; return &instance; } MYSQL* Sqlconnpool::getconn (int timeout = 0 ) assert (timeout>=0 ); unique_lock<mutex> locker (mux) ; while (connque.empty ()) if (cond.wait_for (locker, chrono::seconds (timeout)) == std::cv_status::timeout) { LOG_WARN ("Sqlconnpool busy" ) return nullptr ; } MYSQL* sql = connque.front (); connque.pop (); freecount--; return sql; } void Sqlconnpool::freeconn (MYSQL* conn) assert (conn); lock_guard<mutex> locker (mux) ; connque.push (conn); freecount++; cond.notify_one (); } int Sqlconnpool::conncount () lock_guard<mutex> locker (mux) ; return maxconn-freecount; } void Sqlconnpool::init (const char * host,int port,const char * user,const char * pwd,const char * dbname,int connsize) assert (connsize>0 ); maxconn = connsize; freecount = connsize; for (int i=0 ;i<maxconn;i++) { MYSQL* sql = nullptr ; sql = mysql_init (sql); if (!sql) { LOG_ERROR ("sql number %d init error" ,i); assert (sql); } sql = mysql_real_connect (sql,host,user,pwd,dbname,port,nullptr ,0 ); if (!sql) { LOG_ERROR ("sql number %d connect error" ,i); assert (sql); } connque.push (sql); } } void Sqlconnpool::close () unique_lock<mutex> locker (mux) ; while (freecount != maxconn) cond.wait (locker); while (!connque.empty ()) { mysql_close (connque.front ()); connque.pop (); } mysql_library_end (); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #ifndef SQLRAII_H #define SQLRAII_H #include "sqlconnpool.h" #include <cassert> using namespace std;class SqlRAII { private : MYSQL* conn; Sqlconnpool* connpool; public : SqlRAII (MYSQL** sql,Sqlconnpool* sqlpool,int timeout = 0 ) { assert (sqlpool); *sql = sqlpool->getconn (timeout); conn = *sql; connpool = sqlpool; } ~SqlRAII () { if (conn) connpool->freeconn (conn); } }; #endif
test 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <thread> #include "sqlraii.h" #include <iostream> #include <unistd.h> #include <pthread.h> #include "threadpool.h" #include "log.h" #include <mysql/mysql.h> using namespace std;void task ( Sqlconnpool* sqlpool,int i) MYSQL* sql; SqlRAII myconn (&sql,sqlpool,0 ) ; if (sql==nullptr ) { cout<<"haha, thread " <<i<<" can't get the connection\n" ; } else { cout<<"haha, thread " <<i<<" gets the connection\n" ; sleep (i); MYSQL_FIELD *fields = nullptr ; MYSQL_RES *res = nullptr ; const char * order = "SELECT username, passwd FROM user" ; if (mysql_query (sql,order)) { cout<<"query error\n" ; return ; } res = mysql_store_result (sql); int j = mysql_num_fields (res); fields = mysql_fetch_fields (res); cout<<"thread " <<i<<":" ; for (int k=0 ;k<j;k++) cout<<fields[k].name<<" " ; cout<<endl; while (MYSQL_ROW row = mysql_fetch_row (res)) { for (int k=0 ;k<j;k++) cout<<row[k]<<" " ; cout<<endl; } mysql_free_result (res); } } int main () Sqlconnpool* sqlpool = Sqlconnpool::instance (); Log::instance ()->init (0 ,"./log" ,10 ,1 ); sqlpool->init ("localhost" ,3306 ,"root" ,"Qq1424277869!" ,"myWebSever" ); cout<<"sqlconnpool init successfully!" <<endl; threadpool threadp (20 ) ; for (int i=3 ;i<23 ;i++) threadp.addTask (bind (task,sqlpool,i)); cout<<"add task successfully!" <<endl; sleep (1 ); threadp.close (); sqlpool->close (); Log::instance ()->close (); cout<<"quit----------------" <<endl; pthread_exit (NULL ); }
这里用到了线程池的close,重写一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #ifndef THREADPOOL_H #define THREADPOOL_H #include <mutex> #include <thread> #include <condition_variable> #include <functional> #include <queue> #include <cassert> class threadpool { private : struct pool { std::mutex mtx; std::queue<std::function<void ()>> taskQueue; std::condition_variable cond; bool isclose = false ; }; std::shared_ptr<pool> pool_; public : threadpool (int threadnum = 8 ):pool_ (std::make_shared <pool>()) { assert (threadnum > 0 ); for (int i=0 ;i<threadnum;i++) std::thread ([pool_t = pool_]{ std::unique_lock<std::mutex> locker (pool_t ->mtx); while (true ) { if (!pool_t ->taskQueue.empty ()) { auto task = pool_t ->taskQueue.front (); pool_t ->taskQueue.pop (); locker.unlock (); task (); locker.lock (); } else if (pool_t ->isclose) break ; else pool_t ->cond.wait (locker); } }).detach (); } void addTask (std::function<void ()> task) { std::lock_guard<std::mutex> locker (pool_->mtx) ; pool_->taskQueue.emplace (task); pool_->cond.notify_one (); } void close () { pool_->isclose = true ; pool_->cond.notify_all (); } ~threadpool () { } }; #endif
为什么说SqlRAII(&sql,sqlpool,0);会出错呢,主要是临时变量作用域的问题,这条语句会给sql赋值,但是临时变量只存活于这条语句里,然后就析构了,会把sql再放回连接池,其他的线程无论多少都能再拿到这个sql连接句柄。
这样,多个用户可能同时操作一个句柄,可能会引发问题;并且当调用连接池的close函数时,总是会发现连接池是满了,直接把所有的连接都关闭,这样在关闭后执行查询等操作就会出错,直接导致程序崩溃。因此要用一个有名变量,作用于线程的存活空间中。
编译一下,执行发现挺正常的,日志系统也正常,有一半能获取连接,一半不能获取连接。
1 g++ -std=c++14 -o test test.cpp log.cpp sqlconnpool.cpp -lpthread `mysql_config --cflags --libs`
我们改变一下,现在设置成可以超时10秒,可以发现这十秒钟内,在前面线程执行完放回连接后,剩下的线程又可以获取连接了。只有3个线程不能获取连接。则超时的设置也测试成功。
1 SqlRAII myconn (&sql,sqlpool,10 ) ;
结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 sun2@ubuntu:~/Desktop/websever_test/sqlpool$ g++ -std=c++14 -o test test.cpp log.cpp sqlconnpool.cpp -lpthread `mysql_config --cflags --libs` sun2@ubuntu:~/Desktop/websever_test/sqlpool$ ./test sqlconnpool init successfully! add task successfully! haha, thread 3 gets the connection haha, thread 4 gets the connection haha, thread 6 gets the connection haha, thread 5 gets the connection haha, thread 7 gets the connection haha, thread 8 gets the connection haha, thread 9 gets the connection haha, thread 10 gets the connection haha, thread 11 gets the connection haha, thread 12 gets the connection thread 3 :username passwd name passwd jysama jysama woshinidie cjy haha, thread 13 gets the connection thread 4 :username passwd name passwd jysama jysama woshinidie cjy haha, thread 14 gets the connection ......
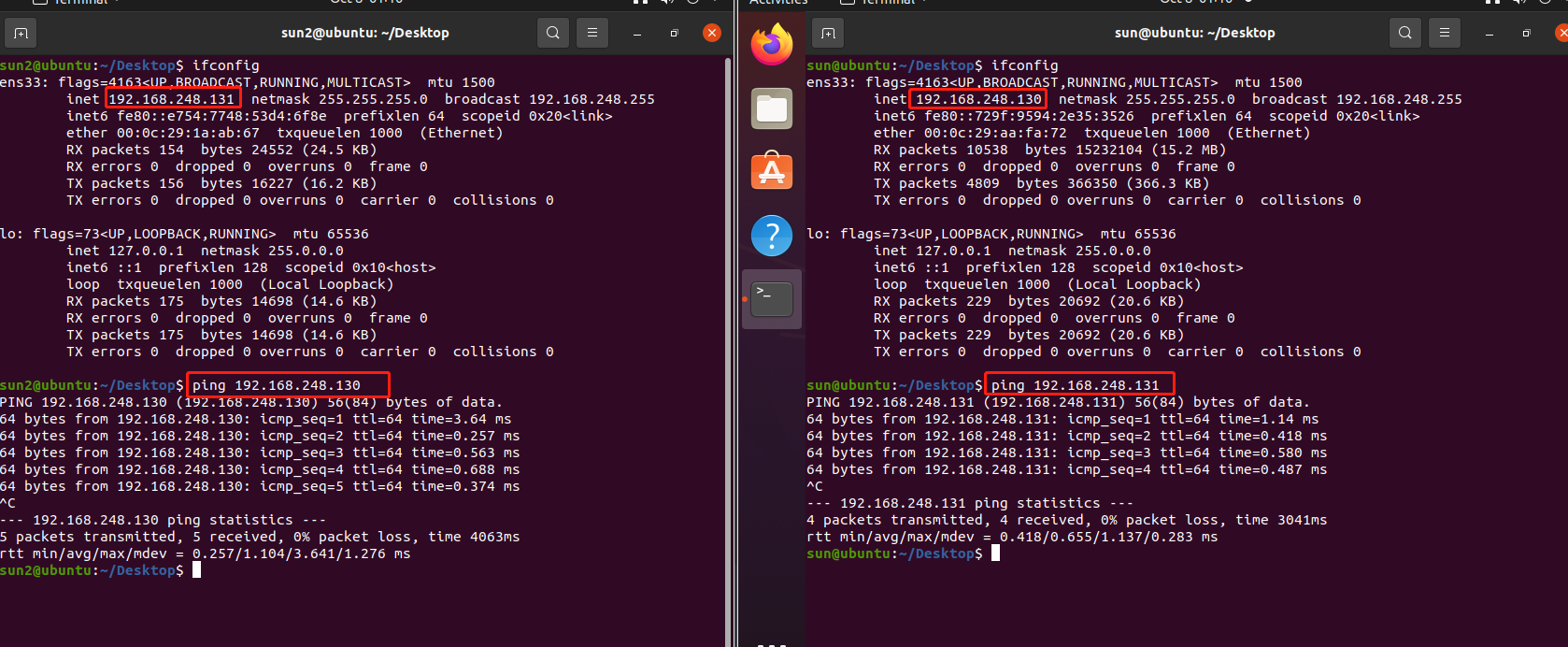
socket socket-Linux ping测试 测试终端之间的网络有没有联通。
这里先测试一下两台机器能不能互相ping通,首先是两台虚拟机之间:
如果图片加载失败可以看文字描述:具体的,使用ifconfig查看虚拟机ip,除了本地host还有一块网卡,另一块网卡ens33内容的inet 192.168.248.131就是ip。然后两个虚拟机互相ping ip就可以了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 sun2@ubuntu:~/Desktop$ ifconfig ens33: flags=4163 <UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168 .248 .131 netmask 255.255 .255 .0 broadcast 192.168 .248 .255 inet6 fe80::e754:7748 :53 d4:6f 8e prefixlen 64 scopeid 0x20 <link> ether 00 :0 c:29 :1 a:ab:67 txqueuelen 1000 (Ethernet) RX packets 154 bytes 24552 (24.5 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 156 bytes 16227 (16.2 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73 <UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0 .0 .1 netmask 255.0 .0 .0 inet6 ::1 prefixlen 128 scopeid 0x10 <host> loop txqueuelen 1000 (Local Loopback) RX packets 175 bytes 14698 (14.6 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 175 bytes 14698 (14.6 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
至于这里的ip,实际上使用了NAT转换共享了host主机的ip。虚拟机的网络设置有三种模式,可以参考:VMware Network Adapter VMnet1/8详解 - larryle - 博客园 (cnblogs.com)
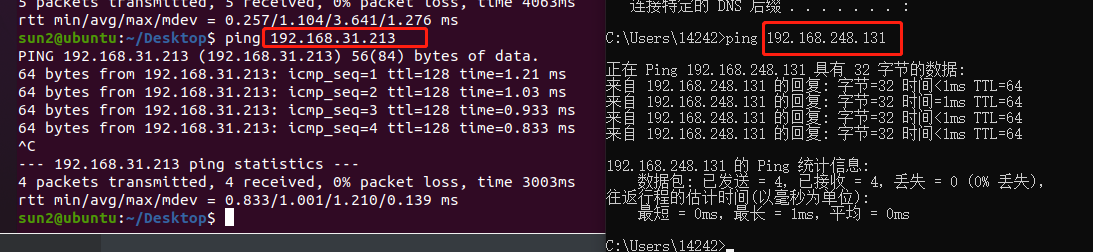
其中NAT转换使用了vmnet8,在host主机的cmd中输入ipconfig,可以看到vmnet8的网段,以及本机的ip:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 以太网适配器 VMware Network Adapter VMnet8: 连接特定的 DNS 后缀 . . . . . . . : 本地链接 IPv6 地址. . . . . . . . : fe80::21 ea:6 a23:d725:a9b7%16 IPv4 地址 . . . . . . . . . . . . : 192.168 .248 .1 子网掩码 . . . . . . . . . . . . : 255.255 .255 .0 默认网关. . . . . . . . . . . . . : 无线局域网适配器 WLAN: 连接特定的 DNS 后缀 . . . . . . . : 本地链接 IPv6 地址. . . . . . . . : fe80::b835:29 a:672 :3928 %12 IPv4 地址 . . . . . . . . . . . . : 192.168 .31 .213 子网掩码 . . . . . . . . . . . . : 255.255 .255 .0 默认网关. . . . . . . . . . . . . : 192.168 .31 .1
现在我们试一下host主机和虚拟机的ping。
也没什么问题。
Linux下套接字api简单介绍 1 2 3 4 5 6 7 <sys/types.h> <sys/socket.h> <sys/ioctl.h> <stdlib.h> <netdb.h> <netinet/in.h>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 socket () 头文件: #include <sys/types.h> #include <sys/socket.h> 函数原型: int socket (int domain, int type, int protocol) domain: 协议类型,一般为AF_INET type: socket类型 protocol:用来指定socket所使用的传输协议编号,通常设为0 即可 bind() 头文件: #include <sys/types.h> #include <sys/socket.h> 函数原型: int bind(int sockfd, struct sockaddr *my_addr, int addrlen) sockfd: socket描述符 my_addr:是一个指向包含有本机ip地址和端口号等信息的sockaddr类型的指针 addrlen:常被设为sizeof(struct sockaddr) 返回值:若成功则为0 ,若出错则为-1 connect() 头文件: #include <sys/types.h> #include <sys/socket.h> 函数原型: int connect(int sockfd, struct sockaddr *serv_addr, int addrlen) sockfd: 目的服务器的socket描述符 serv_addr:包含目的机器ip地址和端口号的指针 addrlen:sizeof(struct sockaddr) listen() 头文件: #include <sys/socket.h> 函数原型: int listen(int sockfd, int backlog); sockfd:socket ()系统调用返回的socket描述符 backlog:指定在请求队列中的最大请求数,进入的连接请求将在队列中等待accept ()它们。 accept () 头文件: #include <sys/types.h> #inlcude <sys/socket.h> 函数原型: int accept (int sockfd, struct sockaddr *addr, socklen_t *addrlen) sockfd:是被监听的socket描述符 addr:通常是一个指向sockaddr_in变量的指针,该变量用来存放提出连接请求服务的主机的信息 addrlen:sizeof(struct sockaddr_in) 成功时,返回非负整数,该整数是接收到套接字的描述符;出错时,返回-1 ,相应地设定全局变量errno。 send() 头文件: #include <sys/socket.h> 函数原型: int send(int sockfd, const void *msg, int len, int flags); sockfd:用来传输数据的socket描述符 msg:要发送数据的指针 flags: 0 recv () 头文件: #include <sys/types.h> #include <sys/socket.h> 函数原型: int recv (int sockfd, void *buf, int len, unsigned int flags) sockfd:接收数据的socket描述符 buf:存放数据的缓冲区 len:缓冲的长度 flags:0 sendto() 头文件: #include <sys/types.h> #include <sys/socket.h> 函数原型: int sendto(int sockfd, const void *msg, int len, unsigned int flags, const struct sockaddr *to, int tolen); recvfrom () 头文件: #include <sys/types.h> #include <sys/socket.h> 函数原型: int recvfrom (int sockfd, void *buf, int len, unsigned int flags, struct sockaddr *from, int fromlen) read () write () 头文件: #include <unistd.h> int read (int fd, char *buf, int len) int write (int fd, char *buf, int len) int close (int sockfd) #include <unistd.h> 关闭已连接的套接字只是导致相应描述符的引用计数减1 ,如果引用计数扔大于0 ,这个close调用并不会让TCP连接上发送一个FIN。 如果确实想发送一个FIN,可以用shutdown函数。 shutdown () int shutdown (int sockfd, int how) 该函数的行为依赖howto参数的值: SHUT_RD 套接字中不再有数据可接收,而且套接字接收缓冲区中的现有数据都被丢弃。 SHUT_WR 对于TCP套接字,称为半关闭(half-close)。当前在套接字发送缓冲区中的数据将被发送掉,后跟TCP的正常连接终止序列。(不管套接字的引用计数是否等于0) SHUT_RDWR 等于调用shutdown函数两次,连接的读半部和写半部都关闭。
socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。
bind()函数把一个地址族中的特定地址赋给socket。例如对应AF_INET、AF_INET6就是把一个ipv4或ipv6地址和端口号组合赋给socket。
通过 listen() 函数可以让套接字进入被动监听状态,所谓被动监听,是指当没有客户端请求时,套接字处于“睡眠”状态,只有当接收到客户端请求时,套接字才会被“唤醒”来响应请求。所以,执行accept的是被动套接字,执行connect的是主动套接字。
作为一个服务器,在调用socket()、bind()之后就会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。
当套接字处于监听状态时,可以通过 accept() 函数来接收客户端请求。accept() 返回一个新的套接字来和客户端通信,addr 保存了客户端的IP地址和端口号,而 sock 是服务器端的套接字,大家注意区分。后面和客户端通信时,要使用这个新生成的套接字,而不是原来服务器端的套接字。
两台计算机之间的通信相当于两个套接字之间的通信,在服务器端用 write() 向套接字写入数据,客户端就能收到,然后再使用 read() 从套接字中读取出来,就完成了一次通信。
recv函数和send函数提供了read和write函数一样的功能,不同的是他们提供了四个参数。前面的三个参数和read、write函数是一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct sockaddr { sa_family_t sin_family; char sa_data[14 ]; }; struct sockaddr_in {__uint8_t sin_len;sa_family_t sin_family;in_port_t sin_port;struct in_addr sin_addr;char sin_zero[8 ];}; addr.sin_len=sizeof (addr); sin_family指代协议族,在socket编程中一般是AF_INET sin_port存储端口号(使用网络字节顺序) sin_addr存储IP地址,使用in_addr这个数据结构 sin_zero是为了让sockaddr与sockaddr_in两个数据结构保持大小相同而保留的空字节 struct in_addr { in_addr_t s_addr; }; 结构体in_addr 用来表示一个32 位的IPv4地址 in_addr_t 一般为 32 位的unsigned int ,其字节顺序为网络顺序(network byte ordered),即该无符号整数采用大端字节序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <arpa/inet.h> uint16_t htons (uint16_t hostshort) htons 是把你机器上的整数转换成“网络字节序”, 网络字节序是 big-endian,也就是整数的高位字节存放在内存的低地址处。 而我们常用的 x86 CPU (intel, AMD) 电脑是 little-endian,也就是整数的低位字节放在内存的低字节处。 举个例子: 假定你的port是0x1234,在网络字节序里,这个port放到内存中就应该显示成 addr 0x12 addr+1 0x34 而在x86电脑上,0x1234放到内存中实际是: addr 0x34 addr+1 0x12 htons 的用处就是把实际内存中的整数存放方式调整成“网络字节序”的方式。 ntohs相反
1 2 3 4 #include <arpa/inet.h> uint32_t htonl (uint32_t hostlong) ntohl相反
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <arpa/inet.h> in_addr_t inet_addr (const char *cp) 将一个点分十进制的IP转换成一个长整数型数(u_long类型),也即in_addr结构体中s_addr的类型(大端排列) inet_addr的参数是字符串,返回值是网络字节序,htonl的参数是32b it的ip,并且是主机字节序 int inet_aton (const char *strptr, struct in_addr *addrptr) inet_addr ("*.*.*.*" ) inet_addr与inet_aton不同在于,他的返回值为转换后的32 位网络字节序二进制值,而不是作为出参返回,这样存在一个问题,他的返回值返回的有效IP地址为0.0 .0 .0 到255.255 .255 .255 ,如果函数出错,返回常量值INADDR_NONE(这个值一般为一个32 位均为1 的值),这意味着点分二进制数串255.255 .255 .255 (IPv4的有限广播地址)不能由此函数进行处理。 inet_ntoa是inet_aton和(几乎和)inet_addr相反的函数 char FAR* inet_ntoa ( struct in_addr in ) inet_pton inet_ntop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 socketfd 描述了一个 socket结构体 socket 结构体的定义如下: struct socket { socket_state state; unsigned long flags; const struct proto_ops *ops; struct fasync_struct *fasync_list; struct file *file; struct sock *sk; wait_queue_head_t wait; short type; }; 其中,struct sock 包含有一个 sock_common 结构体,而sock_common结构体又包含有struct inet_sock 结构体,而struct inet_sock 结构体的部分定义如下: struct inet_sock { struct sock sk; #if defined(CONFIG_IPV6) || defined(CONFIG_IPV6_MODULE) struct ipv6_pinfo *pinet6; #endif __u32 daddr; __u32 rcv_saddr; __u16 dport; __u16 num; ………… } 由此,我们清楚了,socket结构体不仅仅记录了本地的IP和端口号,还记录了目的IP和端口(四元组)。 这样,通过一个socket描述符,就能accept和connect了。 而服务器一般只需要一个端口,即使accept也不会新开端口: 由于TCP/IP协议栈是维护着一个接收和发送缓冲区的。在接收到来自客户端的数据包后,服务器端的TCP/IP协议栈应该会做如下处理:如果收到的是请求连接的数据包(connect),则传给监听着连接请求端口的socetfd套接字,进行accept处理; 如果是已经建立过连接后的客户端数据包,则将数据放入接收缓冲区。这样,当服务器端需要读取指定客户端的数据时,则可以利用socketfd_new 套接字通过recv或者read函数到缓冲区里面去取指定的数据(因为socketfd_new代表的socket对象记录了客户端IP和端口,因此可以鉴别)。 本质上因为客户端的ip和端口不同,accept创建新的socketfd,可以通过socket区分用户
api详解
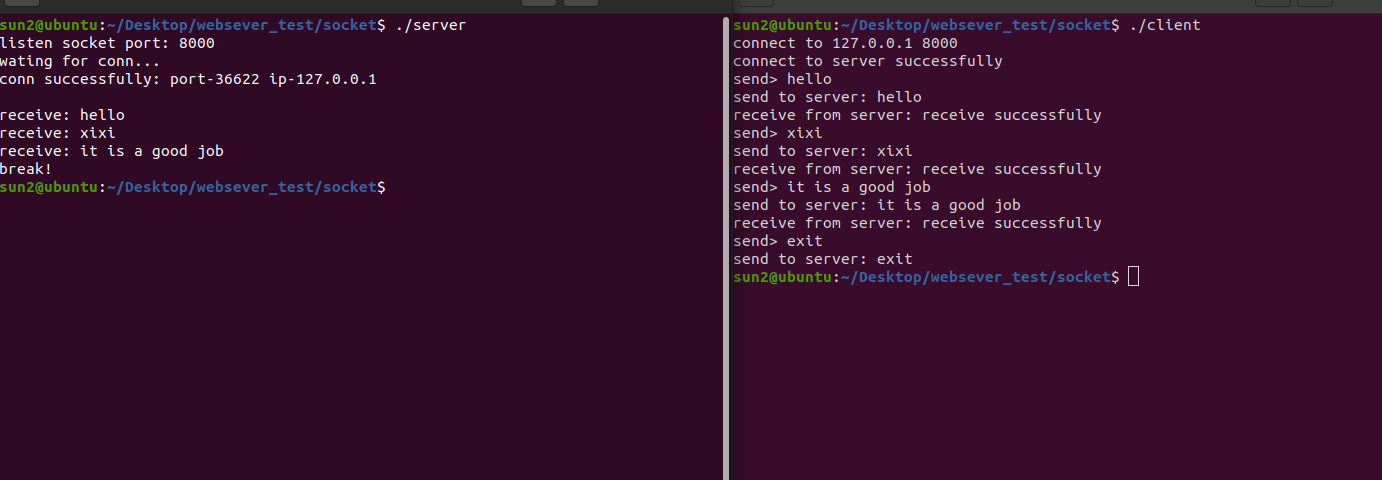
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <string.h> #include <iostream> #include <unistd.h> #define myport 8000 const char * SERVER_IP = "127.0.0.1" ;int main () int connfd = socket (AF_INET,SOCK_STREAM,IPPROTO_TCP); struct sockaddr_in socketaddr; socketaddr.sin_family = AF_INET; socketaddr.sin_port = htons (myport); struct in_addr inaddr; inet_aton (SERVER_IP,&inaddr); socketaddr.sin_addr = inaddr; std::cout<<"connect to " <<SERVER_IP<<" " <<myport<<std::endl; if (connect (connfd, (struct sockaddr *)&socketaddr, sizeof (socketaddr)) == -1 ) { std::cerr<<"connect error" <<std::endl; exit (1 ); } std::cout<<"connect to server successfully" <<std::endl; char sendbuf[1024 ]; char recvbuf[1024 ]; std::cout<<"send> " ; while (fgets (sendbuf, sizeof (sendbuf), stdin) != NULL ) { std::cout<<"send to server: " <<sendbuf; send (connfd, sendbuf, strlen (sendbuf),0 ); if (strcmp (sendbuf,"exit\n" )==0 ) break ; recv (connfd, recvbuf, sizeof (recvbuf),0 ); std::cout<<"receive from server: " <<recvbuf<<std::endl; bzero (sendbuf,sizeof (sendbuf)); bzero (recvbuf,sizeof (recvbuf)); std::cout<<"send> " ; } close (connfd); return 0 ; }
编译就正常g++编译
socket-Windows 基本的socket操作在<WinSock2.h>这个头文件,包括许多使用到的网络相关的结构体和函数。
加载/释放Winsock库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 WORD sockVersion=MAKEWORD (2 ,2 ); WSADATA wsaData;
1 2 3 4 5 6 7 8 9 10 11 12 if (WSAStartup (sockVersion, &wsaData)!=0 ){ return 0 ; }
创建socket使用SOCKET这一关键字;关闭socket使用closesocket()函数。
没有bzero函数,使用memset
没有inet_aton(),需要使用inet_pton(),头文件是<WS2tcpip.h>,多了第一个参数,AF_INET或AF_INET6,指定ipv4或ipv6。
INVALID_SOCKET值为int的-1
#pragma comment(lib,”ws2_32.lib”)表示链接 Ws2_32.lib 这个库,加载dll。
这种方式和在工程设置_链接库里面添加 Ws2_32.lib 的效果一样,不过这种方法写的程序,别人在使用你的代码的时候就不用再设置工程了。使用 DLL 之前必须把 DLL 加载到当前程序,这里在程序运行时加载,表示加载了ws2_32.dll
比较新的操作是:初始化WSA资源,从而根据设置在dll文件中找到对应的库;释放WSA资源,解除库占用。其他都和linux差不多。而这几步不同的操作基本都是复制粘贴不需要变的。
关于lib和dll
1 2 3 4 5 6 7 8 9 10 lib库有两种: 1、静态链接库(Static Link Library) 这种 lib 中有函数的实现代码,它是将 lib 中的代码加入目标模块(.exe 或者 .dll)文件中,所以链接好了之后,lib 文件就没有用了。 这种 lib文件实际上是任意个 obj 文件的集合。obj 文件则是 cpp 文件编译生成的, 如果有多个 cpp 文件则会编译生成多个 obj 文件,从而生成的 lib 文件中也包含了多个 obj。 2、动态链接库(Dynamic Link Library)的导入库(Import Library) 这种 lib 是和 dll 配合使用的,里面没有代码,代码在 dll 中,这种 lib 是用在静态调用 dll 上的,所以起的作用也是链接作用, 链接完成了, lib 也没用了。至于动态调用 dll 的话,根本用不上 lib 文件。目标模块(exe 或者 dll)文件生成之后,就用不着 lib 文件了。
客户端实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 #include <iostream> #include <cstring> #include <WinSock2.h> #include <WS2tcpip.h> #pragma comment(lib,"ws2_32.lib" ) #define myport 8000 const char * SERVER_IP = "192.168.248.131" ;int main () WORD sockVersion = MAKEWORD (2 , 2 ); WSADATA wsaData; if (WSAStartup (sockVersion, &wsaData) != 0 ) { std::cout << "WSAStartup() error!" << std::endl; return 0 ; } SOCKET connfd = socket (AF_INET, SOCK_STREAM, IPPROTO_TCP); if (connfd == INVALID_SOCKET) { std::cout << "socket error !" << std::endl; return 0 ; } struct sockaddr_in socketaddr; socketaddr.sin_family = AF_INET; socketaddr.sin_port = htons (myport); struct in_addr inaddr; inet_pton (AF_INET, SERVER_IP, &inaddr); socketaddr.sin_addr = inaddr; std::cout << "connect to " << SERVER_IP << " " << myport << std::endl; if (connect (connfd, (struct sockaddr*)&socketaddr, sizeof (socketaddr)) == -1 ) { std::cerr << "connect error" << std::endl; exit (1 ); } std::cout << "connect to server successfully" << std::endl; char sendbuf[1024 ]; char recvbuf[1024 ]; memset (sendbuf, 0 , sizeof (sendbuf)); memset (recvbuf, 0 , sizeof (recvbuf)); std::cout << "send> " ; while (fgets (sendbuf, sizeof (sendbuf), stdin) != NULL ) { std::cout << "send to server: " << sendbuf; send (connfd, sendbuf, strlen (sendbuf), 0 ); if (strcmp (sendbuf, "exit\n" ) == 0 ) break ; recv (connfd, recvbuf, sizeof (recvbuf), 0 ); std::cout << "receive from server: " << recvbuf << std::endl; memset (sendbuf, 0 , sizeof (sendbuf)); memset (recvbuf, 0 , sizeof (recvbuf)); std::cout << "send> " ; } closesocket (connfd); WSACleanup (); return 0 ; }
使用vs2022跑程序,可以跑通,虚拟机的网卡并没有设置其他的东西,使用了默认的NAT模式就行,不过有可能要配置端口转发,好在我的机器不用-。-
exe生成发布 参考(29条消息) 在VisualStudio上生成代码的exe可执行文件_hunk954的博客-CSDN博客_visualstudio怎么生成exe
其中关于多线程MT和多线程MD,可以参考多线程MT和多线程MD的区别 - 繁星jemini - 博客园 (cnblogs.com) ,使用MD较多,小项目就没啥差别了。
socket-文件传输 服务器接收文件,客户端发送文件
客户端:主要是打开文件,然后读到缓冲区,不断发送
FILE *fopen(const char *filename, const char *mode)
filename – 字符串,表示要打开的文件名称。mode – 字符串,表示文件的访问模式,可以是以下的值:
r 以只读方式打开文件,该文件必须存在。
r+ 以可读写方式打开文件,该文件必须存在。
rb+ 读写打开一个二进制文件,允许读数据。
rw+ 读写打开一个文本文件,允许读和写。
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。(EOF符保留)
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。 (原来的EOF符不保留)
wb 只写打开或新建一个二进制文件;只允许写数据。
wb+ 读写打开或建立一个二进制文件,允许读和写。
ab+ 读写打开一个二进制文件,允许读或在文件末追加数据。
vs已不支持fopen,使用fopen_s(linux下还是用fopen):errno_t fopen_s( FILE** pFile, const char *filename, const char *mode );
err = fopen_s(&fp,“filename”,“w”);
打开文件成功返回0,失败返回非0。
int ferror(FILE *stream)
测试给定流 stream 的错误标识符。如果出错返回一个非零值,否则返回0。
int feof(FILE *stream)
测试给定流 stream 的文件结束标识符。如果fread后文件读完了(指针到文件末尾),返回非零值,否则返回0
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
ptr – 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针。size – 这是要读取的每个元素的大小,以字节为单位。nmemb – 这是元素的个数,每个元素的大小为 size 字节。stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流。成功读取的元素总数会以 size_t 对象返回,size_t 对象是一个整型数据类型。如果总数与 nmemb 参数不同,则可能发生了一个错误或者到达了文件末尾。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 #include <iostream> #include <cstring> #include <WinSock2.h> #include <WS2tcpip.h> #include <stdio.h> #include <chrono> #pragma comment(lib,"ws2_32.lib" ) #define myport 8000 #define buffSize 102400 const char * SERVER_IP = "192.168.248.131" ;int main () WORD sockVersion = MAKEWORD (2 , 2 ); WSADATA wsaData; if (WSAStartup (sockVersion, &wsaData) != 0 ) { std::cout << "WSAStartup() error!" << std::endl; return 0 ; } SOCKET connfd = socket (AF_INET, SOCK_STREAM, IPPROTO_TCP); if (connfd == INVALID_SOCKET) { std::cout << "socket error !" << std::endl; return 0 ; } struct sockaddr_in socketaddr; socketaddr.sin_family = AF_INET; socketaddr.sin_port = htons (myport); struct in_addr inaddr; inet_pton (AF_INET, SERVER_IP, &inaddr); socketaddr.sin_addr = inaddr; std::cout << "connect to " << SERVER_IP << " " << myport << std::endl; if (connect (connfd, (struct sockaddr*)&socketaddr, sizeof (socketaddr)) == -1 ) { std::cerr << "connect error" << std::endl; exit (1 ); } std::cout << "connect to server successfully" << std::endl; char sendbuf[buffSize]; memset (sendbuf, 0 , sizeof (sendbuf)); const char * filename = "test.pdf" ; FILE* fp = NULL ; if (fopen_s (&fp,filename, "rb" ) != 0 ) { std::cerr << "cannot open file " << filename << std::endl; exit (1 ); } std::chrono::system_clock::time_point time1 = std::chrono::system_clock::now (); int nSend = 0 ; int totalSend = 0 ; while (1 ) { int nRead = fread (sendbuf, 1 , buffSize, fp); if (ferror (fp) != 0 ) { std::cerr << "failed to read file " << std::endl; exit (1 ); } nSend = send (connfd, sendbuf, nRead, 0 ); if (nSend == SOCKET_ERROR) { std::cerr << "the connection to server has been failed" << std::endl; exit (1 ); } totalSend += nSend; printf ("success to send %d bytes\n" , nSend); if (feof (fp)) { printf ("success to transmit file to server\n" ); break ; } } std::chrono::system_clock::time_point time2 = std::chrono::system_clock::now (); printf ("success to send %d bytes totally\n" , totalSend); std::cout<<"spend " <<std::chrono::duration_cast <std::chrono::milliseconds>(time2-time1).count ()<<" ms" <<std::endl; closesocket (connfd); WSACleanup (); return 0 ; }
服务器端:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <string.h> #include <iostream> #include <unistd.h> #include <stdio.h> #define myport 8000 #define buffSize 102400 int main () int listenfd = socket (AF_INET,SOCK_STREAM,IPPROTO_TCP); struct sockaddr_in socketaddr; socketaddr.sin_family = AF_INET; socketaddr.sin_port = htons (myport); socketaddr.sin_addr.s_addr = htonl (INADDR_ANY); if (bind (listenfd,(struct sockaddr *)&socketaddr,sizeof (socketaddr))==-1 ) { std::cerr<<"bind" <<std::endl; exit (1 ); } std::cout<<"listen socket port: " <<myport<<std::endl; if (listen (listenfd,SOMAXCONN) == -1 ) { std::cerr<<"listen" <<std::endl; exit (1 ); } char recvbuf[buffSize]; struct sockaddr_in client_addr; socklen_t len = sizeof (client_addr); std::cout<<"wating for conn..." <<std::endl; int conn = accept (listenfd, (struct sockaddr*)&client_addr, &len); if (conn==-1 ) { std::cerr<<"connect" <<std::endl; exit (1 ); } std::cout<<"conn successfully: port-" <<ntohs (client_addr.sin_port)<<" ip-" <<inet_ntoa (client_addr.sin_addr)<<std::endl<<std::endl; std::string str = "receive successfully" ; const char * filename = "test.pdf" ; FILE *fp=NULL ; if ((fp=fopen (filename,"wb" ))==NULL ) { std::cerr << "cannot open file " <<filename<<std::endl; exit (1 ); } while (1 ) { int nRecv = recv ( conn, recvbuf, buffSize, 0 ); if ( nRecv == SO_ERROR ) { std::cerr << "connection to client has been failed" <<std::endl; exit (1 ); } else if ( nRecv == 0 ) { printf ( "client close, maybe the file transmit successfully\n" ); break ; } int nWrite=fwrite (recvbuf,1 ,nRecv,fp); if (nWrite!=nRecv || ferror (fp)!=0 ) { std::cerr <<"failed to write file" <<std::endl; exit (1 ); } } close (conn); close (listenfd); return 0 ; }
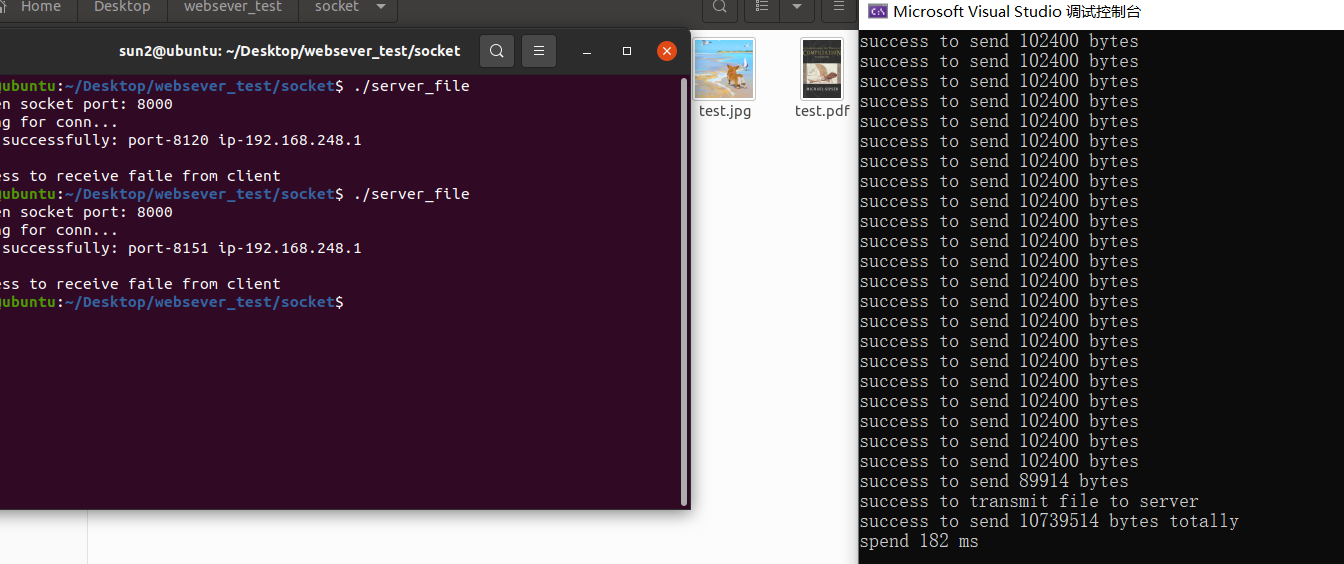
结果 使用102400的buffer大小(比10240快),发送10M的文件耗时100多ms
栈空间默认只有1M大小,所以buffer不能太大。可以试一下用堆空间
开一个1M的buffer空间,结果和栈差不多。因为访问栈会比访问堆快,访问堆的一个具体单元,需要两次访问内存,第一次得取得指针,第二次才是真正得数据,而栈只需访问一次。另外,堆的内容被操作系统交换到外存的概率比栈大,栈一般是不会被交换出去的。
发一个300M的pdf需要5s。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 #include <iostream> #include <cstring> #include <WinSock2.h> #include <WS2tcpip.h> #include <stdio.h> #include <chrono> #pragma comment(lib,"ws2_32.lib" ) #define myport 8000 #define buffSize 102400 int main () WORD sockVersion = MAKEWORD (2 , 2 ); WSADATA wsaData; if (WSAStartup (sockVersion, &wsaData) != 0 ) { std::cout << "WSAStartup() error!" << std::endl; return 0 ; } int listenfd = socket (AF_INET, SOCK_STREAM, IPPROTO_TCP); struct sockaddr_in socketaddr; socketaddr.sin_family = AF_INET; socketaddr.sin_port = htons (myport); socketaddr.sin_addr.s_addr = htonl (INADDR_ANY); if (bind (listenfd, (struct sockaddr*)&socketaddr, sizeof (socketaddr)) == -1 ) { std::cerr << "bind" << std::endl; exit (1 ); } std::cout << "listen socket port: " << myport << std::endl; if (listen (listenfd, SOMAXCONN) == -1 ) { std::cerr << "listen" << std::endl; exit (1 ); } char recvbuf[buffSize]; struct sockaddr_in client_addr; socklen_t len = sizeof (client_addr); std::cout << "wating for conn..." << std::endl; int conn = accept (listenfd, (struct sockaddr*)&client_addr, &len); if (conn == -1 ) { std::cerr << "connect" << std::endl; exit (1 ); } std::string str = "receive successfully" ; const char * filename = "test.zip" ; FILE* fp = NULL ; if (fopen_s (&fp, filename, "wb" ) != 0 ) { std::cerr << "cannot open file " << filename << std::endl; exit (1 ); } while (1 ) { int nRecv = recv (conn, recvbuf, buffSize, 0 ); if (nRecv == SO_ERROR) { std::cerr << "connection to client has been failed" << std::endl; exit (1 ); } else if (nRecv == 0 ) { printf ("client close, maybe the file transmit successfully\n" ); break ; } int nWrite = fwrite (recvbuf, 1 , nRecv, fp); if (nWrite != nRecv || ferror (fp) != 0 ) { std::cerr << "failed to write file" << std::endl; exit (1 ); } } closesocket (listenfd); closesocket (conn); WSACleanup (); return 0 ; }
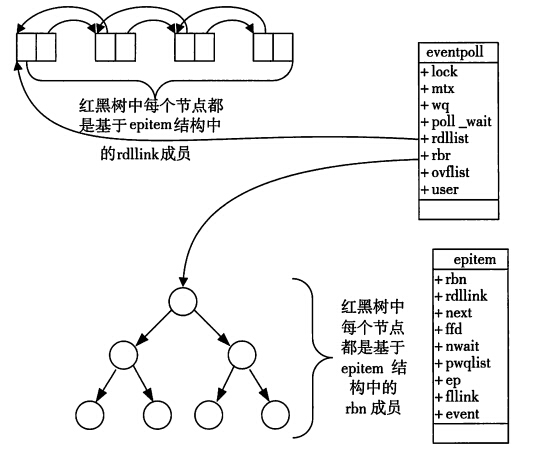
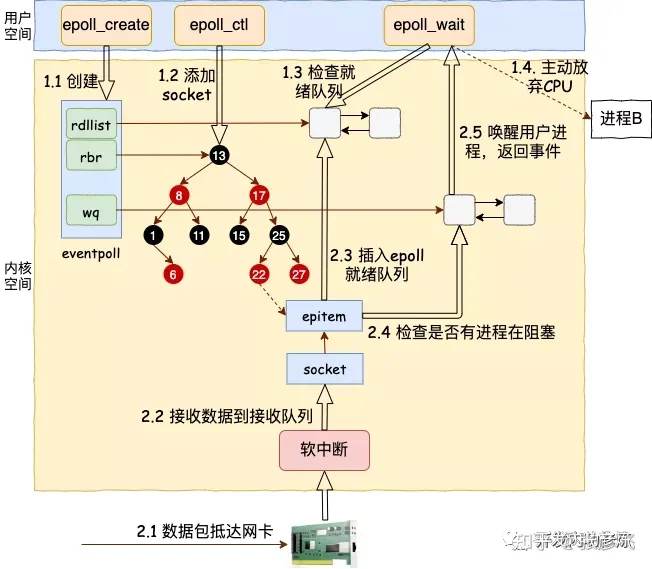
epoll epoll是对于服务器端来说的,可以用前面的客户端来连接验证。我们来简单看看epoll的底层。
select和epoll的区别(面试常考)
首先select是posix支持的,而epoll是linux特定的系统调用,因此,epoll的可移植性就没有select好,但是考虑到epoll和select一般用作服务器的比较多,而服务器中大多又是linux,所以这个可移植性的影响应该不会很大。
其次,select可以监听的文件描述符有限,最大值为1024,而epoll可以监听的文件描述符则是系统对整个进程限制的最大文件描述符。
接下来就要谈epoll和select的性能比较了,这个一般情况下应该是epoll表现好一些,否则linux也不会去特定实现epoll函数了,那么epoll为什么比select更高效呢?原因有很多,第一点,epoll通过每次有就绪事件时都将其插入到一个就绪队列中,使得epoll_wait的返回结果中只存储了已经就绪的事件,而select则返回了所有被监听的事件,事件是否就绪需要应用程序去检测,那么如果已被监听但未就绪的事件较多的话,对性能的影响就比较大了。第二点,每一次调用select获得就绪事件时都要将需要监听的事件重复传递给操作系统内核,而epoll对监听文件描述符的处理则和获得就绪事件的调用分开,这样获得就绪事件的调用epoll_wait就不需要重新传递需要监听的事件列表,这种重复的传递需要监听的事件也是性能低下的原因之一。除此之外,epoll的实现中使用了mmap调用使得内核空间和用户空间共享内存,从而避免了过多的内核和用户空间的切换引起的开销。
然后就是epoll提供了两种工作模式,一种是水平触发模式,这种模式和select的触发方式是一样的,要只要文件描述符的缓冲区中有数据,就永远通知用户这个描述符是可读的,这种模式对block和noblock的描述符都支持,编程的难度也比较小;而另一种更高效且只有epoll提供的模式是边缘触发模式,只支持nonblock的文件描述符,他只有在文件描述符有新的监听事件发生的时候(例如有新的数据包到达)才会通知应用程序,在没有新的监听时间发生时,即使缓冲区有数据(即上一次没有读完,或者甚至没有读),epoll也不会继续通知应用程序,使用这种模式一般要求应用程序收到文件描述符读就绪通知时,要一直读数据直到收到EWOULDBLOCK/EAGAIN错误,使用边缘触发就必须要将缓冲区中的内容读完,否则有可能引起死等,尤其是当一个listen_fd需要监听到达连接的时候,如果多个连接同时到达,如果每次只是调用accept一次,就会导致多个连接在内核缓冲区中滞留,处理的办法是用while循环抱住accept,直到其出现EAGAIN。这种模式虽然容易出错,但是性能要比前面的模式更高效,因为只需要监听是否有事件发生,发生了就直接将描述符加入就绪队列即可。
select的缺点 select的缺点:
单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在linux内核头文件中,有这样的定义:#define __FD_SETSIZE 1024)
内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销;
(不是返回就绪数组)select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
1 2 3 4 5 通俗版本可能是这样的: 应用程序拿着一张纸:内核哥,我想知道这张纸上面三个表格中画1的地方对应的文件描述符,有没有发生啥事件。 内核说:程序弟,稍等。。。,我给你把没有事件的地方画上0,有事件的地方保留1. 内核在纸上一顿涂改操作,把没事件发生的地方改成了0,有事件的地方保留1,然后把纸交给程序。 然后,程序拿着纸,看着有1的地方就知道这地方发生了事件,他要去处理了。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
epoll底层 当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
1 2 3 4 5 6 7 8 9 10 11 struct eventpoll { .... struct rb_root rbr; struct list_head rdlist; .... };
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
1 2 3 4 5 有的人误以为 epoll 高效的全部因为这棵红黑树,这就有点夸大红黑树的作用了。 其实红黑树的作用是仅仅是在管理大量连接的情况下,添加和删除 socket 非常的高效。 如果 epoll 管理的 socket 固定的话,在数据收发的事件管理过程中其实红黑树是没有起作用的。 内核在socket上收到数据包以后,可以直接找到 epitem(epoll item),并把它插入到就绪队列里,然后等用户进程把事件取走。 这个过程中,红黑树的作用并不会得到体现。
所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。也是通过这个回调关系(更具体来说是一个指针),根据socket能直接找到epitem(我们创建记录的fd只是为了能找到socket),epitem中又包含了fd供用户使用。那为什么又要红黑树呢?因为要管理这些事件,当事件要关闭时还要找得到事件来关闭。
在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
1 2 3 4 5 6 7 struct epitem { struct rb_node rbn; struct list_head rdllink; struct epoll_filefd ffd; struct eventpoll *ep; struct epoll_event event; }
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
api
int epoll_create(int size)
创建一个指示epoll内核事件表的文件描述符,该描述符将用作其他epoll系统调用的第一个参数,size不起作用。(从Linux 2.6.8开始,max_size参数将被忽略,但必须大于零。)
成功时,返回一个非负文件描述符。发生错误时,返回-1,并且将errno设置为指示错误
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout)
触发模式:
代码实现 只看epoll部分,其他先不考虑。是很简单的接收响应,不涉及对写事件的响应。这里是同步的代码,主要还是了解一下代码流程。
框架 几乎所有的epoll程序都使用下面的框架:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 for ( ; ; ) { nfds = epoll_wait (epfd,events,20 ,500 ); for (i=0 ;i<nfds;++i) { if (events[i].data.fd==listenfd) { connfd = accept (listenfd,(sockaddr *)&clientaddr, &clilen); ev.data.fd=connfd; ev.events=EPOLLIN|EPOLLET; epoll_ctl (epfd,EPOLL_CTL_ADD,connfd,&ev); } else if ( events[i].events&EPOLLIN ) { n = read (sockfd, line, MAXLINE)) < 0 ev.data.ptr = md; ev.events=EPOLLOUT|EPOLLET; epoll_ctl (epfd,EPOLL_CTL_MOD,sockfd,&ev); } else if (events[i].events&EPOLLOUT) { struct myepoll_data* md = (myepoll_data*)events[i].data.ptr; sockfd = md->fd; send ( sockfd, md->ptr, strlen ((char *)md->ptr), 0 ); ev.data.fd=sockfd; ev.events=EPOLLIN|EPOLLET; epoll_ctl (epfd,EPOLL_CTL_MOD,sockfd,&ev); } else { } } }
LT模式 (29条消息) epoll 的LT与ET实例_five丶的博客-CSDN博客 代码参考的博客,有修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 #include <unistd.h> #include <iostream> #include <string> #include <sys/socket.h> #include <errno.h> #include <cstring> #include <netinet/in.h> #include <arpa/inet.h> #include <sys/epoll.h> #include <fcntl.h> #include <signal.h> #include <netdb.h> #include <sys/types.h> static int setReuseAddr (int fd) if (fd < 0 ) return -1 ; int on = 1 ; if (setsockopt ( fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof (on)) < 0 ) { return -1 ; } return 0 ; } int main () const int port = 8000 ; const int MAX_EVENT = 20 ; struct epoll_event ev, event[MAX_EVENT]; const char * const local_addr = "127.0.0.1" ; struct sockaddr_in server_addr = { 0 }; int listenfd = socket (AF_INET, SOCK_STREAM, 0 ); if (-1 == listenfd) { std::cout << "create listenfd failed:" << strerror (errno) << std::endl; return -1 ; } if (setReuseAddr (listenfd) < 0 ){ std::cout << "set reuse addr failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl (INADDR_ANY); server_addr.sin_port = htons (port); if (bind (listenfd, (const struct sockaddr *)&server_addr, sizeof (server_addr)) < 0 ) { std::cout << "bind port failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } if (listen (listenfd, SOMAXCONN) < 0 ) { std::cout << "listen failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } int epfd = epoll_create (5 ); if (-1 == epfd) { std::cout << "create epoll failed" << strerror (errno) << std::endl; return -1 ; } ev.data.fd = listenfd; ev.events = EPOLLIN ; if (epoll_ctl (epfd, EPOLL_CTL_ADD, listenfd, &ev) < 0 ) { std::cout << "epoll add failed:" << strerror (errno) << std::endl; close (listenfd); close (epfd); return 0 ; } for ( ; ; ){ int nfds; nfds = epoll_wait (epfd, event, MAX_EVENT, -1 ); std:: cout << "epoll_wait return" << std::endl; for (int i = 0 ; i < nfds; i++){ uint32_t events = event[i].events; if (events & EPOLLERR || events & EPOLLHUP) { std::cout << "epoll has error" << strerror (errno) << std::endl; close (event[i].data.fd); continue ; } else if (event[i].data.fd == listenfd){ struct sockaddr in_addr = { 0 }; socklen_t in_addr_len = sizeof (in_addr); int client_sock = accept (listenfd, nullptr , nullptr ); if (client_sock < 0 ){ break ; } std::cout << "accept client" << std::endl; ev.events = EPOLLIN; ev.data.fd = client_sock; if (epoll_ctl ( epfd, EPOLL_CTL_ADD, client_sock, &ev) < 0 ){ std::cout << client_sock <<" epoll_ctl falied: " << std::endl; close (client_sock); close (listenfd); close (epfd); return 0 ; } } else { ssize_t result_len; char buf[10 ] = { 0 }; result_len = read (event[i].data.fd, buf, sizeof (buf) - 1 ); if (result_len == -1 ){ close (event[i].data.fd); } else if (!result_len){ continue ; } std::cout << "receive message:" << buf << std::endl; send (event[i].data.fd, "receive!" , 9 , 0 ); } } } close (listenfd); close (epfd); }
LT模式下对端ctrl+c关闭会导致服务器epoll_wait不阻塞一直循环。原因是产生了一个事件一直得不到解决,可以用EPOLLONESHOT(亲测可用),不过要重新设置文件描述符。这里可以先不管,测试和参考博客一样,且可以连接多台客户端。
ET模式
ET模式下每次write或read需要循环write或read直到返回EAGAIN错误。以读操作为例,这是因为ET模式只在socket描述符状态发生变化时才触发事件,如果不一次把socket内核缓冲区的数据读完,会导致socket内核缓冲区中即使还有一部分数据,该socket的可读事件也不会被触发
根据上面的讨论,若ET模式下使用阻塞IO,则程序一定会阻塞在最后一次write或read操作,因此说ET模式下一定要使用非阻塞IO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 #include <unistd.h> #include <iostream> #include <string> #include <sys/socket.h> #include <errno.h> #include <cstring> #include <netinet/in.h> #include <arpa/inet.h> #include <sys/epoll.h> #include <fcntl.h> #include <signal.h> #include <netdb.h> #include <sys/types.h> static int setNonblock (int fd) if (fd < 0 ) return -1 ; int flags = fcntl (fd, F_GETFL, 0 ); if (flags < 0 ) { return -1 ; } flags |= O_NONBLOCK; if (fcntl (fd, F_SETFL, flags) < 0 ) { return -1 ; } return 0 ; } static int setReuseAddr (int fd) if (fd < 0 ) return -1 ; int on = 1 ; if (setsockopt ( fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof (on)) < 0 ) { return -1 ; } return 0 ; } int main () const int port = 8000 ; const int MAX_EVENT = 20 ; struct epoll_event ev, event[MAX_EVENT]; const char * const local_addr = "127.0.0.1" ; struct sockaddr_in server_addr = { 0 }; int listenfd = socket (AF_INET, SOCK_STREAM, 0 ); if (-1 == listenfd) { std::cout << "create listenfd failed:" << strerror (errno) << std::endl; return -1 ; } if (setReuseAddr (listenfd) < 0 ){ std::cout << "set reuse addr failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl (INADDR_ANY); server_addr.sin_port = htons (port); if (bind (listenfd, (const struct sockaddr *)&server_addr, sizeof (server_addr)) < 0 ) { std::cout << "bind port failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } if (setNonblock (listenfd) < 0 ) { std::cout << "set listenfd nonblock failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } if (listen (listenfd, 200 ) < 0 ) { std::cout << "listen failed:" << strerror (errno) << std::endl; close (listenfd); return -1 ; } int epfd = epoll_create (5 ); if (1 == epfd) { std::cout << "create epoll failed" << strerror (errno) << std::endl; return -1 ; } ev.data.fd = listenfd; ev.events = EPOLLIN | EPOLLET ; if (epoll_ctl (epfd, EPOLL_CTL_ADD, listenfd, &ev) < 0 ) { std::cout << "epoll add failed:" << strerror (errno) << std::endl; close (listenfd); close (epfd); return 0 ; } for ( ; ; ){ int nfds; nfds = epoll_wait (epfd, event, MAX_EVENT, -1 ); std:: cout << "epoll_wait return" << std::endl; for (int i = 0 ; i < nfds; i++){ uint32_t events = event[i].events; if (events & EPOLLERR || events & EPOLLHUP) { std::cout << "epoll has error" << strerror (errno) << std::endl; close (event[i].data.fd); continue ; } else if (event[i].data.fd == listenfd){ for ( ; ; ){ struct sockaddr in_addr = { 0 }; socklen_t in_addr_len = sizeof (in_addr); int client_sock = accept (listenfd, nullptr , nullptr ); if (client_sock < 0 ){ break ; } std::cout << "accept client" << std::endl; if (setNonblock (client_sock) < 0 ){ std::cout << client_sock <<" set non_block falied: " << std::endl; close (client_sock); return 0 ; } ev.events = EPOLLIN | EPOLLET; ev.data.fd = client_sock; if (epoll_ctl ( epfd, EPOLL_CTL_ADD, client_sock, &ev) < 0 ){ std::cout << client_sock <<" epoll_ctl falied: " << std::endl; close (client_sock); return 0 ; } } } else { int done = 0 ; for ( ; ; ){ ssize_t result_len; char buf[10 ] = { 0 }; result_len = read (event[i].data.fd, buf, sizeof (buf) - 1 ); if (result_len == -1 ){ if (errno != EAGAIN && errno != EWOULDBLOCK){ done = 1 ; epoll_ctl ( epfd, EPOLL_CTL_DEL, event[i].data.fd, nullptr ); } break ; } else if (!result_len){ done = 1 ; break ; } std::cout << "receive message:" << buf << std::endl; send (event[i].data.fd, "receive!" , 9 , 0 ); } if (done){ std::cout << "close connection" << std::endl; close (event[i].data.fd); } } } } close (listenfd); close (epfd); }
测试结果和博客一样,如果把ET模式下代码改成不一次读完,那么冗余的数据会在下次客户端send后接收。
EPOLLONESHOT 客户端ctrl+c不会出现像LT模式下那样有某个事件然后一直处理不了不断循环,因为ET模式只触发一次相同事件或者说只在从非触发到触发两个状态转换的时候儿才触发。
因此EPOLLONESHOT在ET模式下,主要是为了防止多线程操作同一个socket:socket接收到数据交给一个线程处理数据,在数据没有处理完之前又有新数据达到触发了事件,另一个线程被激活获得该socket,从而产生多个线程操作同一socket,即使在ET模式下也有可能出现这种情况。采用EPOLLONETSHOT事件的文件描述符上的注册事件只触发一次,要想重新注册事件则需要调用epoll_ctl重置文件描述符上的事件,这样前面的socket就不会出现竞态。