Note
这部分简单学习一些目前比较新的计网相关的技术,不作特别深入,但尽可能保证介绍明白。
kubernetes
简介
kubernetes 简称 k8s,是一个容器自动化运维平台,可以高效管理容器集群。k8s 位于容器编排层,只管理容器,而不提供容器引擎来负责容器生命周期的管理,因此 k8s 需要借助docker 这类容器引擎才能工作。简单来说,容器引擎提供应用级别的一个抽像去管理应用,而k8s 是提供应用级别集群的抽象去管理容器集群。
k8s 的用途有:跨主机编排容器、更充分地利用硬件资源来最大化地满足企业应用的需求、通过自动布局、自动重启、自动复制、自动伸缩实现应用的状态检查与自我修复、控制与自动化应用的部署与升级等等。在架构上,k8s 主要由 master 节点和 node 节点组成,master 管理 node 的功能实施:
- master 节点组件:
- (1) etcd:k8s 集中的状态存储,存储所有的集群状态数据;
- (2) API server:k8s 的通讯接口和命令总线;
- (3) scheduler:k8s 负责调度决策的组件,掌握着当前集群资源的使用情况;
- (4) controller manager:通过 API server 监控集群的状态,确保集群实际状态和预期的一致。
- node 节点组件:
- (1) kubelet:资源管理,监听 API server 上的事件;
- (2) kube-proxy:管理 k8s 上面的服务和网络;
- (3) docker:容器对象,负责实施应用功能。
对比传统应用部署
部署 kubernetes 应用与部署传统应用的不同之处:
- 传统应用会部署在一个操作系统上,程序员开发程序面临的接口是操作系统的 api,并在单一主机上部署和运行程序。由于不同操作系统之间的 ABI(二进制接口),导致应用程序的移植面临巨大困难。而部署 kubernetes 应用则使用 k8s 集群对外提供的 api 接口,应用程序开发出来天然适应于运行在云平台之上,而非传统的单机应用程序。
- 部署 kubernetes 应用不需要考虑具体的环境。kubernetes 使用容器化解决方案,每个应用可以被打包成一个容器镜像,这便于管理、扩展和回收,也不用管在哪个机器执行,具体的环境是什么。而这些是部署传统应用需要考虑的东西。
- 由于部署 kubernetes 应用不需要考虑具体的环境,在应用开发与部署的过程中,应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境,能够实现服务的无缝迁移。
- 传统应用是运行在操作系统上的一个或多个进程,不管需不需要服务,应用程序都始终运行着。而 kubernetes 平时并不运行应用程序,而是等到有客户去访问服务时,才运行一个微服务。一旦访问完毕,应用程序的使命结束后将停止运行。直到再次被调用时,才再次运行。此时,应用程序变成了函数,也就是所谓的函数即服务。
部署
- 购买一台弹性云服务器(ECS)
- 安装minikube,这是轻量化的k8s集群
- 安装docker作为底层容器引擎
- 安装kubectl,这是k8s集群的命令行管理工具
- 安装coredns(插件式)作为集群的DNS服务器,用于服务发现,也就是服务(应用)之间相互定位的过程。
为什么需要服务发现
在K8S集群中,POD有以下特性:
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
- 服务动态性强
容器在k8s中迁移会导致POD的IP地址变化 - 更新发布频繁
版本迭代快,新旧POD的IP地址会不同 - 支持自动伸缩
大促或流量高峰需要动态伸缩,IP地址会动态增减
service资源解决POD服务发现:
为了解决pod地址变化的问题,需要部署service资源,用service资源代理后端pod,通过暴露service资源的固定地址(集群IP),来解决以上POD资源变化产生的IP变动问题,并且多个提供相同服务的pod可以用service实习负载均衡。
那service资源的服务发现呢?
service资源提供了一个不变的集群IP供外部访问,但
- IP地址毕竟难以记忆
- service资源可能也会被销毁和创建
- 能不能将service资源名称和service暴露的集群网络IP对应类似域名与IP关系,则只需记服务名就能自动匹配服务IP,岂不就达到了service服务的自动发现
在k8s中,coredns就是为了解决以上问题。
container
简介
容器是一种沙盒技术,主要目的是为了将应用运行在其中,与外界隔离;及方便这个沙盒可以被转移到其它宿主机器。本质上,它是一个特殊的进程。通过名称空间(Namespace)、控制组(Control groups)、切根(chroot)技术把资源、文件、设备、状态和配置划分到一个独立的空间。
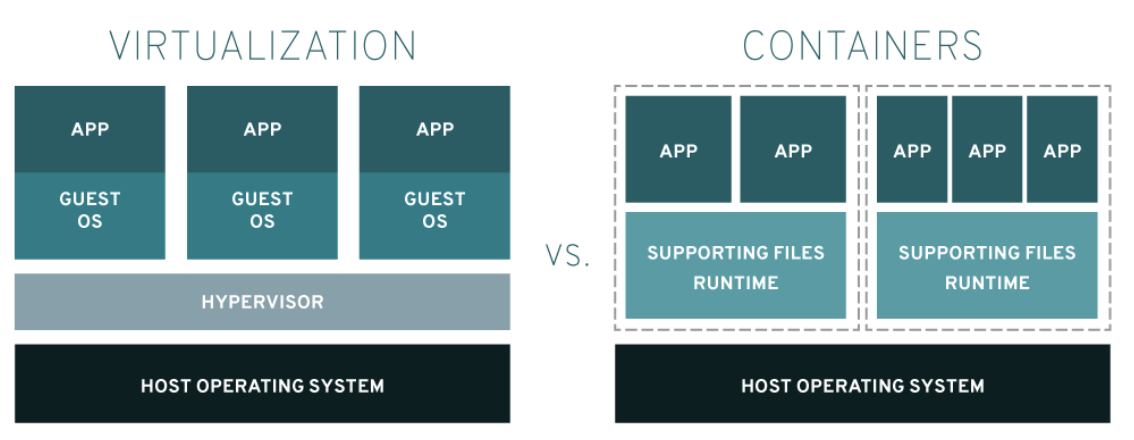
与虚拟机不同,容器不提供操作系统级虚拟化,从而降低了初始化容器的开销。在实际场景中,一台物理计算机可能会运行数百个容器。
Docker是最著名的容器平台。在docker的生命周期中,镜像和容器是最重要的两部分。其中镜像是文件,是一个只读的模板,一个独立的文件系统,里面包含运行容器所需的数据,可以用来创建新的容器;而容器是基于镜像创建的进程,容器中的进程依赖于镜像中的文件,容器具有写的功能,可以根据需要改写里面的软件、配置等,并可以保存为新的镜像。如果是用import方法生成,则是一个完全新的镜像。如果用的是commit方法生成的新的镜像,则新镜像与原来的镜像之间存在着继承关系。
对比虚拟机
容器和虚拟机都是用于创建可在其中运行应用程序的隔离环境的技术。但是,它们有一些关键差异。容器和虚拟机之间的主要区别之一是它们的实现方式。容器是一个轻量级、独立的可执行包,它包含应用程序运行所需的所有内容,包括应用程序代码、库、依赖项和运行时。另一方面,虚拟机是一个成熟的独立操作系统,它运行在主机操作系统之上并虚拟化所有硬件资源。
另一个区别是提供的隔离级别。容器提供高级别的进程级隔离,这意味着每个容器运行自己的进程,并具有自己的文件系统和网络堆栈。但是,容器共享主机操作系统的内核,这意味着它们不提供与主机系统的完全隔离。另一方面,虚拟机提供与主机系统的完全隔离,因为它们有自己的内核和硬件虚拟化层。第三个区别是开销和资源要求。容器通常比虚拟机更轻量级,需要的资源更少,因为它们不需要虚拟化所有硬件资源。这使得它们的启动速度更快,运行效率更高。
总体而言,容器和虚拟机之间的主要区别在于它们的实现方式、它们提供的隔离级别以及开销和资源要求。
vxlan
overlay
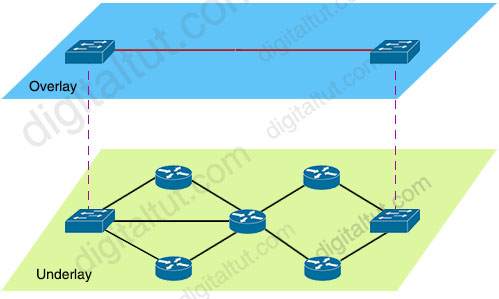
可以将覆盖网络(overlay)视为位于另一个网络之上的计算机网络。叠加网络中的所有节点都通过逻辑或虚拟链路相互连接,并且每个链路都对应于底层网络中的路径。
vxlan简介
VXLAN 通常被描述为一种覆盖技术(也是一种隧道技术),因为它允许通过将以太网帧封装(隧道)到包含 IP 地址的 VXLAN 数据包中,从而在干预的第 2 层网络上延伸第 3 层连接。
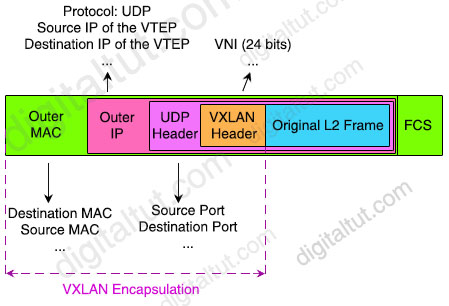
每个协议标头中 VXLAN 数据包的关键字段包括:
- + 外部 MAC 标头(14 字节,4 字节可选)— 包含源 VTEP(VXLAN 隧道端点)的 MAC 地址和下一跃点路由器的 MAC 地址。数据包路径上的每个路由器都会重写此标头,以便源地址是路由器的 MAC 地址,目标地址是下一跃点路由器的 MAC 地址。
- + 外部 IP 标头(20 字节)- 包含源和目标 VTEP 的 IP 地址。
- +(外部)UDP 标头(8 字节)- 包含源和目标 UDP 端口:
- – 源 UDP 端口:VXLAN 协议在 UDP 数据包标头中重新利用此标准字段。协议不会将此字段用于源 UDP 端口,而是将其用作 VTEP 之间特定流的数字标识符。VXLAN 标准没有定义如何派生此数字,但源 VTEP 通常根据来自内部第 2 层数据包和原始帧的第 3 层或第 4 层标头的字段组合的哈希值来计算它。
- – 目标 UDP 端口:VXLAN UDP 端口。互联网号码分配机构 (IANA) 将端口 4789 分配给 VXLAN。
- + VXLAN 标头(8 字节)- 包含 24 位 VNI。
- + 原始以太网/L2 帧 – 包含原始第 2 层以太网帧。
总的来说,VXLAN 封装向原始以太网帧添加了 50 到 54 字节的额外标头信息。由于这可能导致以太网帧超过默认的 1514 字节 MTU,因此最佳做法是在整个网络中实现巨型帧。
并且,我们可以看到VXLAN数据包只不过是一个MAC-in-UDP封装的数据包。VXLAN 报头将添加到原始第 2 层帧,然后放置在 UDP-IP 数据包中。此封装允许 VXLAN 数据包通过第 2 层网络从第 3 层网络进行隧道传输。
解决虚拟局域网问题
在两个虚拟局域网中的两台主机是无法互相ping通网络的,假设有两台虚拟机(相当于两个虚拟局域网),并且虚拟机中使用mininet创建主机节点,那么不同虚拟机中的节点不能互相ping通。
网络不可达的原因是:
- 在物理host主机里,两台虚拟机相当于在一个小型局域网下,它们之间是可以进行网络通信的(本身可达,即overlay下层网络underlay可达,只要建立上层逻辑层即可实现互联);
- 而继续在虚拟机中使用mininet创建host时,mininet相当于在每个虚拟机下又创建了小型局域网,此时这两个小型局域网又是虚拟机中的内网,mininet创建的主机相当于两个内网下的主机,当然是不能进行网络通信的。
这时就可以利用VXLAN建立逻辑上的隧道,将两台虚拟机中的mininet互连。VXLAN在两个虚拟机上各自建立一个VTEP,所谓的VTEP(VXLAN Tunnel Endpoints,VXLAN隧道端点)就是VXLAN网络的边缘设备,是VXLAN隧道的起点和终点,VXLAN对用户原始数据帧的封装和解封装均在VTEP上进行。
有了VTEP后,mininet中的数据包就能通过VTEP转发到另一台虚拟机的隧道端点并在链路层转发。这本质上是由于底层的物理链路(underlay)本就是连通的,因此只要在两个mininet只要在逻辑上建立一条隧道(overlay),就能打破内网限制。
WIRESHARK 抓包
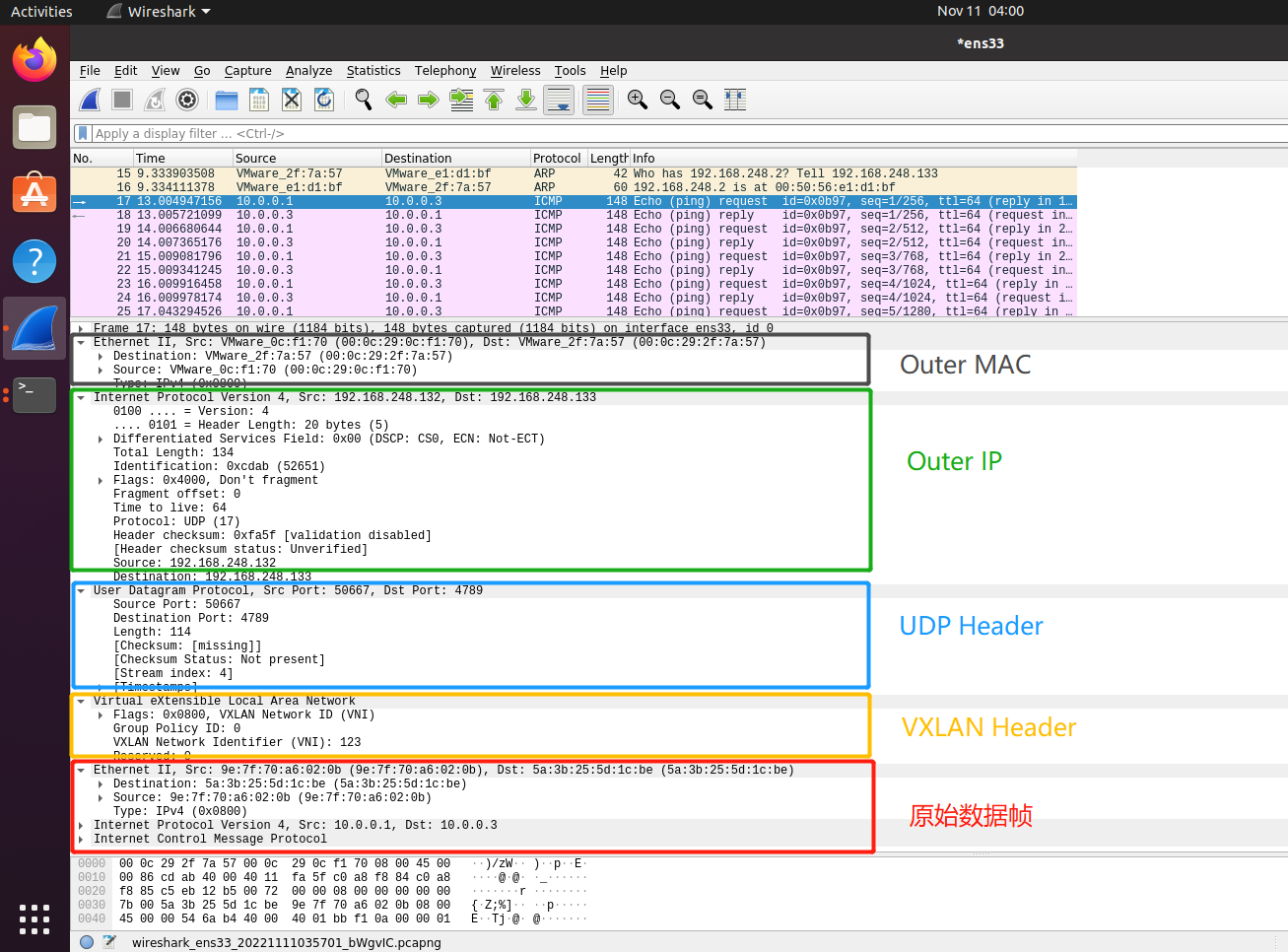
使用WIRESHARK抓取VM1中host1 ping VM2中host2时发送的ICMP协议数据帧,可以看到包已经进行了VXLAN封装:
- 最外层是源和目的VTEP的MAC地址;
- 往里一层是源和目的VTPE的IP地址,也就是虚拟机的IP地址;
- 接着是UDP首部,仅包含了端口号而不包含IP;
- 然后是VXLAN首部,包含24-bit的VNI;
- 最后是原始帧,从IP地址可以看到使用的是各自的私有地址。
这次抓包显示了VTEP是如何工作的:将内部主机的报文进行VXLAN封装,通过配置的对端IP发送数据帧到对端VTEP上,对端的VTEP再进行VXLAN解包,再把原始的数据帧转发到内部主机。
MTU相关问题
根据VXLAN 7348 RFC,VXLAN报文不建议分片,否则在接收端VTEP上会丢弃分片的报文。

MTU是单个IP数据包的最大值,而MSS通常是MTU减去40字节的TCP/IP首部。VTEP会进行VXLAN封装,通常情况下是增加50字节的首部内容,如果使用默认的MSS,那么数据帧的大小就会再加上40字节的TCP/IP首部和50字节的VXLAN首部。默认的MTU是1500字节,默认的MSS是1460字节,如果使用VXLAN技术,就需要将MSS调整为1410字节,否则报文会丢失。
因此在部署VXLAN网络前需要对MTU进行全局规划,有两种方式:
- 方式一:修改应用层服务器发送报文的长度值,修改后的长度值加上VXLAN封装的50字节后,需保证在整个承载网中,均小于设备的MTU值。使用此方法,修改难度低,需要IT侧配合。这种方式是比较推荐的。
- 方式二:修改承载网中每一跳网络设备的MTU值,需保证MTU值大于收到的VXLAN报文长度,从而保证不分片。此方式常常受到约束:承载网络中设备众多、分布广泛,且涉及不同厂商,修改难度大;常常没有修改权限(他人资产,不可控)。
eBPF
eBPF的背景
eBPF 全称 extended Berkeley Packet Filter,中文意思是 扩展的伯克利包过滤器。一般来说,要向内核添加新功能,需要修改内核源代码或者编写 内核模块 来实现。而 eBPF 允许程序在不修改内核源代码,或添加额外的内核模块情况下运行。
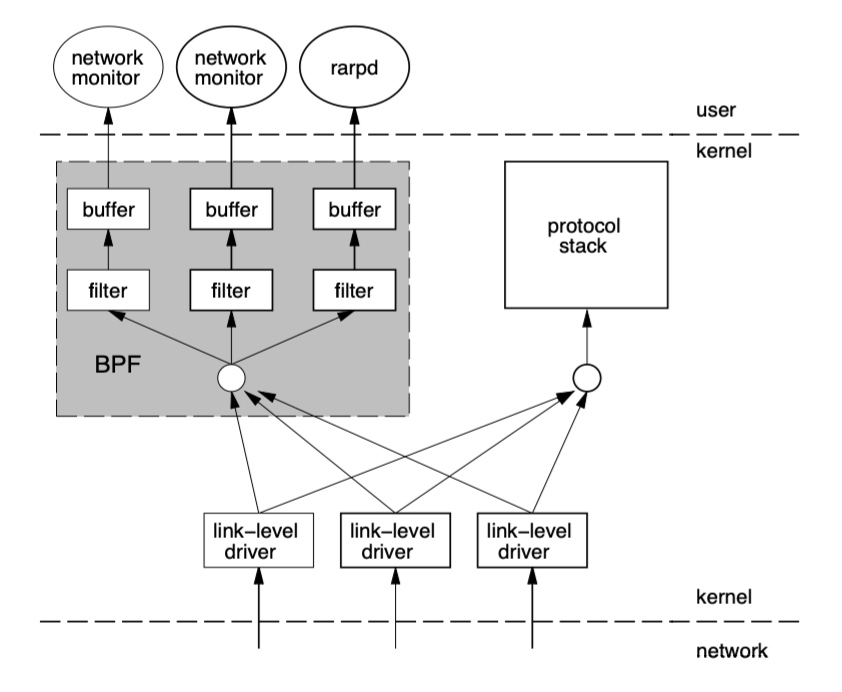
BPF
BPF(Berkeley Packet Filter ),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据;
由于这些巨大的改进,所有的 Unix 系统都选择采用 BPF 作为网络数据包过滤技术,直到今天,许多 Unix 内核的派生系统中(包括 Linux 内核)仍使用该实现。
下面是tcpdump的运行架构。
eBPF介绍
2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。
eBPF 扩展到用户空间,这也成为了 BPF 技术的转折点。eBPF 不再局限于网络栈,已经成为内核顶级的子系统。eBPF 程序架构强调安全性和稳定性,看上去更像内核模块,但与内核模块不同,eBPF 程序不需要重新编译内核,并且可以确保 eBPF 程序运行完成,而不会造成系统的崩溃。
下面是ebpf的简单架构,作基础介绍。
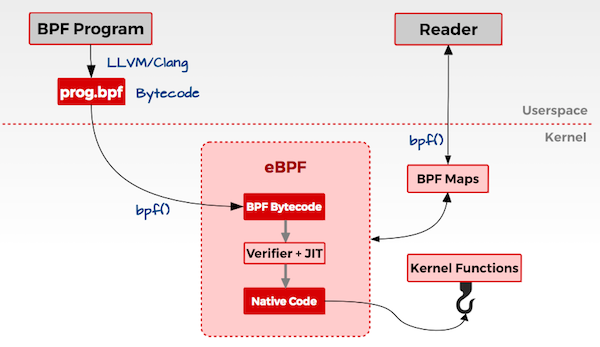
- 用户态
- 用户编写 eBPF 程序,可以使用 eBPF 汇编或者 eBPF 特有的 C 语言来编写。
- 使用 LLVM/CLang 编译器,将 eBPF 程序编译成 eBPF 字节码。
- 调用
bpf()系统调用把 eBPF 字节码加载到内核。
- 内核态
- 当用户调用
bpf()系统调用把 eBPF 字节码加载到内核时,内核先会对 eBPF 字节码进行安全验证。 - 使用
JIT(Just In Time)技术将 eBPF 字节编译成本地机器码(Native Code)。 - 然后根据 eBPF 程序的功能,将 eBPF 机器码挂载到内核的不同运行路径上(如用于跟踪内核运行状态的 eBPF 程序将会挂载在
kprobes的运行路径上)。当内核运行到这些路径时,就会触发执行相应路径上的 eBPF 机器码。
下面是ebpf的整体结构,这更为具体。
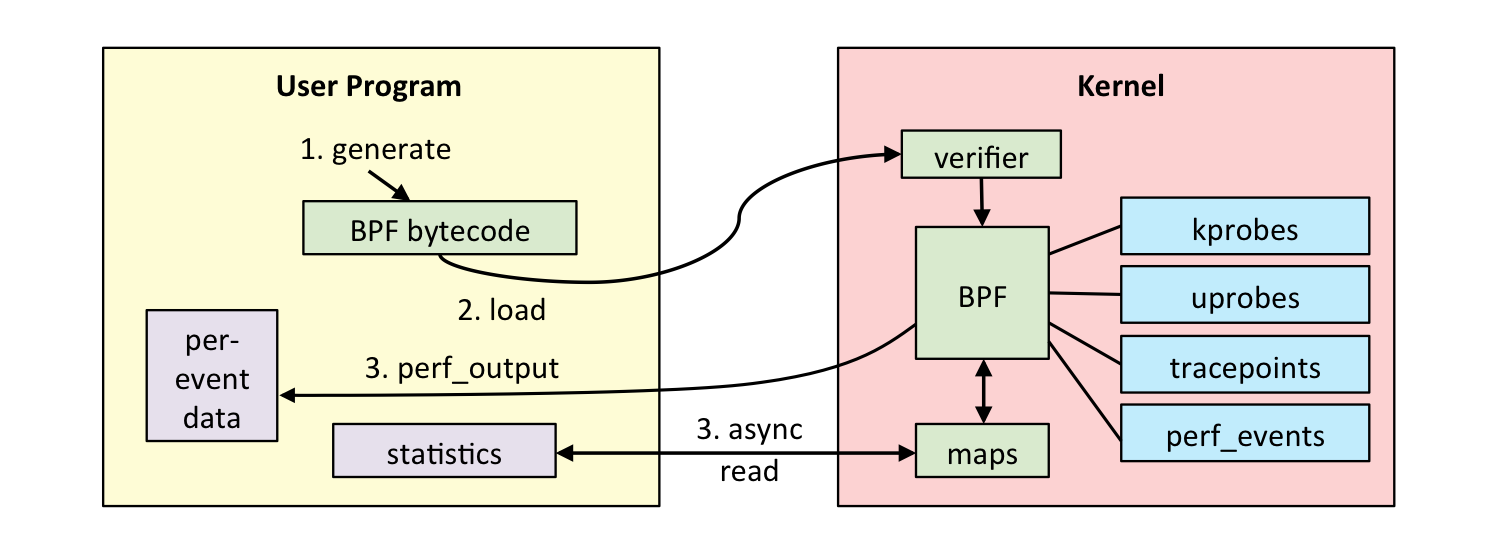
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载 BPF 字节码至内核,如需要也会负责读取内核回传的统计信息或者事件详情;
- 内核中的 BPF 字节码负责在内核中执行特定事件,如需要也会将执行的结果通过 maps 或者 perf-event 事件发送至用户空间;
其中用户空间程序与内核 BPF 字节码程序可以使用 map 结构实现双向通信,这为内核中运行的 BPF 字节码程序提供了更加灵活的控制。
用户空间程序与内核中的 BPF 字节码交互的流程主要如下:
- 可以使用 LLVM 或者 GCC 工具将编写的 BPF 代码程序编译成 BPF 字节码;
- 然后使用加载程序 Loader 将字节码加载至内核;内核使用验证器(verfier) 组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行;BPF 观测技术相关的程序程序类型可能是 kprobes/uprobes/tracepoint/perf_events 中的一个或多个,其中:
- kprobes:实现内核中动态跟踪。 kprobes 可以跟踪到 Linux 内核中的函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。
- uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪的函数为用户程序中的函数。
- tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
- perf_events:定时采样和 PMC。
- 内核中运行的 BPF 字节码程序可以使用两种方式将测量数据回传至用户空间
- maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间;
- perf-event 用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析。
eBPF 的限制
eBPF 技术虽然强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也给予了诸多限制,当然随着技术的发展和演进,限制也在逐步放宽或者提供了对应的解决方案。
- eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,函数支持列表也随着内核的演进在不断增加。(todo 添加个数说明)
- eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。
- eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
CNI插件
CNI的全称是 Container Network Interface,即容器网络的 API 接口。最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。其基本思想为:Container Runtime在创建容器时,先创建好network namespace,然后调用CNI插件为这个netns配置网络,其后再启动容器内的进程。现已加入CNCF,成为CNCF主推的网络模型。
背景
容器网络的配置是一个复杂的过程,为了应对各式各样的需求,容器网络的解决方案也多种多样,例如有flannel,calico,kube-ovn,weave等。同时,容器平台/运行时也是多样的,例如有Kubernetes,Openshift,rkt等。如果每种容器平台都要跟每种网络解决方案一一对接适配,这将是一项巨大且重复的工程。当然,聪明的程序员们肯定不会允许这样的事情发生。想要解决这个问题,我们需要一个抽象的接口层,将容器网络配置方案与容器平台方案解耦。
CNI(Container Network Interface)就是这样的一个接口层,它定义了一套接口标准,提供了规范文档以及一些标准实现。采用CNI规范来设置容器网络的容器平台不需要关注网络的设置的细节,只需要按CNI规范来调用CNI接口即可实现网络的设置。
功能
CNI插件负责将网络接口插入容器网络命名空间(例如,veth对的一端,bridge网桥),并在主机上进行任何必要的改变(例如将veth的另一端连接到网桥)。然后将IP分配给接口,并通过调用适当的IPAM插件来设置与“IP地址管理”部分一致的路由。
- 将容器添加至网络
- 将容器从网络中删除
- IP分配
DPU智能网卡
DPU(数据处理单元)
网卡发展
传统数据中心基于冯诺依曼架构,所有的数据都需要送到CPU进行处理。随着数据中心的高速发展,摩尔定律逐渐失效,CPU的增长速度无法满足数据的爆发式增长,CPU的处理速率已经不能满足数据处理的要求。计算架构从以CPU为中心的Onload模式,向以数据为中心的Offload模式转变,而给CPU减负的重任就落在了网卡(网络适配器)上,这也推动了网卡的高速发展;从服务器网卡的功能上看,可以分为三个阶段:
阶段1:基础功能网卡
基础功能网卡(即普通网卡)提供2x10G或2x25G带宽吞吐,具有较少的硬件卸载能力,主要是Checksum,LRO/LSO等,支持SR-IOV,以及有限的多队列能力。在云平台虚拟化网络中,基础功能网卡向虚拟机(VM)提供网络接入的方式主要是有三种:由操作系统内核驱动接管网卡并向虚拟机(VM)分发网络流量;由OVS-DPDK接管网卡并向虚拟机(VM)分发网络流量;以及高性能场景下通过SR-IOV的方式向虚拟机(VM)提供网络接入能力。
阶段2:硬件卸载网卡
在这种背景下,SmartNIC(智能网卡)应运而生。SmartNIC 技术诞生的初衷是以比普通CPU低得多的成本实现对各种虚拟化功能的支持,如SRIOV,overlay encap/decap,以及部分vSwitch处理逻辑的offload。在服务器侧引入智能网卡,将网络、存储、操作系统中不适合CPU处理的高性能数据处理功能卸载到硬件执行,提升数据处理能力,释放CPU算力。
阶段3:DPU智能网卡
传统智能网卡上没有CPU,需要Host CPU进行管理。传统智能网卡除了具备标准网卡的功能外,主要实现网络业务加速。随着网络速度的提高,传统智能网卡将消耗大量宝贵的CPU内核来进行流量的分类、跟踪和控制。
DPU的出现是为了解决数据中心中存在三个方面共五大问题:节点间:服务器数据交换效率低、数据传输可靠性低,节点内:数据中心模型执行效率低,I/O切换效率低、服务器架构不灵活,网络系统:不安全。
DPU区别于SmartNIC最显著的特点,DPU本身构建了一个新的网络拓扑,而不是简单的数据处理卸载计算;DPU可以脱离host CPU存在,而SmartNIC不行。这个本质的区别就是DPU可以构建自己的总线系统,从而控制和管理其他设备,也就是一个真正意义上的中心芯片。
传统智能网卡 vs DPU智能网卡
SmartNIC实现了部分卸载,即只卸载数据面,控制面仍然在Host CPU处理。从总体上来说SmartNIC的卸载操作是一个系统内的协作。
DPU实现了完全的卸载,服务器的数据面和控制面都卸载运行在DPU内部的嵌入式CPU中。DPU实现包括软件卸载和硬件加速两个方面,即将负载从Host CPU卸载到DPU的嵌入式CPU中,同时将负载数据面通过DPU内部的其他类型硬件加速引擎,如协处理器、GPU、FPGA、DSA等来处理。从总体上来说,DPU是两个系统间的协作,把一个系统卸载到另一个运行实体,然后通过特定的接口交互。
处理过程
主机上传统网卡处理报文的过程大致如下:
- 传统网卡接收来自网络或主机的数据包,并将其存储在网卡硬件缓存中。
- 传统网卡通过DMA(直接内存访问)将数据包从硬件缓存转移到服务器内存中的ring buffer,同时申请一个描述符指向数据包的物理地址。
- 传统网卡产生一个硬件中断,通知内核处理数据包。
- 内核根据中断号找到对应的中断处理函数,将数据包从ring buffer复制到socket buffer,并进行TCP/IP协议栈的逐层处理。
- 内核根据数据包的目标地址,将其转发到网络上的其他节点或者交给应用程序进行进一步的解析和处理。
主机上传统网卡与智能网卡或DPU智能网卡的区别在于,传统网卡依赖于CPU和内核进行数据包的处理,而智能网卡或DPU智能网卡可以在自身完成大部分网络功能,从而减少CPU和内核的负担。
主机上智能网卡处理过程:
主机上的智能网卡处理报文的过程大致如下:
- 智能网卡接收来自网络或主机的数据包,并对其进行解析、分类和过滤。
- 智能网卡根据数据包的类型和目标,执行相应的网络功能,如路由、转发、加密、负载均衡等。
- 智能网卡将处理后的数据包发送到目标地址,无论是网络上的其他节点还是主机内的其他设备。
- 智能网卡通过DMA(直接内存访问)将数据保存到主机内存中,并通知CPU处理。
- CPU通过中断或轮询的方式检查智能网卡的状态,并从内存中读取数据。
- CPU将数据交给应用层软件进行进一步的解析和处理。
主机上的智能网卡与DPU智能网卡的区别在于,主机上的智能网卡仍然依赖于CPU和内存进行数据处理,而DPU智能网卡可以独立于CPU和内存存在和运行。
主机上DPU智能网卡处理过程:
主机上的DPU智能
网卡处理报文的过程大致如下:
- DPU接收来自网络或主机的数据包,并对其进行解析、分类和过滤。
- DPU根据数据包的类型和目标,执行相应的网络功能,如路由、转发、加密、负载均衡等。
- DPU将处理后的数据包发送到目标地址,无论是网络上的其他节点还是主机内的其他设备。
- DPU通过自己的总线系统,管理和控制与主机或网络连接的其他设备,如存储、加速器等。
- DPU将数据处理/预处理结果发送给主机CPU,或者直接将数据发送给算力分布在更靠近数据源端的边缘计算节点。
主机上的DPU智能网卡与DPU智能网卡相同之处在于,它们都可以独立于CPU和内存存在和运行,并且都可以构建一个新的网络拓扑。主机上的DPU智能网卡与DPU智能网卡不同之处在于,它们所连接的设备类型和位置不同。
RDMA
参考:RDMA技术详解(一):RDMA概述 - 知乎 (zhihu.com)、来点硬核的:什么是RDMA? - 腾讯云开发者社区-腾讯云 (tencent.com)
背景
RDMA(RemoteDirect Memory Access)技术全称远程直接内存访问,是为了解决网络传输中服务器端数据处理的延迟而产生的。它将数据直接从一台计算机的内存传输到另一台计算机内存,无需双方操作系统的介入。这允许高吞吐、低延迟的网络通信,尤其适合在大规模并行计算机集群中使用。
传统TCP/IP通信模式
- 内核空间协议栈拷贝以及内核空间喝用户空间的上下文切换开销:
传统的TCP/IP网络通信,数据需要通过用户空间发送到远程机器的用户空间。数据发送方需要讲数据从用户应用空间Buffer复制到内核空间的Socket Buffer中。然后Kernel空间中添加数据包头,进行数据封装。通过一系列多层网络协议的数据包处理工作,这些协议包括传输控制协议(TCP)、用户数据报协议(UDP)、互联网协议(IP)以及互联网控制消息协议(ICMP)等,数据才被Push到NIC网卡中的Buffer进行网络传输。消息接受方接受从远程机器发送的数据包后,要将数据包从NIC buffer中复制数据到Socket Buffer。然后经过一些列的多层网络协议进行数据包的解析工作。解析后的数据被复制到相应位置的用户应用空间Buffer。这个时候再进行系统上下文切换,用户应用程序才被调用。以上就是传统的TCP/IP协议层的工作。如今随着社会的发展,我们希望更快和更轻量级的网络通信。
- 当前以小消息的发送为主,处理开销占主导地位:
当今随着计算机网络的发展。消息通信主要分为两类消息,一类是Large messages,在这类消息通信中,网络传输延迟占整个通信中的主导位置。还有一类消息是Small messages,在这类消息通信中,消息发送端和接受端的处理开销占整个通信的主导地位。然而在现实计算机网络中的通信场景中,主要是以发送小消息为主。所有说发送消息和接受消息的处理开销占整个通信的主导的地位。具体来说,处理开销指的是buffer管理、在不同内存空间中消息复制、以及消息发送完成后的系统中断。
- 瓶颈在于消息经过内核进行一系列移动和复制:
传统的TPC/IP存在的问题主要是指I/O bottleneck瓶颈问题。在高速网络条件下与网络I/O相关的主机处理的高开销限制了可以在机器之间发送的带宽。这里感兴趣的高额开销是数据移动操作和复制操作。具体来讲,主要是传统的TCP/IP网络通信是通过内核发送消息。Messaging passing through kernel这种方式会导致很低的性能和很低的灵活性。性能低下的原因主要是由于网络通信通过内核传递,这种通信方式存在的很高的数据移动和数据复制的开销。并且现如今内存带宽性相较如CPU带宽和网络带宽有着很大的差异。很低的灵活性的原因主要是所有网络通信协议通过内核传递,这种方式很难去支持新的网络协议和新的消息通信协议以及发送和接收接口。
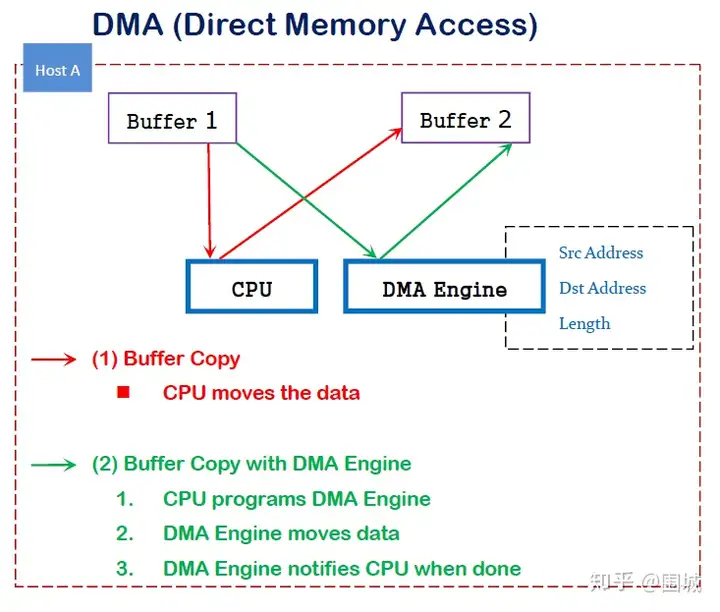
DMA简介
DMA(直接内存访问)是一种能力,允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与。
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。
RDMA简介
RDMA是一种概念,在两个或者多个计算机进行通讯的时候使用DMA, 从一个主机的内存直接访问另一个主机的内存。
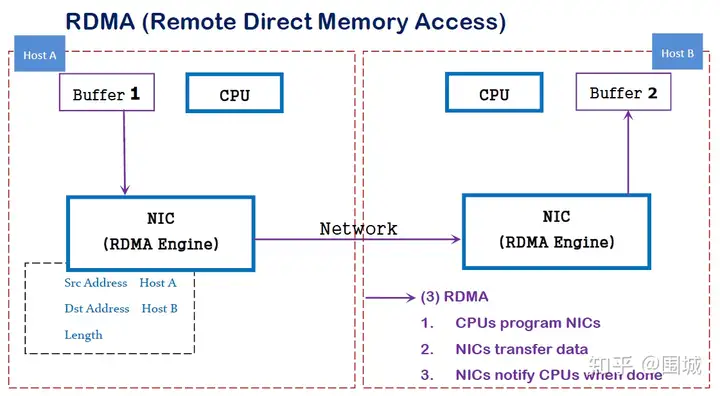
在实现上,RDMA实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过将RDMA协议固化于硬件(即网卡)上,以及支持Zero-copy和Kernel bypass这两种途径来达到其高性能的远程直接数据存取的目标。 使用RDMA的优势如下:
- 零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- 消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- 支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
在具体的远程内存读写中,RDMA操作用于读写操作的远程虚拟内存地址包含在RDMA消息中传送,远程应用程序要做的只是在其本地网卡中注册相应的内存缓冲区。远程节点的CPU除在连接建立、注册调用等之外,在整个RDMA数据传输过程中并不提供服务,因此没有带来任何负载。
DPDK
转自:DPDK的基本原理、学习路线总结 - 知乎 (zhihu.com)
背景
网络设备(路由器、交换机、媒体网关、SBC、PS网关等)需要在瞬间进行大量的报文收发,因此在传统的网络设备上,往往能够看到专门的NP(Network Process)处理器,有的用FPGA,有的用ASIC。这些专用器件通过内置的硬件电路(或通过编程形成的硬件电路)高效转发报文,只有需要对报文进行深度处理的时候才需要CPU干涉。
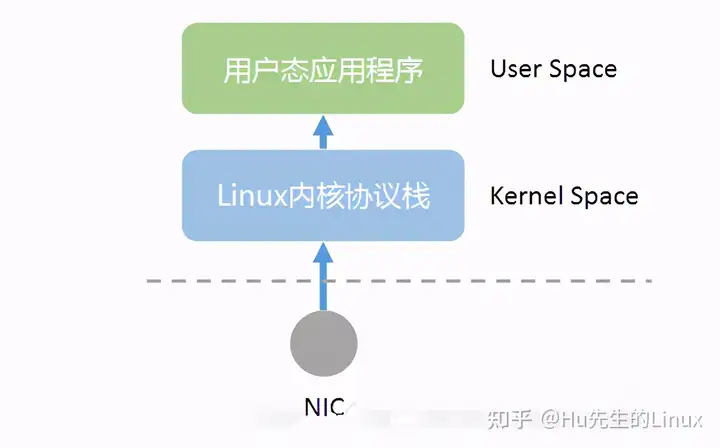
但在公有云、NFV等应用场景下,基础设施以CPU为运算核心,往往不具备专用的NP处理器,操作系统也以通用Linux为主,网络数据包的收发处理路径如下图所示:
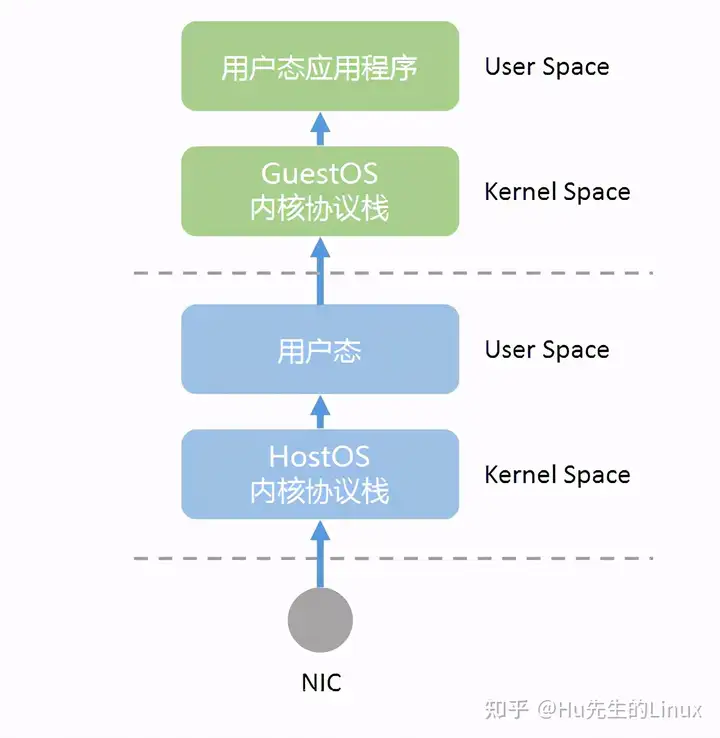
在虚拟化环境中,路径则会更长:
由于包处理任务存在内核态与用户态的切换,以及多次的内存拷贝,系统消耗变大,以CPU为核心的系统存在很大的处理瓶颈。为了提升在通用服务器(COTS)的数据包处理效能,Intel推出了服务于IA(Intel Architecture)系统的DPDK技术。
原理介绍
DPDK是Data Plane Development Kit(数据平面开发套件)的缩写。简单说,DPDK应用程序运行在操作系统的User Space,利用自身提供的数据面库进行收发包处理,绕过了Linux内核态协议栈,以提升报文处理效率。
DPDK是一组lib库和工具包的集合。最简单的架构描述如下图所示:
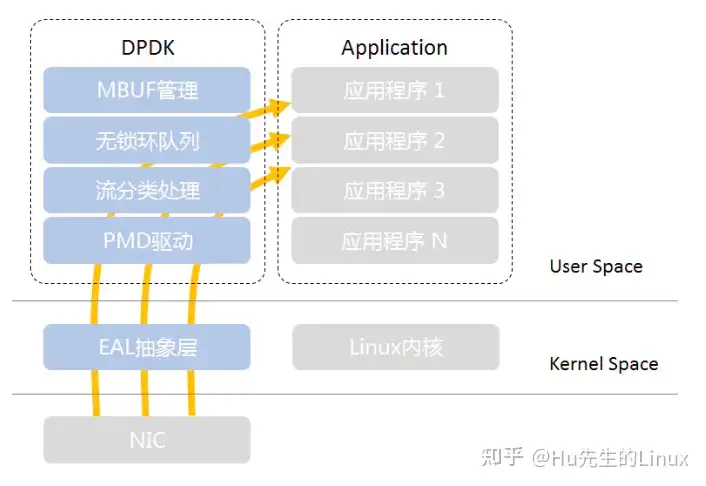
上图蓝色部分是DPDK的主要组件(更全面更权威的DPDK架构可以参考Intel官网),简单解释一下:
- PMD:Pool Mode Driver,轮询模式驱动,通过非中断,以及数据帧进出应用缓冲区内存的零拷贝机制,提高发送/接受数据帧的效率
- 流分类:Flow Classification,为N元组匹配和LPM(最长前缀匹配)提供优化的查找算法
- 环队列:Ring Queue,针对单个或多个数据包生产者、单个数据包消费者的出入队列提供无锁机制,有效减少系统开销
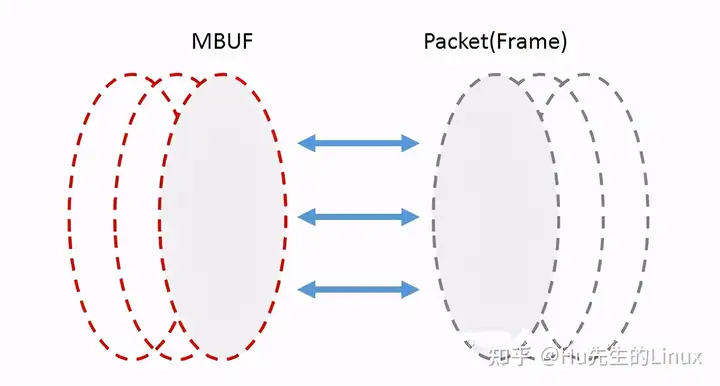
- MBUF缓冲区管理:分配内存创建缓冲区,并通过建立MBUF对象,封装实际数据帧,供应用程序使用
- EAL:Environment Abstract Layer,环境抽象(适配)层,PMD初始化、CPU内核和DPDK线程配置/绑定、设置HugePage大页内存等系统初始化
总结一下DPDK的核心思想:
- 用户态模式的PMD驱动,去除中断,避免内核态和用户态内存拷贝,减少系统开销,从而提升I/O吞吐能力
- 用户态有一个好处,一旦程序崩溃,不至于导致内核完蛋,带来更高的健壮性
- HugePage,通过更大的内存页(如1G内存页),减少TLB(Translation Lookaside Buffer,即快表) Miss,Miss对报文转发性能影响很大
- 多核设备上创建多线程,每个线程绑定到独立的物理核,减少线程调度的开销。同时每个线程对应着独立免锁队列,同样为了降低系统开销
- 向量指令集,提升CPU流水线效率,降低内存等待开销
下图简单描述了DPDK的多队列和多线程机制:
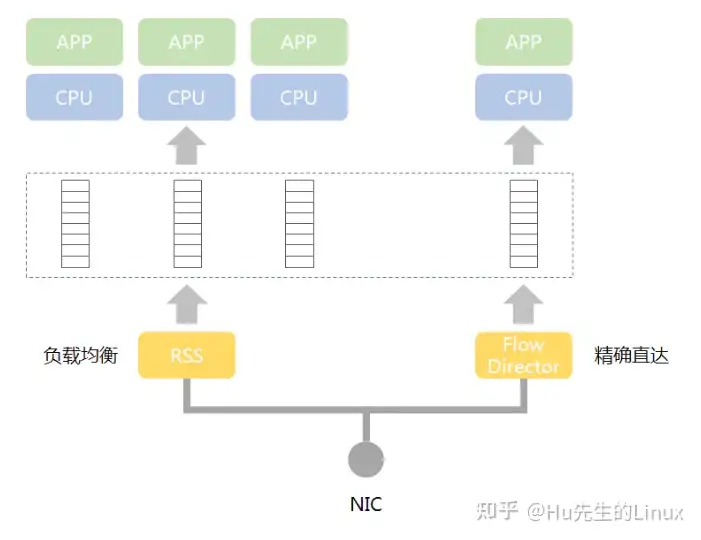
DPDK将网卡接收队列分配给某个CPU核,该队列收到的报文都交给该核上的DPDK线程处理。存在两种方式将数据包发送到接收队列之上:
- RSS(Receive Side Scaling,接收方扩展)机制:根据关键字,比如根据UDP的四元组
进行哈希 - Flow Director机制:可设定根据数据包某些信息进行精确匹配,分配到指定的队列与CPU核
当网络数据包(帧)被网卡接收后,DPDK网卡驱动将其存储在一个高效缓冲区中,并在MBUF缓存中创建MBUF对象与实际网络包相连,对网络包的分析和处理都会基于该MBUF,必要的时候才会访问缓冲区中的实际网络包