简介
不是全面的面经,主要是针对我自己的一个查缺补漏,涉及的知识算比较深入的。
内容包括:C++、操作系统、计算机网络、Linux内核、少量数据库MySQL;以及业务上的一些问题,比如安全、高并发、缓存等。
学习补充
面阿里云时有电话录音记得比较清楚
阿里云云网络一面学习补充
免费ARP
ARP协议详解之Gratuitous ARP(免费ARP) - 大学霸 - 博客园 (cnblogs.com)
Gratuitous ARP也称为免费ARP,无故ARP。Gratuitous ARP不同于一般的ARP请求,它并非期待得到IP对应的MAC地址,而是当主机启动的时候,将发送一个Gratuitous arp请求,即请求自己的IP地址的MAC地址。免费ARP数据包是主机发送ARP查找自己的IP地址。
1.验证IP是否冲突
一个主机可以通过它来确定另一个主机是否设置了相同的IP地址。发送主机并不需要一定收到此请求的回答。如果收到一个回答,表示网络中存在与自身IP相同的主机。如果没有收到应答,则表示本机所使用的IP与网络中其它主机并不冲突。
2.更换物理网卡
如果发送ARP的主机正好改变了物理地址(如更换物理网卡),可以使用此方法通知网络中其它主机及时更新ARP缓存。其他主机接收到这个ARP请求的时候,发现自己的ARP高速缓存表中存在对应的IP地址,但是MAC地址不匹配,那么就需要利用接收的ARP请求来更新本地的ARP高速缓存表表项。
3.网关定期刷新
这个主要是用在网关设备(如路由器)上。网关定期发布免费ARP,告诉网内所有主机自己的IP–MAC对应关系,让网内主机定期收到这个免费ARP请求,进而重置ARP老化时间等
网卡收发过程
网卡适配器收发数据帧流程 - 云物互联 - 博客园 (cnblogs.com)
收包
- 首先,内核在 RAM 中为收发数据建立一个环形的缓冲队列,通常叫 DMA 环形缓冲区,又叫 BD(Buffer descriptor)表。
- 内核将这个缓冲区通过 DMA 映射,把这个队列交给网卡;
- 网卡收到数据,就直接放进这个环形缓冲区,也就是直接放进 RAM 了;
- 然后,网卡驱动向系统产生一个中断,内核收到这个中断,就取消 DMA 映射,这样,内核就直接从主内存中读取数据;
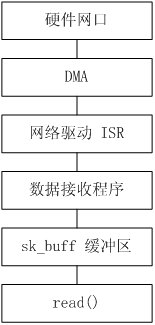
如何将网卡收到的数据写入到内核内存?
在通信程序中,经常使用环形缓冲器作为数据结构来存放通信中发送和接收的数据。环形缓冲区是一个先进先出的循环缓冲区,可以向通信程序提供对缓冲区的互斥访问。
圆形缓冲区的一个有用特性是:当一个数据元素被用掉后,其余数据元素不需要移动其存储位置。相反,一个非圆形缓冲区(例如一个普通的队列)在用掉一个数据元素后,其余数据元素需要向前搬移。换句话说,圆形缓冲区适合实现先进先出缓冲区,而非圆形缓冲区适合后进先出缓冲区。
NIC在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是rx ring buffer((40条消息) 环形缓冲区(Ring Buffer)使用说明_爬坡的小蜗牛的博客-CSDN博客_环形buffer)。它是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
1、驱动在内存中分配一片缓冲区用来接收数据包,叫做sk_buffer;
2、将上述缓冲区的地址和大小(即接收描述符),加入到rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址;
3、驱动通知网卡有一个新的描述符;
4、网卡从rx ring buffer中取出描述符,从而获知缓冲区的地址和大小;
5、网卡收到新的数据包;
6、网卡将新数据包通过DMA直接写到sk_buffer中。
发包
- 用户态应用程序(应用层)可以通过系统调用接口访问 Socket 层,传递给 Socket 的数据首先会保存在 sk_buff (sk_buff结构体中的都是sk_buff的控制信息,是网络数据包的一些配置,真正储存数据的是sk_buff结构体中几个指针指向的数据区中)对应的缓冲区中
- 当数据被储存到了 sk_buff 缓存区中,网卡驱动的发送函数 hard_start_xmit 也随之被调用
- 通过DMA发送到网卡
详细:
- 网卡驱动创建 Tx descriptor ring,将 Tx descriptor ring 的总线地址写入网卡寄存器 TDBA。(rx和tx是两个环形缓冲,负责读写)
- 协议栈通过
dev_queue_xmit()将 sk_buffer 下送到网卡驱动。 - 网卡驱动将 sk_buff 放入 Tx descriptor ring,更新网卡寄存器 TDT。
- 感知到 TDT 的改变后,网卡找到 Tx descriptor ring 中下一个将要使用的 descriptor。
- DMA 通过 PCI 总线将 descriptor 的数据缓存区复制到 Tx FIFO。
- 复制完后,通过 MAC 芯片将数据包发送出去。
- 发送完后,网卡更新网卡寄存器 TDH,启动硬中断通知 CPU 释放数据缓存区中的数据包。
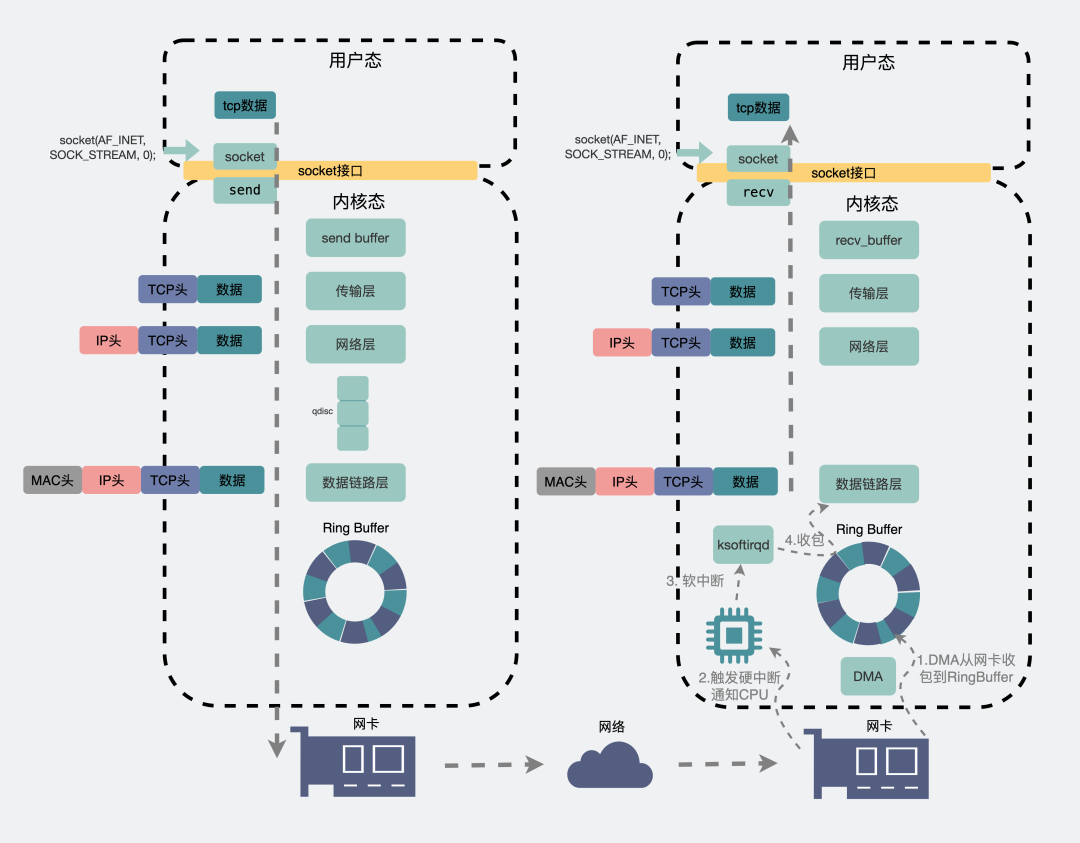
vxlan里ARP是怎么转发的
简单来说就是包在vxlan标头里转发,A先广播,隧道端点知道要走隧道就转发出去,另一边解封后发现地址是广播地址就广播ARP,响应是单播的
(40条消息) 带你了解VXLAN网络中报文的转发机制_华为云开发者联盟的博客-CSDN博客_vxlan集中部署模式下,哪一类流量不经过核心转发
如图1-12所示,VM_A、VM_B和VM_C同属于10.1.1.0/24网段,且同属于VNI 5000。此时,VM_A想与VM_C进行通信。
由于是首次进行通信,VM_A上没有VM_C的MAC地址,所以会发送ARP广播报文请求VM_C的MAC地址。
图1-12 同子网VM互通组网图
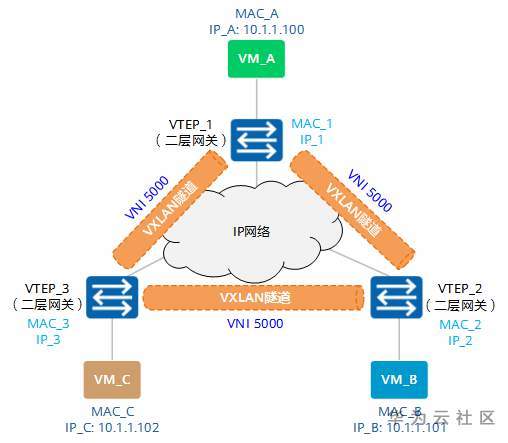
下面就让我们根据ARP请求报文及ARP应答报文的转发流程,来看下MAC地址是如何进行学习的。
ARP请求报文转发流程
结合图1-13,我们来一起了解一下ARP请求报文的转发流程。
图1-13 ARP请求报文转发流程示意
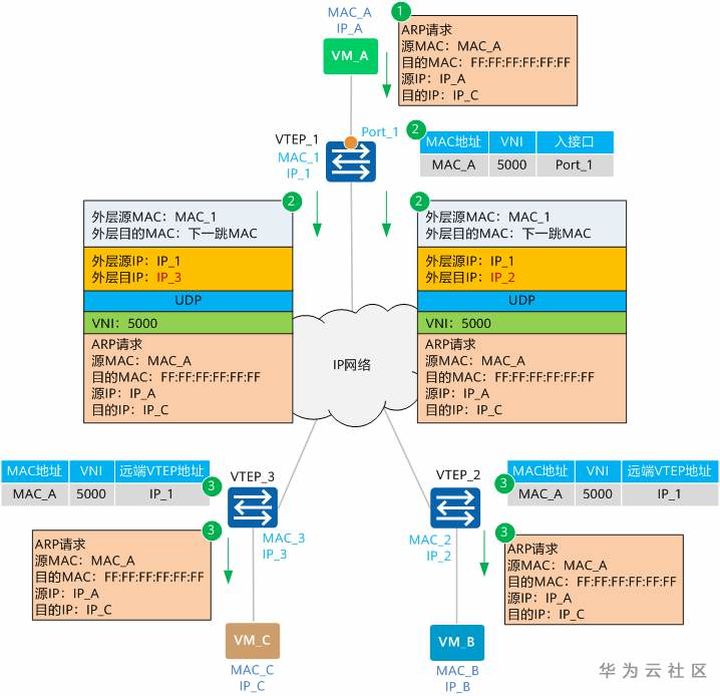
VM_A发送源MAC为MAC_A、目的MAC为全F、源IP为IP_A、目的IP为IP_C的ARP广播报文,请求VM_C的MAC地址。
VTEP_1收到ARP请求后,根据二层子接口上的配置判断报文需要进入VXLAN隧道。确定了报文所属BD后,也就确定了报文所属的VNI。同时,VTEP_1学习MAC_A、VNI和报文入接口(Port_1,即二层子接口对应的物理接口)的对应关系,并记录在本地MAC表中。之后,VTEP_1会根据头端复制列表对报文进行复制,并分别进行封装。
可以看到,这里封装的外层源IP地址为本地VTEP(VTEP_1)的IP地址,外层目的IP地址为对端VTEP(VTEP_2和VTEP_3)的IP地址;外层源MAC地址为本地VTEP的MAC地址,而外层目的MAC地址为去往目的IP的网络中下一跳设备的MAC地址。封装后的报文,根据外层MAC和IP信息,在IP网络中进行传输,直至到达对端VTEP。
报文到达VTEP_2和VTEP_3后,VTEP对报文进行解封装,得到VM_A发送的原始报文。同时,VTEP_2和VTEP_3学习VM_A的MAC地址、VNI和远端VTEP的IP地址(IP_1)的对应关系,并记录在本地MAC表中。之后,VTEP_2和VTEP_3根据二层子接口上的配置对报文进行相应的处理并在对应的二层域内广播。
VM_B和VM_C接收到ARP请求后,比较报文中的目的IP地址是否为本机的IP地址。VM_B发现目的IP不是本机IP,故将报文丢弃;VM_C发现目的IP是本机IP,则对ARP请求做出应答。下面,让我们看下ARP应答报文是如何进行转发的。
ARP应答报文转发流程
结合图1-14,我们来一起了解一下ARP应答报文的转发流程。
图1-14 ARP应答报文转发流程示意

由于此时VM_C上已经学习到了VM_A的MAC地址,所以ARP应答报文为单播报文。报文源MAC为MAC_C,目的MAC为MAC_A,源IP为IP_C、目的IP为IP_A。
VTEP_3接收到VM_C发送的ARP应答报文后,识别报文所属的VNI(识别过程与步骤②类似)。同时,VTEP_3学习MAC_C、VNI和报文入接口(Port_3)的对应关系,并记录在本地MAC表中。之后,VTEP_3对报文进行封装。
可以看到,这里封装的外层源IP地址为本地VTEP(VTEP_3)的IP地址,外层目的IP地址为对端VTEP(VTEP_1)的IP地址;外层源MAC地址为本地VTEP的MAC地址,而外层目的MAC地址为去往目的IP的网络中下一跳设备的MAC地址。
封装后的报文,根据外层MAC和IP信息,在IP网络中进行传输,直至到达对端VTEP。
报文到达VTEP_1后,VTEP_1对报文进行解封装,得到VM_C发送的原始报文。同时,VTEP_1学习VM_C的MAC地址、VNI和远端VTEP的IP地址(IP_3)的对应关系,并记录在本地MAC表中。之后,VTEP_1将解封装后的报文发送给VM_A。
至此,VM_A和VM_C均已学习到了对方的MAC地址。之后,VM_A和VM_C将采用单播方式进行通信。
ARP广播抑制与代答
[VXLAN中ARP广播抑制 - CloudEngine 16800 V200R020C10 配置指南-VXLAN - 华为 (huawei.com)](https://support.huawei.com/enterprise/zh/doc/EDOC1100198462/c7801b0d#:~:text=VXLAN中ARP广播抑制 1 Server1发送ARP请求报文,请求目的主机Server2的MAC地址。 2 作为VXLAN二层网关的Device1收到ARP请求报文后,查询主机信息。 如果主机信息中有目的主机信息,Device1将ARP请求报文中的广播目的MAC地址和Target MAC地址替换为目的主机的MAC地址,并进行VXLAN封装后转发。 …,3 作为VXLAN二层网关的Device2收到封装后的ARP请求报文进行VXLAN解封装获取内层二层报文,判断报文的目的MAC是否为广播地址。 是,在对应的二层广播域内非VXLAN网络侧进行广播处理。 … 4 目的主机Server2收到单播ARP请求报文后,进行ARP应答。 5 Server1收到ARP应答报文建立ARP缓存表,并可以与Server2通信。)
为了抑制ARP广播请求报文给网络带来的广播风暴,可在VXLAN二层网关设备上使能广播抑制功能。
如图所示,VXLAN三层网关通过动态学习终端租户的ARP表项,再根据ARP表项生成主机信息(包括主机IP地址、MAC地址、VTEP地址和VNI ID),并将主机信息通过BGP EVPN对外发布,使其他的BGP邻居可以学习到主机信息。VXLAN二层网关学习到的主机信息用于广播抑制。
Server1初次访问Server2时,Server1会向Server2发送ARP广播请求报文,请求目的主机Server2的MAC地址,具体实现过程如下:
- Server1发送ARP请求报文,请求目的主机Server2的MAC地址。
- 作为VXLAN二层网关的Device1收到ARP请求报文后,查询主机信息。
- 如果主机信息中有目的主机信息,Device1将ARP请求报文中的广播目的MAC地址和Target MAC地址替换为目的主机的MAC地址,并进行VXLAN封装后转发。(广播抑制)
- 如果主机信息中没有目的主机信息,ARP请求报文中的广播目的MAC地址不变,Device1进行VXLAN封装后转发。
- 作为VXLAN二层网关的Device2收到封装后的ARP请求报文进行VXLAN解封装获取内层二层报文,判断报文的目的MAC是否为广播地址。
- 是,在对应的二层广播域内非VXLAN网络侧进行广播处理。
- 不是,发送给对应的目的主机。
- 目的主机Server2收到单播ARP请求报文后,进行ARP应答。
- Server1收到ARP应答报文建立ARP缓存表,并可以与Server2通信。

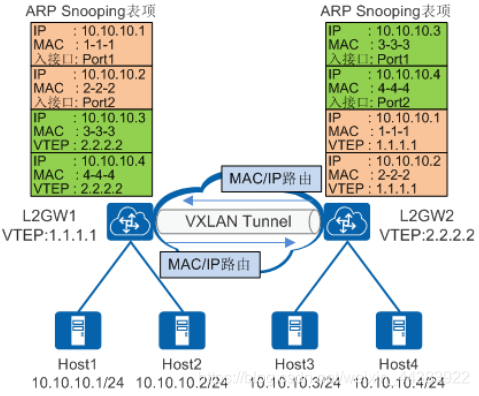
代答
注意,广播抑制是用三层网关学习到的主机信息,代答是用隧道端点自己的ARP表。
当二层网关设备再收到ARP请求报文时,设备首先根据报文中的目的IP查找本地的ARP Snooping表项(包括本地侦听的和从其他网关同步的):
- 如果查找成功,则用查找到的信息对ARP请求报文直接进行代答。
- 如果查找失败,则按原有的流程处理该ARP请求报文。
阿里云云网络二面学习补充
静态绑定和动态绑定,就是编译期确定(重载、模板)和运行期确定(虚函数)
vlan
- 机数目较多时会导致冲突严重、广播泛滥、性能显著下降甚至造成网络不可用等问题。通过二层设备实现LAN互连虽然可以解决冲突严重的问题,但仍然不能隔离广播报文和提升网络质量。在这种情况下出现了VLAN技术。这种技术可以把一个LAN划分成多个逻辑的VLAN,每个VLAN是一个广播域,VLAN内的主机间通信就和在一个LAN内一样,而VLAN间则不能直接互通,广播报文就被限制在一个VLAN内。
- 标签位置:在以太网帧的type字段。在以太网数据帧中加入4个字节的VLAN标签(又称VLAN Tag,简称Tag),用以标识VLAN信息。
有了vlan为什么还需要vxlan:(40条消息) 为什么需要VXLAN ?和VLAN有什么区别 ?_阿苏呐的博客-CSDN博客
TOS
- TOS是IPV4协议头部中的一个8bits的字段,ToS即为服务类型,只有当网络设备能够支持(能够识别IP首部中的ToS字段)识别ToS字段时,这给字段设置才有意义
- 3bits优先级(貌似已废弃),即8个优先级,比如【关键】、【疾速】、【普通】等等,优先级对应的应用级别就像音视频、普通数据等
- 4bits是服务类型,1000 – minimize delay 最小延迟、0100 – maximize throughput 最大吞吐量、0010 – maximize reliability 最高可靠性、0001 – minimize monetary cost 最小费用、0000 – normal service 一般服务
- 1bit末尾,没有被使用,必须强制设置为0
IPV6没有ARP协议,用NDP协议(邻居发现协议)
输出hello world内核具体是怎么执行的
为了调用系统调用,产生中断,CPU保存上下文信息,从用户态切换到内核态,将堆栈切换到内核栈
查找中断符号表,获取中断处理程序地址
执行write()函数
恢复被中断进程的CPU现场信息,返回被中断进程,继续运行
中断
中断是指由于接收到来自外围硬件(相对于中央处理器和内存)的异步信号或来自软件的同步信号,而进行相应的硬件/软件处理。发出这样的信号称为进行中断请求(interrupt request,IRQ)。
硬件中断导致处理器通过一个上下文切换(context switch)来保存执行状态(以程序计数器和程序状态字等寄存器信息为主);软件中断则通常作为CPU指令集中的一个指令,以可编程的方式直接指示这种上下文切换,并将处理导向一段中断处理代码。
硬件中断和软件中断是两种不同的中断方式。硬件中断是由外部设备向处理器发送信号来请求中断服务,而软件中断是由处理器内部执行指令来产生的。
- 硬件中断的优点是可以实现异步通信,即外部设备不需要等待处理器的空闲时间,而是在需要时就发出请求。硬件中断的缺点是需要使用专门的硬件设备,如中断控制器,来识别和分配不同的中断源,并且可能会影响处理器的正常执行流程。
- 软件中断的优点是可以实现同步通信,即处理器可以在合适的时机主动调用中断服务程序,而不受外部设备的干扰。软件中断的缺点是需要使用特定的指令来触发,并且不能屏蔽或忽略。
对称加密与非对称加密(通俗易懂的对称加密与非对称加密原理浅析 - 掘金 (juejin.cn))
- 对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密。
- 非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
- 由于加密和解密使用了两个不同的密钥,这就是非对称加密“非对称”的原因。非对称加密的缺点是加密和解密花费时间长、速度慢,只适合对少量数据进行加密。
http与https
- http是明文传输,报文给截了就泄密了
- https在内容上是对称加密,在证书验证上是非对称加密,SSL就是证书,验证证书是验证有没有过期、机构对不对啥的
- 从安全性来说,我们从加密过程可以很明显看出来非对称加密安全性要高很多,原因是如果采用对称加密,秘钥有可能在开始阶段由主动方发出时被黑客截获,后面任何加密信息将失去保密效果 ,而如果采用非对称加密,那么黑客即使截获了公钥,也没有任何作用,因为只有掌握在通讯双方手中的私钥才是揭开密文的唯一“钥匙”。而从性能的角度来说,由于非对称加密所涉及到的算法更加复杂,因此,非对称加密的性能会比对称加密差一些,因此,在选择加密方式的时候,我们不只是一味全盘使用非对称加密,而应该在不影响安全性的情况下,果断选择对称加密代替复杂的非对称加密,以此来提高性能。
- 分析完两种加密方式的利弊,那么 HTTPS 究竟是怎么选择的呢? HTTPS 选择了两种混用,如图,由于 HTTPS 涉及到大量的接口、数据等非常频繁的操作行为,所以如果一概采用非对称加密的话,会严重影响 HTTPS 的性能,因此传输的数据的加密方式应该采用对称加密,而对称加密的秘钥在通讯两端同步的时候容易被截获,因此,HTTPS 采用非对称加密的方式来对该对称秘钥进行传输。通过这两种加密方式的结合,HTTPS 有效地避免性能损耗的同时,也让数据传输安全性得到了保障
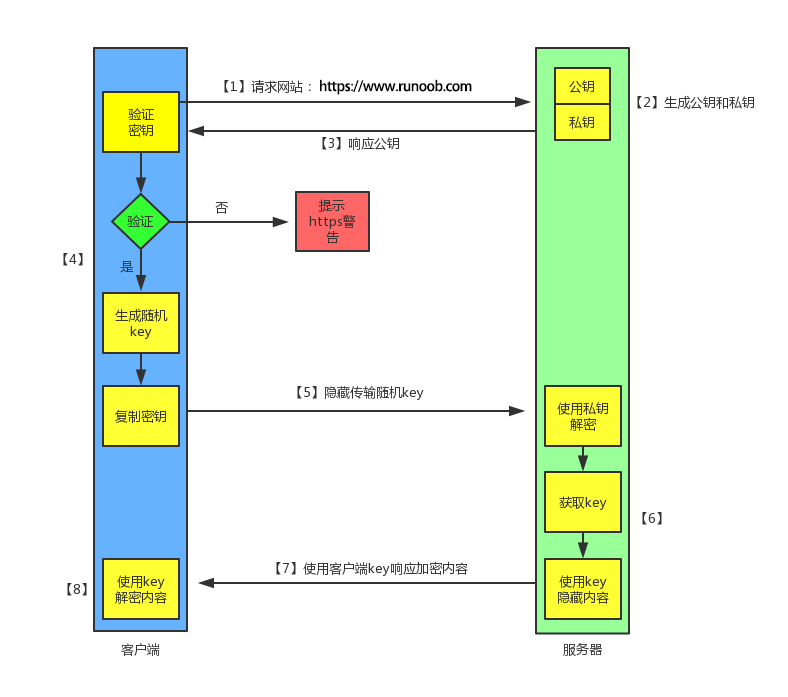
简单说一下就是,服务器有证书,就是一对公钥和私钥。服务器把公钥给客户端,客户端先验证,验证通过后生成随机的密钥,密钥通过公钥加密,服务器用私钥把密钥解密,这样双方就同步了密钥,接下来就是对称加密。
C++
C++ exception的底层原理
异常处理可以在调用跳级。这是一个代码编写时的问题:假设在有多个函数的调用栈中出现了某个错误,使用整型返回码要求你在每一级函数中都要进行处理。而使用异常处理的栈展开机制,只需要在一处进行处理就可以了,不需要每级函数都处理。
- 栈展开:如果在一个函数内部抛出异常(throw),而此异常并未在该函数内部被捕捉(catch),就将导致该函数的运行在抛出异常处结束,所有已经分配在栈上的局部变量都要被释放。然后会接着向下线性的搜索函数调用栈,来寻找异常处理者,并且带有异常处理的函数(也就是有catch捕捉到)之前的所有实体(每级函数),都会从函数调用栈中删除。
函数中的局部变量、返回地址、寄存器中不够存储的参数等等都是存储在栈中的,每个函数中的这些信息组合起来称为一个栈帧(stack frame)。函数调用完后,栈指针将会指向上一个栈帧,而调用完的函数所在的栈帧将会消亡,其中所有的局部变量都失效,如果有指针指向其中的局部变量,对该指针的使用将会造成未定义的行为。
对于C++中的类,其中的数据成员类似结构体,成员函数类似普通的函数,唯一的不同就是需要传入this指针。哪怕是含有virtual函数的类,其结构中多了vptr虚表指针,这样的类也能一如常规的方式存放在栈帧里。
而存在异常处理的函数的栈帧与传统栈帧不同。它在栈帧中存在一个保存异常处理相关信息的结构体EXP,这个结构体是编译器生成的。假如存在如下的函数调用栈funA->funB->funC(a->b表示a调用b),由于EXP是链式存储的,而且异常捕获的原则是调用栈更近的catch块优先,因此funC.EXP.pre->funB.EXP(子函数的EXP指向调用它的函数的EXP)。EXP中有一个指针指向了一个处理异常相关的结构体EHDL,EHDL中保存了两个表:
- tblUnwind,其中存放了栈展开过程中需要销毁的对象指针及其析构函数指针
- tblTryBlocks,其中存放了try块的开始、结束位置,以及该try块对应的catch块表
捕获:当程序抛出异常后,首先在栈捕获表tblTryBlocks中,对其中每一个保存的try块信息,查看抛出异常的位置是否在try块的覆盖范围内。如果在,查看try块对应的catch块表,是否有匹配的catch块;如果不在,查看下一个try块;如果该栈帧的try块或catch块遍历完了还没有找到匹配的catch块,则说明该函数未能捕获异常,异常将交给调用它的函数来解决。因此当前函数后面的内容将不会得到执行,而且局部类变量将被析构,这时需要用到栈展开来析构类变量。
栈展开:在栈展开表tblUnwind中,对其中保存的每个局部类对象(内置类型无需析构)通过保存的析构函数指针调用析构函数。这也是不能让异常逃离析构函数的原因,发生异常会进行栈展开,栈展开时会调用析构函数,如果这时候再遇到异常,异常处理的结构便会被破坏,程序将会终止。所有局部变量都被成功析构后,异常处理结构体利用指针指向上一个节点,处理上一个函数。
智能指针管理数组
有两种方式:shared_ptr和unique_ptr。
首先我们介绍一下两中方式的不同:
- shared_ptr不支持下标访问,成员访问只能通过get获取指针后再去访问成员
- shared_ptr定义的数组需要指定deleter,因为shared_ptr的默认deleter是删除管理的对象,但是,使用new[]进行分配内存时,需要用delete [] 而不是delete。
- unique_ptr可以直接使用下标访问
1 | //share_ptr |
智能指针多线程安全
(40条消息) C++ 智能指针线程安全的问题_年年年年年的博客-CSDN博客_智能指针线程安全
多态
- 运行期多态通过虚函数
- 编译期多态通过函数重载和模板具现化
虚函数
虚函数表位于只读数据段(.rodata),也就是C++内存模型中的常量区;而虚函数则位于代码段(.text),也就是C++内存模型中的代码区。
类的虚表会被这个类的所有对象所共享。类的对象可以有很多,但是他们的虚表指针都指向同一个虚表(虚表里没有普通函数指针)
如果是多重继承(一次继承多个基类),则子类有多个虚表指针,指向多个虚表,每个虚表都对应一个基类。
如果父类不是虚函数而子类是虚函数(父实子虚),那么依然不体现出多态,子类的虚函数隐藏了父类实函数。
模板函数不能是虚函数;因为每个包含虚函数的类具有一个virtual table,包含该类的所有虚函数的地址,因此vtable的大小是确定的。模板只有被使用时才会被实例化,将其声明为虚函数会使vtable的大小不确定(函数模板可能用到,可能用不到)。所以,成员函数模板不能为虚函数。
- 编译器在编译一个类的时候,需要确定这个类的虚函数表的大小。一般来说,如果一个类有N个虚函数,它的虚函数表的大小就是N,如果按字节算的话那么就是4*N。 如果允许一个成员模板函数为虚函数的话,因为我们可以为该成员模板函数实例化出很多不同的版本,也就是可以实例化出很多不同版本的虚函数
- 那么编译器为了确定类的虚函数表的大小,就必须要知道我们一共为该成员模板函数实例化了多少个不同版本的虚函数。显然编译器需要查找所有的代码文件,才能够知道到底有几个虚函数,这对于多文件的项目来说,代价是非常高的,所以才规定成员模板函数不能够为虚函数。
静态成员函数不能是virtual的,因为静态成员函数属于类而非单个具体对象,所有的对象共享一份代码,没有实现多态的必要。编译会出错。
- 静态函数是没有this指针的!没有this指针就会影响到虚函数的VTABLE机制:vptr指针是在类的构造函数的创建中产生的,并且只能通过this指针来访问的!通过this指针vptr会指向保存虚函数地址的VTABLE。而static函数它没有this指针,所以virtual也无法工作
- 静态成员是编译期绑定的
inline成员函数可以声明为virtual,但是在编译时不会实际将代码直接在调用处展开。运行期绑定
友元函数也不能声明为virtual,因为友元关系是不能被继承的,编译会出错。
虚函数表剖析
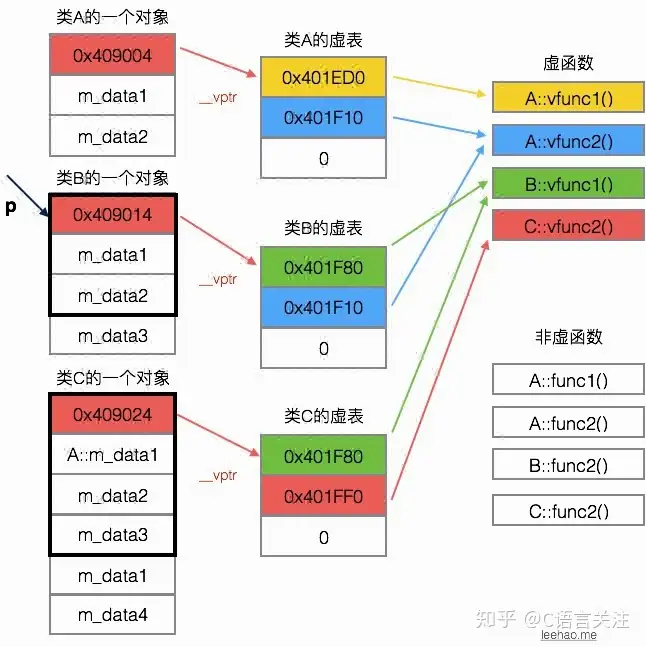
只要抓住“对象的虚表指针用来指向自己所属类的虚表,虚表中的指针会指向其继承的最近的一个类的虚函数”这个特点,便可以快速将这几个类的对象模型在自己的脑海中描绘出来。
重载、覆盖、隐藏(overload、override、overwrite)
重载很简单,就是同一个作用域下,对不同参数列表、同名函数的访问。覆盖和隐藏涉及到虚函数和继承。
覆盖通过虚函数表现出多态性质,要求函数签名一致,特征是:
- 函数名字与参数都相同
- 父类的函数是虚函数(virtual)
- 函数的const属性必须一致。
- 函数的返回类型必须相同或协变。
- 虚函数不能是模板函数。
- 协变(covariant),如果它保持了子类型序关系≦。该序关系是:子类型≦基类型。
- 比如基类:
virtual Base* op(),子类virtual Derive* op()。注意只能通过指针完成协变。 - 逆变就是相反,不变就是二者都不满足。
隐藏指的是子类隐藏了父类的函数的作用域(内层作用域的名称会遮掩外层),两种情况:
- 子类函数与父类函数的名称相同,是虚函数但参数不同、返回类型不同,父类函数被隐藏
- 子类函数与父类函数的名称相同,参数也相同,但是父类函数没有virtual,父类函数被隐藏
隐藏不表现出多态:
- 当没有virtual时,显然没有多态,这时以指针的类型静态绑定函数,子类指针只在子类里查找同名函数,找不到父类的;父类同理,指向子类的父类指针只能查找父类函数。
- 当有virtual时,因为参数不同,就和非虚的同名函数一样,仅仅是隐藏关系,没有虚特性,以指针的类型静态绑定函数。
要调用被隐藏的函数,必须显式给出父类名的作用域,比如using P::func()。子类覆盖了父类的一个函数,会把父类中重载的其他函数都隐藏。因为编译器找一个名称,会先从当前作用域(子类)找,找不到再找外层作用域(父类)。如果当前作用域能找到,就完全不看外层作用域了,因此外层重载的函数会被隐藏,编译器完全看不到只能报错。
static & const
不可以同时用const和static修饰成员函数
C++编译器在实现const的成员函数的时候为了确保该函数不能修改类的实例的状态,会在函数中添加一个隐式的参数const this*。但当一个成员为static的时候,该函数是没有this指针的。也就是说此时const的用法和static是冲突的。
#include<file.h> #include “file.h” 的区别
前者是从标准库路径寻找,后者是从当前工作路径
上行转换和下行转换
上行转换大致意思是把子类实例指针向上转换为父类型, 下行转换是把父类实例指针转换为子类实例
通常子类因为继承关系会包含父类的所有属性, 但是有些子类的属性父类没有,所以上行转换的时候,子类实例转换给父类是安全的, 转换后的指针或者对象可以放心使用父类的所有方法或者属性。但是下行转换的时候可能是不安全的, 因为假如子类有父类没有的属性或者方法的话, 父类指针或者实例转换为子类型后,转换后的实例中并没有子类多出来的方法或属性, 当调用到这些方法或属性时程序就会崩溃了
- static_cast :编译时期的静态类型检查static_cast静态转换相当于C语言中的强制转换,但不能实现普通指针数据(空指针除外)的强制转换,一般用于父类和子类指针、引用间的相互转换。没有运行时类型检查来保证转换的安全性。
- 将一个基类对象指针(或引用)cast到继承类指针,
dynamic_cast会根据基类指针是否真正指向继承类指针来做相应处理, 即会作出一定的判断。
比如一个父类指针指向子类实例对象,那么下行转换(把父类指针转换成子类指针)是安全的;但如果父类指针指向父类对象,那么下行转换就不安全了,因为子类指针调用的子类成员可能是父类对象没有的。
在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。
const 和 define 的区别
- const 生效于编译阶段,而 define 生效于预处理阶段;
- define只是简单的字符串替换,没有类型检查,而 const 有对应的数据类型,编译器要进行判断的,可以避免一些低级的错误;
- 用 define 定义的常量是不可以用指针变量去指向的,用 const 定义的常量是可以用指针去指向该常量的地址的;
- define 不分配内存,给出的是立即数,有多少次使用就进行多少次替换,在内存中会有多个拷贝,消耗内存大,const 在静态存储区中分配空间,在程序运行过程中内存中只有一个拷贝;
- 可以对 const 常量进行调试,但是不能对宏常量进行调试。
const和define的内存分配问题
const定义的只读变量在程序运行过程中只有一份拷贝(因为它是全局的只读变量,存放在静态区),而#define定义的宏常量在内存中有若干个拷贝。
const节省了空间,避免了不必要的内存分配,同时提高了效率。编译器通常不为普通的const只读变量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的值,没有了存储与读内存的操作,使得它的效率也很高。C++中是不太推荐用宏的,尽量少用。因为C++是强类型的语言,希望通过类型检查来降低程序中的很多错误,而宏只是在编译期前做简单替换,绕过了类型检查,失去了强类型系统的优势支撑。
1 |
|
原因:const定义的只读变量从汇编的角度来看,只是给出了对应的内存地址,而不是像#define一样给出的是立即数(占用代码段的内存),所以const定义的只读变量在程序运行过程中只有一份拷贝。
extern 的作用,extern变量在哪个数据段
extern 变量表示声明一个变量,表示该变量是一个外部变量,也就是全局变量,所以 extern 修饰的变量保存在静态存储区(全局区),全局变量如果没有显式初始化,会默认初始化为 0,或者显式初始化为 0 ,则保存在程序的 BSS 段,如果初始化不为 0 则保存在程序的 DATA 段。
share_ptr循环引用(内存泄漏)
share_ptr循环引用产生原因及其解决方案_路人甲同学的博客-CSDN博客_shared_ptr循环引用
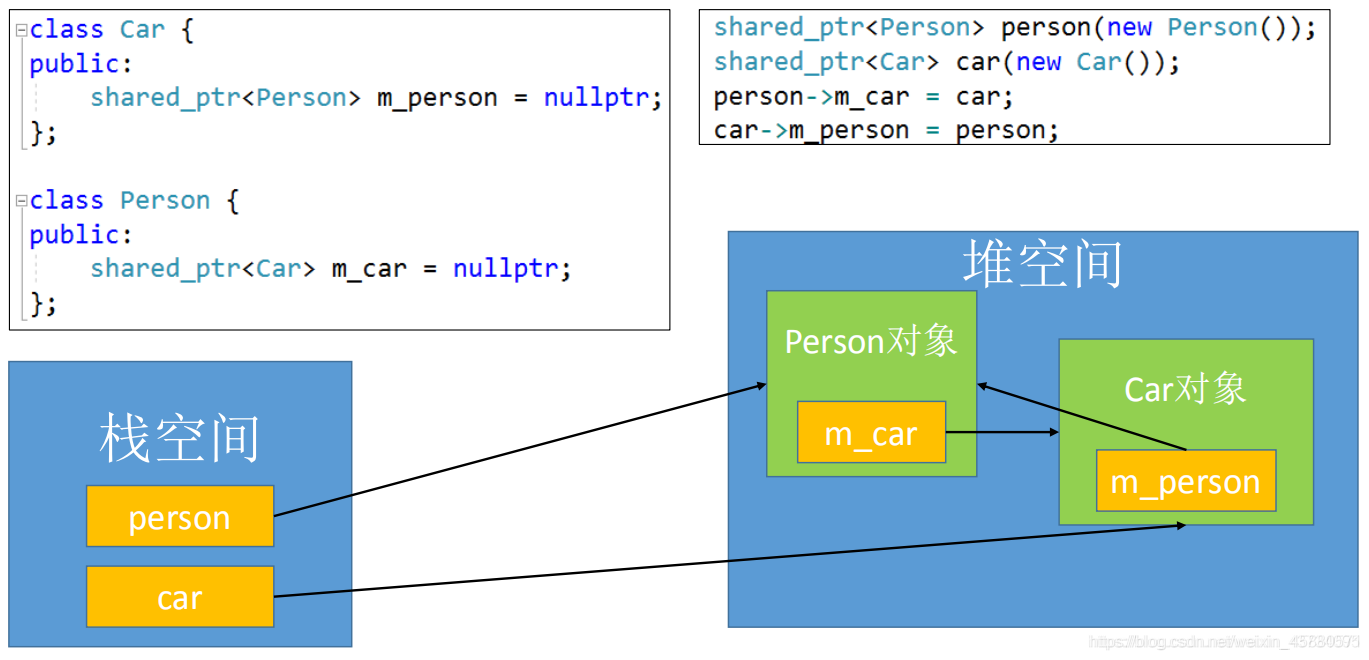
根据代码执行顺序,share_ptr指针指向new创建的一个Person对象,也就是图中栈空间的person指针指向了堆空间的Person对象,引用计数为1,同理,car指针也指向了堆空间的Car对象,引用计数亦为1。
接下来,Person对象里的成员m_car指向Car对象,Car对象的引用计数加1后为2,Car对象的m_person也指向Person对象,Person对象引用计数也加1为2。
若此时代码执行结束,栈空间上的car指针先进行释放,Car对象的引用计数减1后为1,后释放person指针,Person对象的引用计数也减为1。由于Person对象和Car对象都是建立再堆空间上,两者相互依赖,都在等待对方释放。
可以看到,这个例子中,堆空间里的 Person对象 与 Car对象互相使用着,导致双方的 shared_ptr 强引用数量不会为0,所以不会自动释放内存,产生了内存泄漏。
循环引用的解决方案是使用 weak_ptr。
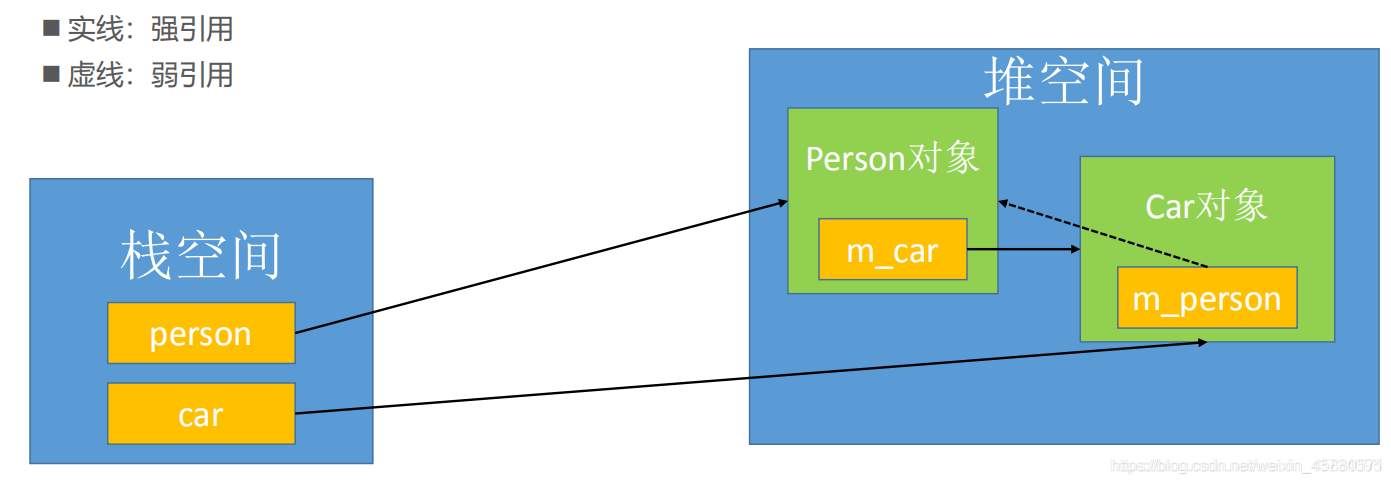
根据之前的分析可知,前三句代码执行完后,Person对象的引用计数为1,Car对象的引用计数为2。而第四条语句car->m_person = person执行的便是途中虚线弱引用的语句,不增加Person对象的引用计数。因此,Person对象的引用计数为1,Car对象的引用计数为2。
若此时代码执行结束,栈空间上的car指针先进行释放,Car对象的引用计数减1为1,后释放person指针,Person对象的引用计数减1后为0,Person对象释放内存空间,因此m_car成员函数也得到释放,Car对象引用计数减1后为0,Car对象也得到释放。因此不会产生内存泄漏。
库文件(静态库与动态库)
什么是库?库文件是一种目标文件,静态库是可重定位目标文件,动态库是共享目标文件。
- 头文件是在预处理时使用;库文件是链接时使用。
- 头文件内容还是高级语言内容;库文件是二进制文件。
库文件和二进制文件的区别:库文件也是二进制文件,二进制文件包括可执行文件和目标文件。可执行文件是可以直接运行的程序,目标文件是编译器生成的中间代码,需要链接器将它们合并成可执行文件,这里的目标文件也就是库文件。
静态库与动态库的区别
- 1、静态库的扩展名一般为“.a”或“.lib”;动态库的扩展名一般为“.so”或“.dll”。(前面是linux,后面是windows)
- 2、静态库在编译时会直接整合到目标程序中,编译成功的可执行文件可独立运行;动态库在编译时不会放到连接的目标程序中,即可执行文件无法单独运行。
- 静态库和动态库最本质的区别就是:该库是否被编译进目标(程序)内部。
静态库
- 优点:
- ①静态库被打包到应用程序中加载速度快
- ②发布程序无需提供静态库,移植方便(因为编译成可运行程序了)
- 缺点:
- ①相同的库文件数据可能在内存中被加载多份,消耗系统资源,浪费内存
- ②库文件更新需要重新编译项目文件,生成新的可执行程序,浪费时间。
- 优点:
动态库
- 优点:
- ①可实现不同进程间的资源共享
- ②动态库升级简单,只需要替换库文件,无需重新编译应用程序
- ③可以控制何时加载动态库,不调用库函数动态库不会被加载
- 缺点:
- ①加载速度比静态库慢
- ②发布程序需要提供依赖的动态库
- 优点:
可变参数模板
C++ 泛型编程(一) —— 可变参数模板 - 简书 (jianshu.com)
指针和引用的区别
- 定义和性质不同。指针是一种数据类型,用于保存地址类型的数据,而引用可以看成是变量的别名。指针定义格式为:数据类型 *;而引用的定义格式为:数据类型 &;
- 引用不可以为空,当被创建的时候必须初始化,而指针变量可以是空值,在任何时候初始化;
- 指针可以有多级,但引用只能是一级;
- 引用使用时无需解引用(*),指针需要解引用;
- 指针变量的值可以是 NULL,而引用的值不可以为 NULL;
- 指针的值在初始化后可以改变,即指向其它的存储单元,而引用在进行初始化后就不会再改变了;
- sizeof 引用得到的是所指向的变量(对象)的大小,而 sizeof 指针得到的是指针变量本身的大小;
- 指针作为函数参数传递时传递的是指针变量的值,而引用作为函数参数传递时传递的是实参本身,而不是拷贝副本;
- 指针和引用进行++运算意义不一样。
C++ 和 C 中 struct 的区别
- C 的结构体不允许有函数存在,C++ 的结构体允许有内部成员函数,并且允许该函数是虚函数
- C 的结构体内部成员不能加权限,默认是 public,而 C++ 的结构体内部成员权限可以是 public、protected、private,默认 public
- C 的结构体是不可以继承,C++ 的结构体可以从其它的结构体或者类继承
- C 中的结构体不能直接初始化数据成员(因为不能有函数所以也没有构造函数),C++ 中可以
- C 中使用结构体需要加上 struct 关键字,或者对结构体使用 typedef 取别名后直接使用,而 C++ 中使用结构体可以省略 struct 关键字直接使用 struct
struct和class 的区别
- struct 一般用于描述一个数据结构集合,而 class 是对一个对象数据的封装
- struct 中默认访问控制权限是 public,而 class 中默认的访问控制权限是 private struct A { int iNum; // 默认访问控制权限是 public } class B { int iNum; // 默认访问控制权限是 private }
- 在继承关系中,struct 默认是公有继承,而 class 是私有继承
sizeof 原理
sizeof 是在编译的时候,查找符号表,判断类型,然后根据基础类型来取值。如果 sizeof 运算符的参数是一个不定长数组,则该需要在运行时计算数组长度。
对指针变量进行 sizeof 运算,获得的是指针变量的大小,而无论是什么类型的指针,在同一平台下结果都是一样的。在 32 位平台下是 4 个字节,在 64 位平台下是 8 个字节。
volatile可以和 const 同时使用吗
volatile 限定符是用来告诉计算机,所修饰的变量的值随时都会进行修改的。用于防止编译器对该代码进行优化。通俗的讲就是编译器在用到这个变量时必须每次都小心地从内存中重新读取这个变量的值,而不是使用保存在寄存器里的备份。 const 和 volatile 可以一起使用,volatile 的含义是防止编译器对该代码进行优化,这个值可能变掉的。而 const 的含义是在代码中不能对该变量进行修改。因此,它们本来就不是矛盾的。
const只在编译期间保证常量被使用时的不变性,无法保证运行期间的行为。程序员直接修改常量会得到一个编译错误,但是使用间接指针修改内存,只要符合语法则不会得到任何错误和警告。因为编译器无法得知你是有意还是无意的修改,但是既然定义成const,那么程序员就不应当修改它,不然直接使用变量定义好了。
- const全局变量:此时该常量是存放在.rodata段的—Read Only Data也就是常量区,是无法通过取地址方式去修改的,修改内容会报段错误
- const局部变量:
- c++中 对于基础类型(整数,浮点数,字符) 系统不会给const变量开辟空间 ,会将其放到符号表中;
- c++中当 对const变量取地址的时候 系统就会给它开辟空间(栈);
- 当用变量给const变量赋值时,系统直接为其开辟空间 而不会把它放入符号表中,这里的赋值是通过指针取地址赋值
- const 自定义数据类型(结构体、对象) 和数组系统会分配空间;
typdef和define区别
#define是预处理命令,在预处理是执行简单的替换,不做正确性的检查
typedef是在编译时处理的,它是在自己的作用域内给已经存在的类型一个别名 typedef (int*) pINT; #define pINT2 int* 效果相同?实则不同!实践中见差别:pINT a,b;的效果同int *a; int *b;表示定义了两个整型指针变量。而pINT2 a,b;的效果同int *a, b;表示定义了一个整型指针变量a和整型变量b。
引用作为函数参数以及返回值
对比值传递,引用传参的好处:
- 在函数内部可以对此参数进行修改
- 提高函数调用和运行的效率(所以没有了传值和生成副本的时间和空间消耗)
- 用引用作为返回值最大的好处就是在内存中不产生被返回值的副本。
有以下的限制:
- 不能返回局部变量的引用。因为函数返回以后局部变量就会被销毁
- 不能返回函数内部new分配的内存的引用。虽然不存在局部变量的被动销毁问题,可对于这种情况(返回函数内部new分配内存的引用),又面临其它尴尬局面。例如,被函数返回的引用只是作为一 个临时变量出现,而没有被赋予一个实际的变量,那么这个引用所指向的空间(由new分配)就无法释放,造成memory leak
- 可以返回类成员的引用,但是最好是const。因为如果其他对象可以获得该属性的非常量的引用,那么对该属性的单纯赋值就会破坏业务规则的完整性。
栈溢出的原因以及解决方法
栈溢出是指函数中的局部变量造成的溢出(注:函数中形参和函数中的局部变量存放在栈上) 栈的大小通常是1M-2M,所以栈溢出包含两种情况,一是分配的的大小超过栈的最大值,二是分配的大小没有超过最大值,但是接收的buf比原buf小。
- 函数调用层次过深,每调用一次,函数的参数、局部变量等信息就压一次栈
- 局部变量体积太大。
解决办法大致说来也有两种:
- 增加栈内存的数目;如果是不超过栈大小但是分配值小的,就增大分配的大小
- 使用堆内存;具体实现由很多种方法可以直接把数组定义改成指针,然后动态申请内存;也可以把局部变量变成全局变量,一个偷懒的办法是直接在定义前边加个static,呵呵,直接变成静态变量(实质就是全局变量)
ifndef和program once
相同点: 它们的作用是防止头文件被重复包含。
不同点:
- ifndef 由语言本身提供支持,但是 program once 一般由编译器提供支持,也就是说,有可能出现编译器不支持的情况(主要是比较老的编译器)。
- 通常运行速度上 ifndef 一般慢于 program once,特别是在大型项目上, 区别会比较明显,所以越来越多的编译器开始支持 program once。
- ifndef 作用于某一段被包含(define 和 endif 之间)的代码, 而 program once 则是针对包含该语句的文件, 这也是为什么 program once 速度更快的原因。
指针数组和数组指针
数组指针,是指向数组的指针,而指针数组则是指该数组的元素均为指针。
数组指针,是指向数组的指针,其本质为指针,形式如下。如 int (*p)[n],p即为指向数组的指针,()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。数组指针是指向数组首元素的地址的指针,其本质为指针,可以看成是二级指针,一般用作二维数组。
1 | 类型名 (*数组标识符)[数组长度] |
指针数组,在C语言和C++中,数组元素全为指针的数组称为指针数组,其中一维指针数组的定义形式如下。指针数组中每一个元素均为指针,其本质为数组。如 int *p[n], []优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1时,则p指向下一个数组元素,这样赋值是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]…p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
1 | 类型名 *数组标识符[数组长度] |
C++是不是类型安全
不是。两个不同类型的指针之间可以强制转换
全局变量和局部变量
生命周期不同: 全局变量随主程序创建和创建,随主程序销毁而销毁;局部变量在局部函数内部,甚至局部循环体等内部存在,退出就不存在;
使用方式不同: 通过声明后全局变量程序的各个部分都可以用到;局部变量只能在局部使用;分配在栈区。
内存分配位置不同: 全局变量分配在全局数据段并且在程序开始运行的时候被加载。局部变量则分配在堆栈里面 。
操作系统和编译器如何识别
操作系统和编译器通过内存分配的位置来知道的,全局变量分配在全局数据段并且在程序开始运行的时候被加载。局部变量则分配在堆栈里面 。
c++内存分配
内存区域:栈、堆、全局区、常量区、代码区
- 栈:系统自动分配的空间,只要不特殊声明,就定义在栈区,函数的区域也在栈上。栈是向下增长的。(const 局部变量在栈里)
- 文件映射区(mmap()系统调用,让内核创建一个新的虚拟存储区域【匿名文件】。另一个作用是把文件内容【普通文件】映射到进程的虚拟内存空间, 通过对这段内存的读取和修改,来实现对文件的读取和修改。这里面没有像read和write那样拷贝,虚拟内存空间映射了内核空间)
- 堆:使用动态内存分配的方式可以申请堆空间,用完要手动释放。
- 全局区:全局变量、静态变量(static)
- 常量区:代码中的数字,字符等常量,例如’a’,—1.2等
- 代码区:存放可执行代码,避免频繁的读硬盘。
其中全局区和常量区和代码区又分为
- Bss: 未初始化的全局变量,不占用可执行文件的大小。大多数操作系统,在加载程序时,会把所有的bss全局变量全部清零,无需要你手工去清零。
- Data:数据段,要放在可执行文件中的数据,包括堆、栈、以初始化的全局变量
- Rodata:只读数据段,存放常量,字符常量,const常量。常量不一定就放在rodata里,有的立即数直接编码在指令里,存放在代码段(.text)中。
- Text: 只读区域,包括常量区和代码区
new和malloc
malloc 底层是brk()和mmap(),当小于128k时用brk(),会维护一个内存池,复用小块内存。大于128k用mmap(),在文件映射区开辟空间。
new操作针对数据类型的处理,分为两种情况:
- 简单数据类型(包括基本数据类型和不需要构造函数的类型) 简单类型直接调用 operator new 分配内存; 可以通过new_handler 来处理 new 失败的情况; new 分配失败的时候不像 malloc 那样返回 NULL,它直接抛出异常(bad_alloc)。要判断是否分配成功应该用异常捕获的机制;
- 复杂数据类型(需要由构造函数初始化对象) new 复杂数据类型的时候先调用operator new,然后在分配的内存上调用构造函数。
delete也分为两种情况:
- 简单数据类型(包括基本数据类型和不需要析构函数的类型) delete简单数据类型默认只是调用free函数。
- 复杂数据类型(需要由析构函数销毁对象) delete复杂数据类型先调用析构函数再调用operator delete。
与 malloc 和 free 的区别:
- 属性上:new / delete 是c++关键字,需要编译器支持。 malloc/free是库函数,需要c的头文件支持。
- 参数:使用new操作符申请内存分配时无须制定内存块的大小,编译器会根据类型信息自行计算。而mallco则需要显式地指出所需内存的尺寸。
- 返回类型:new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,故new是符合类型安全性的操作符。而malloc内存成功分配返回的是void *,需要通过类型转换将其转换为我们需要的类型。
- 分配失败时:new内存分配失败时抛出bad_alloc异常;malloc分配内存失败时返回 NULL。
- 自定义类型:new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。 malloc/free是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
- 重载:C++允许重载 new/delete 操作符。而malloc为库函数不允许重载。
- 内存区域:new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。其中自由存储区为:C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。
既然有了malloc/free,C++中为什么还需要new/delete呢? 运算符是语言自身的特性,有固定的语义,编译器知道意味着什么,由编译器解释语义,生成相应的代码。库函数是依赖于库的,一定程度上独立于语言的。编译器不关心库函数的作用,只保证编译,调用函数参数和返回值符合语法,生成call函数的代码。 对于非内部数据类型而言,光用malloc/free无法满足动态对象都要求。new/delete是运算符,编译器保证调用构造和析构函数对对象进行初始化/析构。但是库函数malloc/free是库函数,不会执行构造/析构。
构造函数和析构函数的执行顺序
构造函数:
- 首先调用父类的构造函数;
- 调用成员变量的构造函数;
- 调用类自身的构造函数。
析构函数 对于栈对象或者全局对象,调用顺序与构造函数的调用顺序刚好相反,也即后构造的先析构。对于堆对象,析构顺序与delete的顺序相关。
static关键字的作用
修饰局部变量:static修饰局部变量时,使得被修饰的变量成为静态变量,存储在静态区。存储在静态区的数据生命周期与程序相同,在main函数之前初始化,在程序退出时销毁。(无论是局部静态还是全局静态)
修饰全局变量:全局变量本来就存储在静态区,因此static并不能改变其存储位置。但是,static限制了其链接属性。被static修饰的全局变量只能被该包含该定义的文件访问(即改变了作用域)。
修饰函数:static修饰函数使得函数只能在包含该函数定义的文件中被调用。对于静态函数,声明和定义需要放在同一个文件中,因为编译器看到声明就会强制在该文件中找定义。
修饰成员变量:用static修饰类的数据成员使其成为类的全局变量,会被类的所有对象共享,包括派生类的对象,所有的对象都只维持同一个实例。 因此,static成员必须在类外进行初始化(初始化格式:int base::var=10;),而不能在构造函数内进行初始化,不过也可以用const修饰static数据成员在类内初始化。
修饰成员函数:用static修饰成员函数,使这个类只存在这一份函数,所有对象共享该函数,不含this指针,因而只能访问类的static成员变量。静态成员是可以独立访问的,也就是说,无须创建任何对象实例就可以访问。例如可以封装某些算法,比如数学函数,如ln,sin,tan等等,这些函数本就没必要属于任何一个对象,所以从类上调用感觉更好,比如定义一个数学函数类Math,调用Math::sin(3.14);还可以实现某些特殊的设计模式:如Singleton;
程序编译的过程
编译的全部过程可以分为四个阶段,分别是预处理、编译、汇编和链接。
- 预处理阶段会处理源代码中的宏定义、文件包含、条件编译等指令,并删除注释和空白字符,生成.i文件。
- 编译阶段会对.i文件进行语法分析和优化,生成汇编代码,即.s文件。
- 汇编阶段会将.s文件转换为机器语言或指令,生成.o文件。
- 链接阶段会将.o文件与库文件等链接起来,生成可执行文件。
new/delete线程安全吗
C++语义中的new/delete两个关键字封装了malloc/free的。这些函数都是经过编译器向操作系统进行申请内存的,除非是编译器的设计问题,否则应该是安全的。
new/delete、malloc/free都是线程安全的
访问private变量
类只有int值,为private,无public方法,给一个实例化的对象,有没有什么办法访问or修改
- 如果不能用公有方法,那么可以尝试使用友元函数或友元类,它们可以访问类的所有成员,包括私有的。
- 友元函数不是类的成员函数,它只是被类声明为可以访问其私有成员的函数。
- 友元函数可以放在类中的任何位置,包括public、private或protected区域,但这并不影响它们的访问权限。
- 友元函数可以被任何其他函数调用,而不需要通过类的对象或指针。
- 友元函数不算作public方法,它是一种特殊的非成员函数。
- 如果只给了一个实例化对象:可以使用指针或引用强制转换类型,绕过编译器的检查。但这种方法很危险,可能会破坏类的数据结构和逻辑。
使用友元函数的示例:
1 |
|
使用指针的示例:
1 |
|
C++11里面的list的size获取时间复杂度
C++11里面的list的size获取时间复杂度是常数。这是因为C++11规定了所有标准容器的size成员函数都必须是常数时间复杂度。
只有std::forward_list,也就是单向链表,没有提供size成员函数。它的size只能用线性时间来计算
- std::forward_list没有size成员函数的原因是为了效率。std::forward_list是一种单向链表,它的设计目标是尽可能地节省时间和空间。
- 为了保持单向链表的效率和简洁性,设计者没有给它提供size变量。
C++11之前的版本,list的size获取时间复杂度是线性。这是因为C++11之前的版本没有规定size成员函数的时间复杂度,所以不同的编译器可能有不同的实现。
- GCC 4.x系列的编译器就是一个例子,它使用了一个计数器来记录list的大小,但这样会影响splice操作的常数时间复杂度。
- list::splice实现list拼接的功能。将源list的内容部分或全部元素删除,拼插入到目的list。
- splice操作是一种在list容器中转移元素的操作。它不会复制或移动元素,只会改变内部指针的指向。如果list容器使用了一个计数器来记录大小,那么在执行splice操作时,就需要更新两个容器的计数器值。这样就会增加splice操作的时间复杂度,从原来的常数时间变成线性时间。
- 这是一个权衡的问题,在C++11之前没有统一的标准,在C++11之后才规定了size和splice都必须是常数时间复杂度。
- GCC 5.0系列才开始支持C++11规定的常数时间复杂度。
RTTI
【C++】RTTI有什么用?怎么用? - 知乎 (zhihu.com)
RTTI是运行阶段类型识别(Runtime Type Identification)的简称。
这是新添加到C++中的特性之一,很多老式实现不支持。另一些实现可能包含开关RTTI的编译器设置。
假设有一个类层次结构,其中的类都是从一个基类派生而来的,则可以让基类指针指向其中任何一个类的对象。
有时候我们会想要知道指针具体指向的是哪个类的对象。因为:
- 可能希望调用类方法的正确版本,而有时候派生对象可能包含不是继承而来的方法,此时,只有某些类的对象可以使用这种方法。
- 也可能是出于调试目的,想跟踪生成的对象的类型。
在C++ 环境中﹐头文件(header file) 含有类之定义(class definition)亦即包含有关类的结构资料(representational information)。但是,这些资料只供编译器(compiler)使用,编译完毕后并未留下来,所以在执行时期(at run-time),无法得知对象的类资料。包括类名称、数据成员名称与类型、函数名称与类型等等。
例如,两个类Figure和Circle,其之间为继承关系。 若有如下指令﹕
1 | Figure *p; |
在执行时﹐p指向一个对象﹐但欲得知此对象之类资料﹐就有困难了。同样欲得知q 所参考(reference) 对象的类资料﹐也无法得到。
RTTI(Run-Time Type Identification)就是要解决这困难﹐也就是在执行时﹐您想知道指针所指到或参考到的对象类型时﹐该对象有能力来告诉您。随着应用场合之不同﹐所需支持的RTTI范围也不同。最单纯的RTTI包括﹕
- 类识别(class identification)──包括类名称或ID。
- 继承关系(inheritance relationship)──支持执行时期的「往下变换类型」(downward casting)﹐亦即动态变换类型(dynamic casting) 。
在对象数据库存取上﹐还需要下述RTTI﹕
- 对象结构(object layout) ──包括属性的类型、名称及其位置(position或offset)。
- 成员函数表(table of functions)──包括函数的类型、名称、及其参数类型等。
其目的是协助对象的I/O 和持久化(persistence) ,也提供调试讯息等。 若依照Bjarne Stroustrup 之建议,C++ 还应包括更完整的RTTI﹕
- 能得知类所实例化的各对象 。
- 能参考到函数的源代码。
- 能取得类的有关在线说明(on-line documentation) 。
其实这些都是C++ 编译完成时所丢弃的资料﹐如今只是希望寻找个途径来将之保留到执行期间。然而﹐要提供完整的RTTI﹐将会大幅提高C++ 的复杂度
dynamic_cast运算符
这是最常用的RTTI组件,它不能回答“指针指向的是哪类对象”这样的问题,但能够回答“是否可以安全地将对象的地址赋给特定类型的指针”这样的问题。
说白了,就是看看这个对象指针能不能转换为目标指针。
通常,如果指向的对象(*pt)的类型为Type或者是从Type直接或简介派生而来的类型,则下面的表达式将指针pt转换为Type类型的指针:
1 | dynamic_cast<Type *>(pt) |
否则,结果为0,即空指针。
typeid运算符和type_info类
typeid运算符能够用于确定两个对象是否为同种类型。它与sizeof有些相像,可以接受两种参数:
- 类名;
- 结果为对象的表达式。
返回一个对type_info对象的引用,其中,type_info是在头文件typeinfo中定义的一个类,这个类重载了==和!=运算符,以便可以用于对类型进行比较。
1 | // 判断pg指向的是否是ClassName类的对象 |
如果pg是一个空指针,程序将引发bad_typeid异常,该异常是从exception类派生而来的,它是在头文件typeinfo中声明的。
type_info类的实现随厂商而异,但包含一个name()成员,该函数返回一个随实现而异的字符串,通常(但并非一定)是类的名称。可以这样显示:
1 | std::cout << "Now processing type is " << typeid(*pg).name() << ".\\n"; |
其实,typeid运算符就是指出或判断具体的类型,而dynamic_cast运算符主要用于判断是否能够转换,并进行类型转换(指针或引用)。
误用RTTI的例子
有些人对RTTI口诛笔伐,认为它是多余的,会导致程序效率低下和糟糕的编程方式。这里有一个需要尽量避免的例子。
在判断是否能调用某个方法时,尽量不要使用if-else和typeid的形式,因为这会使得代码冗长。
如果在扩展的if else语句系列中使用了typeid,则应该考虑是否应该使用虚函数和dynamic_cast。
reinterpret_cast
reinterpret(重新诠释)
允许将任何指针转换为任何其他指针类型。 也允许将任何整数类型转换为任何指针类型以及反向转换。
C++类型转换之reinterpret_cast - 知乎 (zhihu.com)
变量在内存中是以“…0101…”二进制格式存储的,一个int型变量一般占用32个位(bit),参考下面的代码
1 |
|
在Ubuntu 14.04 LTS系统下,采用g++ 4.8.4版本编译器编译该源文件并执行,得到的输出结果如下:
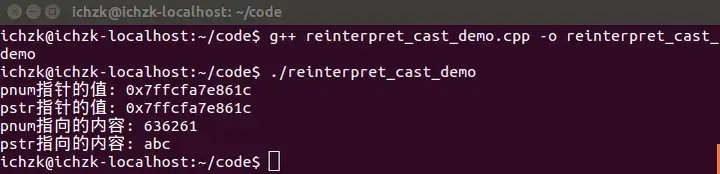
第6行定义了一个整型变量num,并初始化为0x00636261(十六进制表示),然后取num的地址用来初始化整型指针变量pnum。接着到了关键的地方,使用reinterpret_cast运算符把pnum从int*转变成char*类型并用于初始化pstr。
将pnum和pstr两个指针的值输出,对比发现,两个指针的值是完全相同的,这是因为“reinterpret_cast 运算符并不会改变括号中运算对象的值,而是对该对象从位模式上进行重新解释”。如何理解位模式上的重新解释呢?通过推敲代码11行和12行的输出内容,就可见一斑。
很显然,按照十六进制输出pnum指向的内容,得到636261;但是输出pstr指向的内容,为什么会得到”abc”呢?
在回答这个问题之前,先套用《深度探索C++对象模型》中的一段话,“一个指向字符串的指针是如何地与一个指向整数的指针或一个指向其他自定义类型对象的指针有所不同呢?从内存需求的观点来说,没有什么不同!它们三个都需要足够的内存(并且是相同大小的内存)来放置一个机器地址。指向不同类型之各指针间的差异,既不在其指针表示法不同,也不在其内容(代表一个地址)不同,而是在其所寻址出来的对象类型不同。也就是说,指针类型会教导编译器如何解释某个特定地址中的内存内容及其大小。”参考这段话和下面的内存示意图,答案已经呼之欲出了。
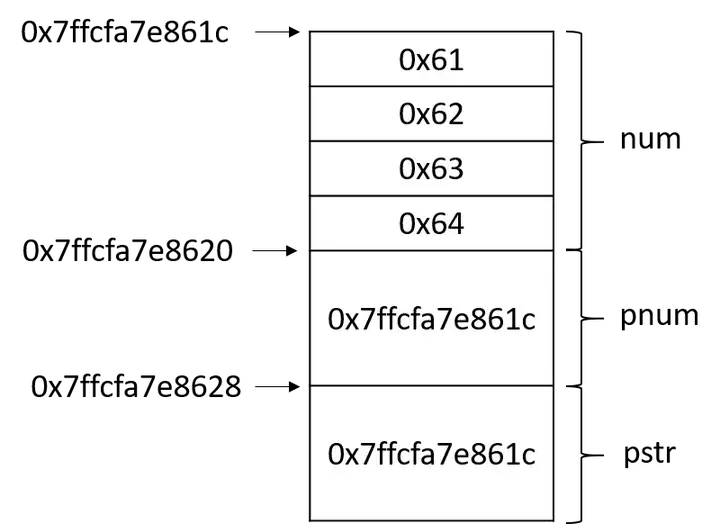
使用reinterpret_cast运算符把pnum从int*转变成char*类型并用于初始化pstr后,pstr也指向num的内存区域,但是由于pstr是char*类型的,通过pstr读写num内存区域将不再按照整型变量的规则,而是按照char型变量规则。一个char型变量占用一个Byte,对pstr解引用得到的将是一个字符,也就是’a’。而在使用输出流输出pstr时,将输出pstr指向的内存区域的字符,那pstr指向的是一个的字符,那为什么输出三个字符呢?这是由于在输出char*指针时,输出流会把它当做输出一个字符串来处理,直至遇到’\0’才表示字符串结束。对代码稍做改动,就会得到不一样的输出结果,例如将num的值改为0x63006261,输出的字符串就变为”ab”。
上面的例子融合了一些巧妙的设计,我们在pstr指向的内存区域中故意地设置了结束符’\0’。假如将num的值改为0x64636261,运行结果会是怎样的呢?
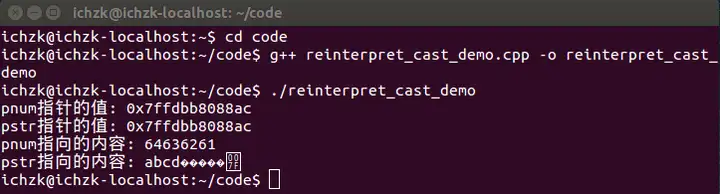
上面是我测试的截图,大家可以思考一下为什么在输出”abcd”之后又输出了6个字符才结束呢(提示:参考上面的内存示意图)。
有些情况下,就不会这么幸运了,迎接我们的很可能是运行崩溃。例如我们直接将num(而不是pnum)转型为char*,再运行程序的截图如下

可以分析出,程序在输出pstr时崩溃了,这是为什么呢?pstr指向的内存区域的地址是0x64636261,而这片内存区域很有可能并不在操作系统为当前进程分配的虚拟内存空间中,从而导致段错误。
shared_ptr和weak_ptr互相转换
当一个shared_ptr指针被转换为weak_ptr指针时,可以使用以下代码:
1 | std::shared_ptr<int> sp(new int(10)); |
当一个weak_ptr指针被转换为shared_ptr指针时,可以使用以下代码:
1 | std::weak_ptr<int> wp; |
C++11新特性说一下
新特性:智能指针、右值引用、强制转型、std::thread、lambda
操作系统
线程的上下文切换
线程所使用的资源来自其所属进程的资源
只切换线程的私有数据:栈、寄存器、程序计数器;线程没有独立的地址空间,虚拟内存和全局变量和堆是共享的,不需要切换,而进程需要切换。
如果是不同进程的线程,那么实际上就是进程上下文切换。
进程上下文切换
如果只是用户态和内核态的切换,只用换一下CPU寄存器和程序计数器。
如果是不同进程的切换就比较麻烦。
在Linux内核中,进程上下文切换的具体步骤如下:
- 保存当前进程的CPU寄存器状态:进程上下文切换需要保存当前进程的CPU寄存器状态,包括通用寄存器、特殊寄存器和程序计数器等。这些寄存器状态将被保存在当前进程的内核栈中。
- 保存当前进程的内核栈指针:当前进程的内核栈指针也需要被保存,以便在切换回该进程时能够正确地恢复内核栈中的寄存器状态。这个指针也将被保存在当前进程的内核栈中。
- 保存当前进程的虚拟内存状态:当前进程的页表(指针)、虚拟内存映射关系、虚拟内存使用情况(空间大小)等虚拟内存状态需要被保存到当前进程的进程控制块(PCB)中(PCB保存在内存)。
- 切换到新进程的虚拟内存状态:将新进程的虚拟内存状态从进程控制块中恢复到系统的内核数据结构中。
- 恢复新进程的CPU寄存器状态:将新进程的CPU寄存器状态从新进程的内核栈中恢复,包括通用寄存器、特殊寄存器和程序计数器等。
- 恢复新进程的内核栈指针:将新进程的内核栈指针从新进程的内核栈中恢复。
- 跳转到新进程的代码:将CPU的控制权转移到新进程的代码中,从新进程的上下文开始执行。
在进程上下文切换的过程中,通常情况下是不需要将进程的内存数据保存到磁盘的。因为这些数据已经保存在虚拟内存中,并且虚拟内存的页表信息也已经保存在进程控制块中。当进程恢复执行时,它的虚拟内存状态会被重新加载回内存中,从而使进程的内存数据得以恢复。
但是,如果系统遇到内存不足的情况,就需要通过将部分进程的内存数据写入磁盘中来腾出一些内存空间。这个过程称为”页面置换”(Page swapping)或者”页面换出”(Page out),可以使用类似于”页面置换算法”(Page replacement algorithm)的机制来选择需要置换的进程和页面。这个过程是由操作系统的”页调度器”(Page scheduler)来负责的,与进程上下文切换的过程有所不同。
线程和协程
线程是抢占式,而协程是非抢占式的,所以需要用户代码释放使用权来切换到其他协程,因此同一时间其实只有一个协程拥有运行权,相当于单线程的能力。
协程并不是取代线程,而且抽象于线程之上。线程是被分割的CPU资源, 协程是组织好的代码流程, 协程需要线程来承载运行。
线程切换:线程就是进程,就是构造函数(clone)的标志位不太一样而已,只是叫法不一样,用的数据结构都是进程描述符,其实就是一个东西。进程内线程切换,本质上还是进程切换。只要进程切换,就必然已经进入了内核态。道理很简单,只有内核才有权力进行进程调度,而且进程调度涉及到数据结构,例如可调度进程的红黑树、亦或是阻塞进程的队列集,也只有内核才有资格访问。
线程之间是如何进行协作的呢?
- 涉及到同步锁;
- 涉及到线程阻塞状态和可运行状态之间的切换;
- 涉及线程的上下文切换;
协程,又称微线程,是一种用户态的轻量级线程,协程的调度完全由用户控制(也就是在用户态执行)。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到进程的堆区,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁地访问全局变量,所以上下文的切换非常快。
协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和线程切换相比,线程数量越多,协程的性能优势就越明显。不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
一个线程内的多个协程是串行执行的,不能利用多核,所以,显然,协程不适合计算密集型的场景。协程适合I/O 阻塞型。
I/O本身就是阻塞型的(相较于CPU的时间世界而言)。就目前而言,无论I/O的速度多快,也比不上CPU的速度,所以一个I/O相关的程序,当其在进行I/O操作时候,CPU实际上是空闲的。
协程能比较好地处理这个问题,当一个协程(特殊子进程)阻塞时,它可以切换到其他没有阻塞的协程上去继续执行,这样就能得到比较高的效率
I/O阻塞时,利用协程来处理确实有优点(切换效率比较高),但是我们也需要看到其不能利用多核的这个缺点,必要的时候,还需要使用综合方案:多进程+协程。
什么是信号?原理是什么
信号(Signal)主要用来通知进程某个特定事件的发生,或者是让进程执行某个特定的处理函数,原理是软中断。
signal信号,又称为软中断信号,用来通知进程发生了异步事件,是在软件层次上是对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。
- 进程之间可以互相通过系统调用kill发送软中断信号。
- 内核也可以因为内部事件而给进程发送信号,通知进程发生了某个事件。
- 信号是进程间通信机制中唯一的异步通信机制,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。
- 如果该进程当前并未处于执行态,则该信号就由内核保存起来,直到该进程恢复执行再传递给它;
- 如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被 取消时才被传递给进程。
信号来源
- 硬件方式
- 当用户按某些终端键时,引发终端产生的信号,例如Ctrl +C 通常会产生终端信号SIGINT;
- 硬件异常产生信号。除数为0、无效的内存引用等等,这些通常由硬件检测到,并将通知内核。然后内核会为正在运行的进程产生适当的信号。例如对执行一个无效内存引用产生SIGSEGV信号;
- 软件方式
- kill 将信号sig 发送给pid 进程
- killpg 发送信号sig 到pgrp 的所有进程中
- raise 给当前进程发送信号sig
- abort 给自己发送异常终止信号
- alarm 定时将产生SIGALRM信号给调用进程
用户进程对信号的响应方式:
- 1,捕捉 (收到某个信号,做指定的动作,而不是做默认的)
- 2,忽略 (收到某个信号,不做什么动作)
- 3,阻塞 (收到某个信号,先做完当前事情,然后在响应信号)
- 4,按照默认动作,SIGKILL,SIGSTOP不能被捕捉
过程:
- 接收信号的任务是由
内核代理的,当内核接收到信号后,会将其放到对应进程的信号队列中(进程控制块PCB主要维护了一个进程描述符,里面有着pid,进程状态,所以信号也存在里面),同时向进程发送一个中断,使其陷入内核态。此时信号还只是在队列中,对进程来说暂时是不知道有信号到来的。 - 内核进行中断处理,在返回用户态前处理到达的信号
- 信号处理函数在用户空间,回到用户态执行处理函数
- 返回内核态,检查是否要处理下一个信号(如果有)
- 返回用户态继续执行程序

用户处理信号的时机为第一次内核态切换到用户态之时,为什么要选此时?
- 信号不一定会被立即处理,操作系统不会为了处理一个信号而挂起当前正在运行的进程,这样产生的消耗太大(紧急信号【实时信号】可能会被立即处理)。
操作系统选择在内核态切换到用户态的时候去处理信号,不要单独进行进程切换而浪费时间。 - 有时候一个正在睡眠的进程突然收到信号,操作系统肯定不愿意切换当前正在运行的进程,预示就将该信号存在此进程的PCB的信号字段中,在合适的时候处理信号。
信号与中断的相似点
1)采用了相同的异步通信方式;
2)当检测出有信号或中断请求时,都暂停正在执行的程序而转去执行相应的处理程序;
3)都在处理完毕后返回到原来的断点;
4)对信号或中断都可进行屏蔽。
信号与中断的区别
1)中断有优先级,而信号没有优先级,所有的信号都是平等的;
2)信号处理程序是在用户态下运行的,而中断处理程序是在核心态下运行;
3)中断响应是及时的,而信号响应通常都有较大的时间延迟。
大端、小端,如何判断大端和小端
大端和小端指的是字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序。字节序分为大端字节序(Big-Endian) 和小端字节序(Little-Endian)。
大端字节序:是指最高位字节存储在内存的低地址处,低位字节存储在内存的高地址处 。注意不是完全倒过来,字节内部是不倒序的
小端字节序:是指最高位字节存储在内存的高地址处,而低位字节则存储在内存的低地址处
如何判断大端还是小端:可以定义一个联合体
union,联合体中有一个 short 类型的数据,有一个 char 类型的数组,数组大小为 short 类型的大小。给 short 类型成员赋值一个十六进制数 0x0102,然后输出根据数组第一个元素和第二个元素的结果来判断是大端还是小端。
栈和堆的区别
- 管理方式 对于栈来讲,是由编译器自动管理,无需手动控制;对于堆来说,分配和释放都是由程序员控制的。
- 空间大小 总体来说,栈的空间是要小于堆的。堆内存几乎是没有什么限制的;但是对于栈来讲,一般是有一定的空间大小的。
- 碎片问题 对于堆来讲,由于分配和释放是由程序员控制的(利用new/delete 或 malloc/free),频繁的操作势必会造成内存空间的不连续,从而造成大量的内存碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的数据结构,在某一数据弹出之前,它之前的所有数据都已经弹出。
- 生长方向 对于堆来讲,生长方向是向上的,也就是沿着内存地址增加的方向,对于栈来讲,它的生长方式是向下的,也就是沿着内存地址减小的方向增长。
- 分配方式 堆都是动态分配的,没有静态分配的堆。栈有两种分配方式:静态分配和动态分配,静态分配是编译器完成的,比如局部变量的分配;动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器实现的,无需我们手工实现。
- 分配效率 栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率很高。堆则是 C/C++ 函数提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。
为什么栈快但是空间小呢?
栈只是的名词,我们的关注点是它的功能,栈的功能主要是函数调用、局部变量申请、函数参数传递所使用的空间,是为函数调用的实现提供一些保存、恢复操作。栈帧中主要存储的数据有局部变量、函数返回地址、函数参数。在一个程序中这些信息总共也没多少,所以一般情况下栈空间都特别小。
Stack 的最顶端一般会留存在 CPU registers 和 cache 中。遇到频繁但是层次不多的函数调用,可以利用高速 cache。大块的内存会破坏这种优化。
哈希冲突
哈希冲突产生原因:通过哈希函数产生的哈希值是有限的,当数据比较多时,经过哈希函数处理后仍然有不同的数据对应相同的哈希值,这就产生了哈希冲突。
衡量冲突概率的概念:装填因子(元素个数/可装填总数)。
解决办法:
- 线性探测:使用哈希函数计算出的哈希值如果已经有元素占用了,则往后一次寻找,直到找到一个未被占用的哈希值;
- 开链:每个表格维护一个list,如果哈希函数计算出的格子相同就按顺序存在这个list中;
- 再散列:发生冲突时使用另一种哈希函数再计算,直到不冲突;
- 公共溢出区:一旦哈希函数计算的结果相同就放入公共溢出区。
为什么哈希表扩容是两倍(容量是2的n次方)
比如table 是一个数组,那么如何最快的将元素 e 放入数组 ? 当然是找到元素 e 在 table 中对应的位置 index ,然后 table[index] = e; 就好了;如何找到 e 在 table 中的位置了 ? 我们知道只能通过数组下标(索引)操作数组,而数组的下标类型又是 int ,如果 e 是 int 类型,那好说,就直接用 e 来做数组下标(若 e > table.length,则可以 e % table.length 来获取下标),可 key - value 中的 key 类型不一定,所以我们需要一种统一的方式将 key 转换成 int ,最好是一个 key 对应一个唯一的 int (目前还不可能, int有范围限制,对转换方法要求也极高),所以引入了 hash 方法。拿到了 key 对应的 哈希值h 之后,我们最容易想到的对 value 的 put 操作如下:
1 | table[h % table.length] = value |
直接取模是我们最容易想到的获取下标的方法,但是最高效的方法吗 ?我们知道计算机中的四则运算最终都会转换成二进制的位与运算,如下,只有 & 数是1时,& 运算的结果与被 & 数一致:
1 | 1&1=1 |
对于多位也是一样:
1 | 1010&1111=1010; => 10&15=10; |
10 & 16 与 11 & 16 得到的结果一样,也就是冲突(碰撞)了,那么 10 和 11 对应的 value 会在同一个链表中,而 table 的有些位置则永远不会有元素,这就导致 table 的空间未得到充分利用。比如说前面的16,结果要么是16要么是0,会造成一个空洞。或者说101(5),11(3)这个位置永远不可能放,因为与的那一位是0。
对于一个容量为n的哈希表,位与运算n-1和模n做到的功能是一样的,而2^n-1的二进制都是连续的一,能充分利用空间,因此容量是2^n,即每次扩容两倍。
分段和分页
- 分段(外部碎片,因为一个段大小不等)
将用户程序地址空间分成若干个大小不等的段,每段可以定义一组相对完整的逻辑信息。存储分配时,以段为单位,段与段在内存中可以不相邻接,实现了离散分配。分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。 - 分页(内部碎片,内存利用率好)
用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配。分页主要用于实现虚拟内存,从而获得更大的地址空间。 - 段页式
- 页式存储管理能有效地提高内存利用率(解决内存碎片),而分段存储管理能反映程序的逻辑结构并有利于段的共享。将这两种存储管理方法结合起来,就形成了段页式存储管理方式。段页式存储管理方式即先将用户程序分成若干个段,再把每个段分成若干个页,并为每一个段赋予一个段名。在段页式系统中,为了实现从逻辑地址到物理地址的转换,系统中需要同时配置段表和页表,利用段表和页表进行从用户地址空间到物理内存空间的映射。
- 系统为每一个进程建立一张段表,每个分段有一张页表。段表表项中至少包括段号、页表长度和页表始址,页表表项中至少包括页号和块号。在进行地址转换时,首先通过段表查到页表始址,然后通过页表找到页帧号,最终形成物理地址。
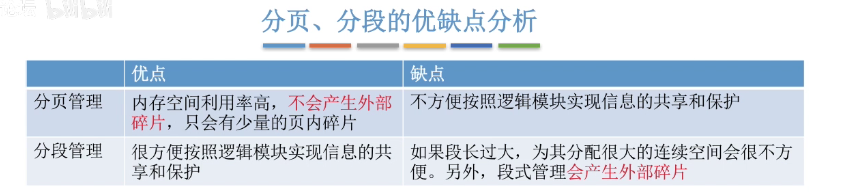
面试简答:分页是为了提高内存利用率,将内存分为一个个页框,将进程按照页框大小分为一个个页,分页对用户不可见。分段则是按照程序的自身逻辑分配到内存中,对用户可见,用户编程时需要显式给出段名。并且分段比分页更容易实现信息的共享,因为页的大小是由页框决定,一个页中可能包含多个逻辑模块,令多个逻辑模块共享同一块内存显然是不合理的(因为一共享就只能以页为单位来共享)
乐观锁和悲观锁
乐观锁:乐观锁总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。
悲观锁:悲观锁总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。适用于多写场景,或者冲突的代价很高的场景。
CAS(比较交换compare and swap)
加锁是一种悲观的策略,它总是认为每次访问共享资源的时候,总会发生冲突,所以宁愿牺牲性能(时间)来保证数据安全。
无锁是一种乐观的策略,它假设线程访问共享资源不会发生冲突,所以不需要加锁,因此线程将不断执行,不需要停止。一旦碰到冲突,就重试当前操作直到没有冲突为止。
无锁的策略使用一种叫做比较交换的技术(CAS Compare And Swap)来鉴别线程冲突,一旦检测到冲突产生,就重试当前操作直到没有冲突为止。
CAS核心算法:执行函数:CAS(V,E,N)
V表示准备要被更新的变量
E表示我们提供的 期望的值
N表示新值 ,准备更新V的值
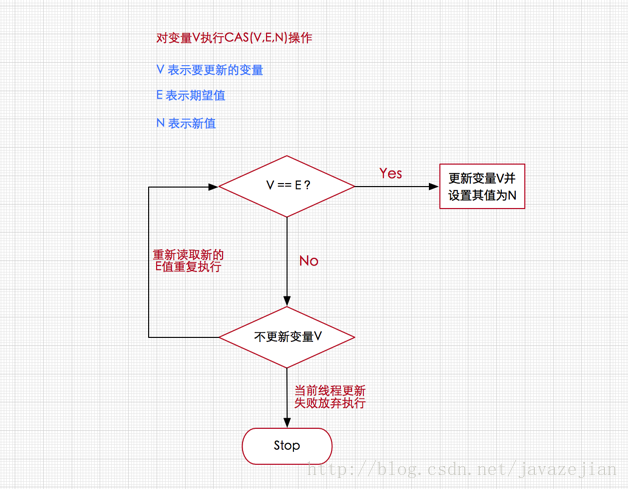
如果多个线程同时使用CAS操作一个变量的时候,只有一个线程能够修改成功。其余的线程提供的期望值已经与共享变量的值不一样了,所以均会失败。
由于CAS操作属于乐观派,它总是认为自己能够操作成功,所以操作失败的线程将会再次发起操作,自旋(循环)而不是被OS挂起。所以说,即使CAS操作没有使用同步锁,其它线程也能够知道对共享变量的影响。
因为其它线程没有被挂起,并且将会再次发起修改尝试(从主存中读取新值),所以无锁操作即CAS操作天生免疫死锁。
另外一点需要知道的是,CAS是系统原语,CAS操作是一条CPU的原子指令,所以不会有线程安全问题。
三大问题:
- ABA问题:
- 因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
- ABA问题的解决思路就是使用版本号(或者称为时间戳)。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A→B→A就会变成1A→2B→3A。
- 循环时间长开销大:自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
- 只能保证一个共享变量的原子操作:当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
孤儿进程和僵尸进程
- 孤儿进程是指一个父进程退出后,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为1)所收养,并且由 init 进程对它们完整状态收集工作,孤儿进程一般不会产生任何危害。
- 僵尸进程是指一个进程使用 fork() 函数创建子进程,如果子进程退出,而父进程并没有调用 wt() 或者wtpid() 系统调用取得子进程的终止状态,那么子进程的进程描述符仍然保存在系统中,占用系统资源(比如说pid号),这种进程称为僵尸进程。
- 为了防止产生僵尸进程,在 fork() 子进程之后我们都要及时在父进程中使用 wt() 或者 wtpid() 系统调用,等子进程结束后,父进程回收子进程 PCB 的资源。 同时,当子进程退出的时候,内核都会给父进程一个 SIGCHLD 信号,所以可以建立一个捕获 SIGCHLD 信号的信号处理函数,在函数体中调用 wt() 或 wtpid(),就可以清理退出的子进程以达到防止僵尸进程的目的。
- 如果父进程代码没有wait(),可以寻找僵尸进程把他kil掉,如果无效则可以手动kill掉父进程来结束僵尸进程,让init进程来收尸。因为每个进程结束的时候,系统都会扫描当前系统中所运行的所有进程,看看有没有哪个进程是刚刚结束的这个进程的子进程,如果是的话,就由init进程来接管他,成为他的父进程,从而保证每个进程都会有一个父进程。而init进程会自动wait其子进程,因此被Init接管的所有进程都不会变成僵尸进程。
共享内存
共享内存将相同的物理内存地址映射到用户空间,用户可以直接操作
- 什么是共享内存 共享内存是进程间通信的一种方式。不同进程之间共享的内存通常为同一段物理内存,进程可以将同一段物理内存连接到他们自己的地址空间中,所有的进程都可以访问共享内存中的地址。如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。
- 共享内存的优点:因为所有进程共享同一块内存,共享内存在各种进程间通信方式中具有最高的效率。访问共享内存区域和访问进程独有的内存区域一样快,并不需要通过系统调用或者其它需要切入内核的过程来完成。同时它也避免了对数据的各种不必要的复制。
- 共享内存的缺点:共享内存没有提供同步机制,这使得我们在使用共享内存进行进程之间的通信时,往往需要借助其他手段来保证进程之间的同步工作。
写时拷贝
传统的 fork() 系统调用直接把所有的资源复制给新创建的进程,这种实现过于简单并且效率低下,因为它拷贝的数据或许可以共享,或者有时候 fork() 创建新的子进程后,子进程往往要调用一种 exec 函数以执行另一个程序。
而 exec 函数会用磁盘上的一个新程序替换当前子进程的正文段、数据段、堆段和栈段,如果之前 fork() 时拷贝了内存,则这时被替换了,这是没有意义的。 Linux 的 fork() 使用写时拷贝(Copy-on-write)页实现。
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候,大大提高了效率。
互斥锁和自旋锁
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。 它俩是锁的最基本处理方式,更高级的锁都会选择其中一个来实现,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。
如果线程切换的消耗比锁被持有的时间还要长,就可以使用自旋锁。
内存对齐
什么是内存对齐 现代计算机中内存空间都是按照 字节(byte)划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但是实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数 k(通常它为4或8)的倍数,这就是所谓的内存对齐。
内存对齐的原因 - 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的。某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 - 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问,而对齐的内存访问仅需要一次访问。
如果一个变量的内存地址正好位于它长度的整数倍,它就被称做自然对齐。
1
2
3
4
5char 偏移量为sizeof(char) 即 1 的倍数
short 偏移量为sizeof(short) 即 2 的倍数
int 偏移量为sizeof(int) 即 4 的倍数
float 偏移量为sizeof(float) 即 4 的倍数
double 偏移量为sizeof(double) 即 8 的倍数
通过网络传输,内存对齐对传输有影响吗
内存对齐存在的意义之一是为了减少访问次数,通过以空间换效率的方式提高性能。其特性在相同平台的网络通讯中是没有影响的。 但在跨平台中传输结构体(或联合)时,则这个特性有可能会影响到数据的准确性。原因之一是自定义网络通讯协议包通常都是定义成struct的形式, 而struct会自动内存对齐,这会造成结构体成员间有”空洞“,传给其它平台后,其它平台弄不清楚原平台是按什么方式对齐的,只会按自己的方式解包。 解出来的结果有可能是错误的。
红黑树比AVL的优势,为何用红黑树
AVL树是严格的平衡二叉搜索树,平衡条件必须满足所有节点的左右子树高度差不超过1。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树合适用于插入与删除次数比较少,但搜索多的情况。AVL树在Windows NT内核中广泛被使用。
红黑树是一种弱平衡二叉搜索树(红黑树确保没有一条路径比其它路径长出两倍),由于是弱平衡,可以看出,在相同的节点情况下,AVL树的高度低于红黑树,相对于要求严格的AVL树来说它的旋转次数少,所以对于插入与删除较多的情况,我们就用红黑树。红黑树广泛用于C++的STL中,map和set都是用红黑树实现的。
红黑树高度
证明:红黑树高度上限(2lg(n+1)证明._luixiao1220的博客-CSDN博客_红黑树最大高度

零拷贝
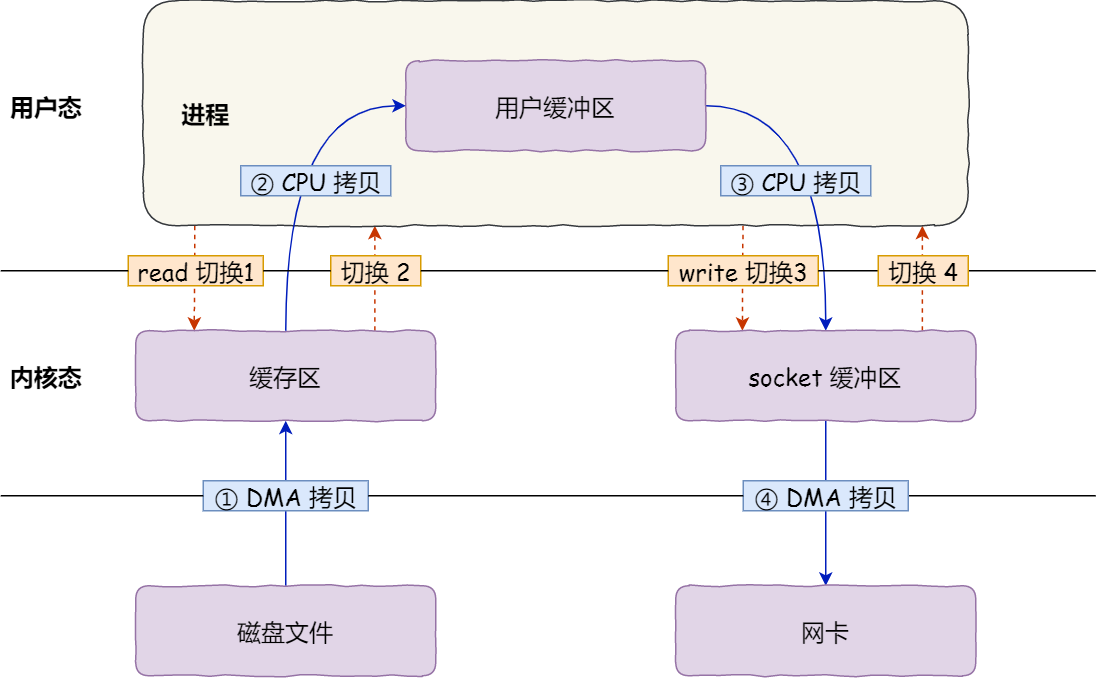
发生了 4 次用户态与内核态的上下文切换,发生了 4 次数据拷贝
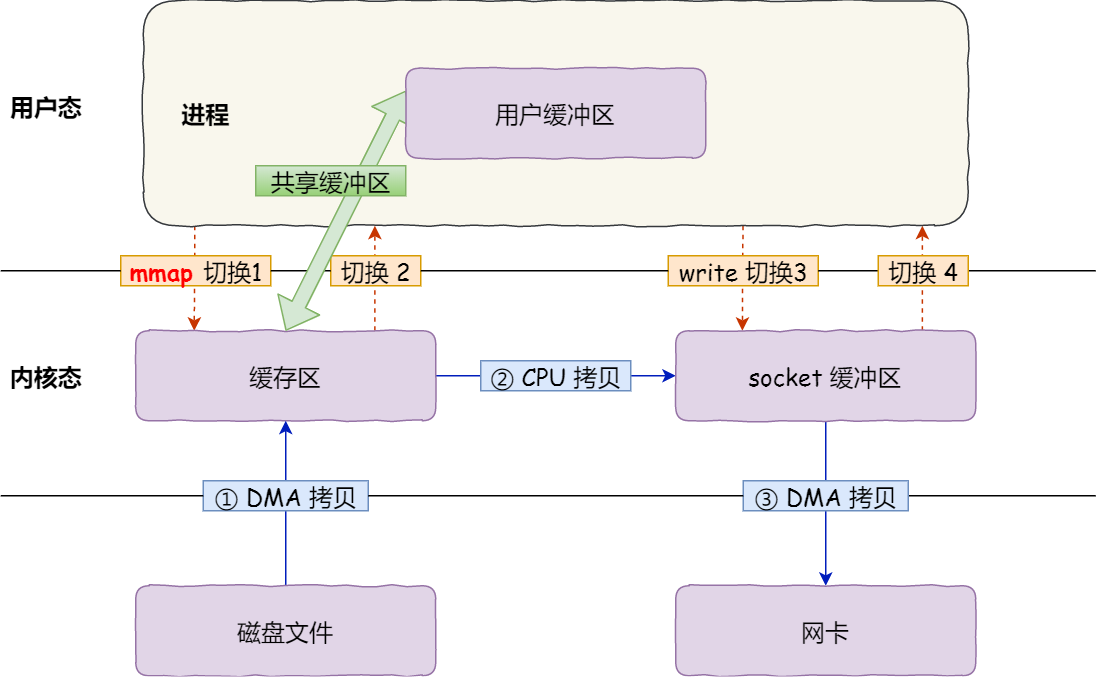
仍然需要 4 次上下文切换
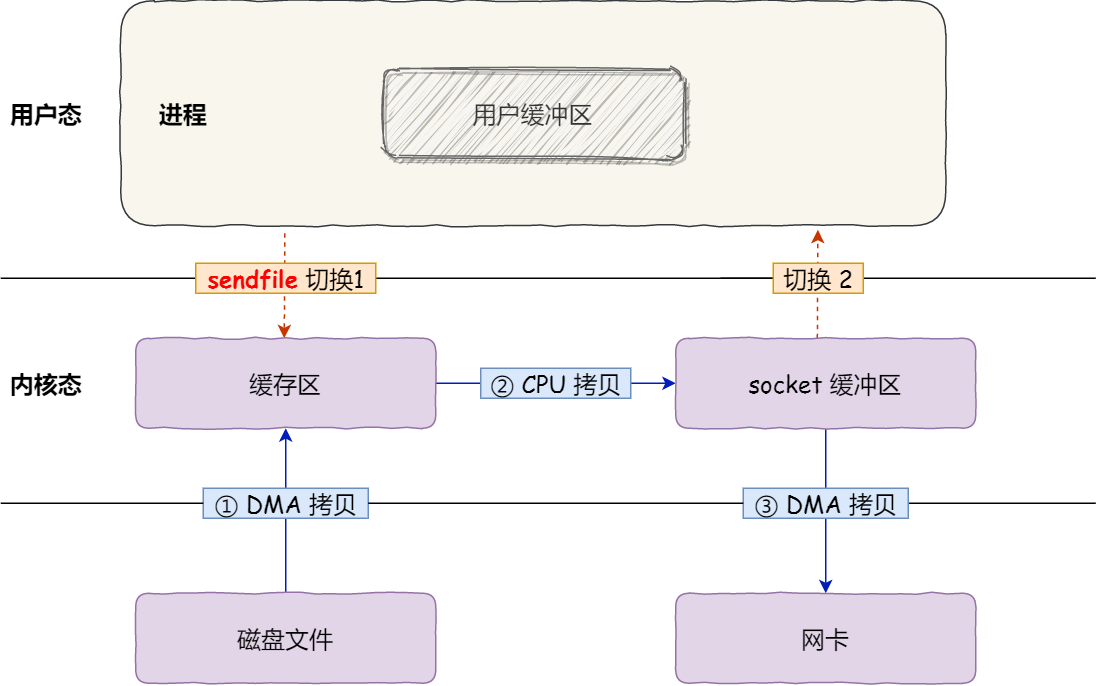
2 次上下文切换,和 3 次数据拷贝
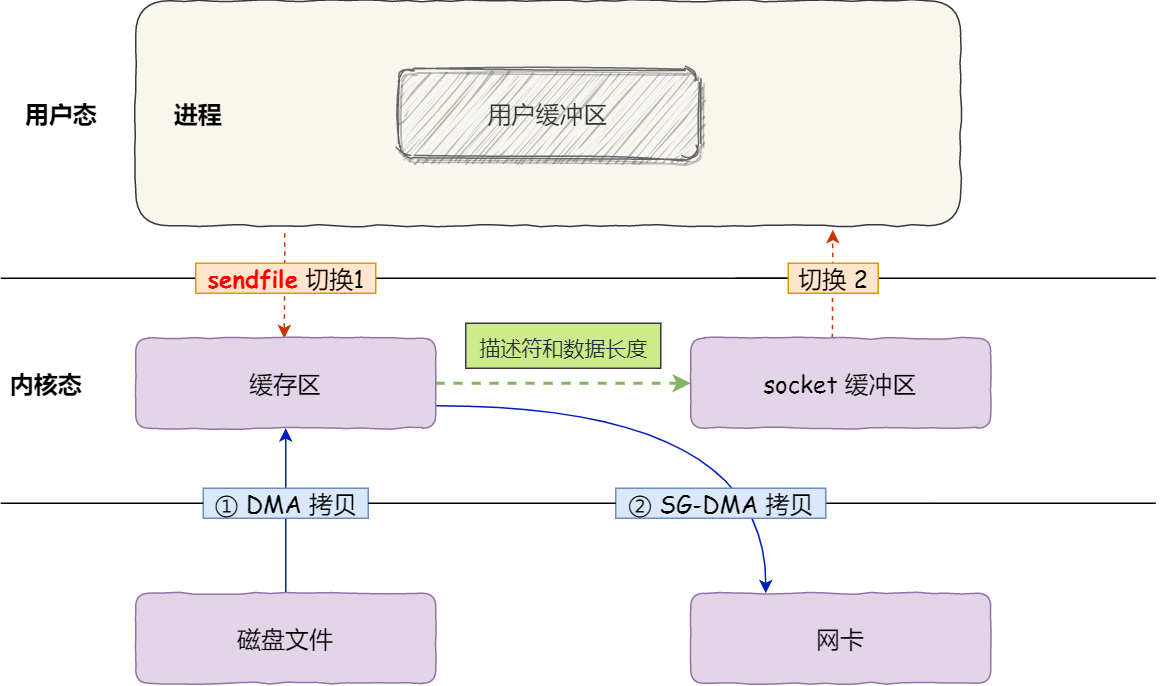
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
PID
进程pid:进程pid(进程ID),每个进程在系统中都有一个唯一·的非负整数表示的进程ID,用getpid() 获取进程ID。
线程tid:线程tid(线程ID),每个线程在所属进程中都有一个唯一的线程ID,用pthread_self() 获取自身现成ID。有多个进程时,可能会出现多个线程ID相同的线程,故线程tid只在其所属的进程上下文中有意义,不能作为系统中某个线程的唯一标识符。
线程pid:线程pid,每个线程在系统中都有一个唯一的pid标识符,用系统调用sys_call(SYS_gettid()) 获取自身线程pid。主线程pid与所在进程pid相同。Linux中的pthread线程库实现的线程其实也是一个进程(LWP),只是该进程与主进程(启动线程的进程)共享一些资源而已,比如代码段,数据段等。在系统中是唯一的,不可重复的
进程能创建多少线程
5.6 一个进程最多可以创建多少个线程? | 小林coding (xiaolincoding.com)
- 32 位系统,用户态的虚拟空间只有 3G,如果创建线程时分配的栈空间是 10M,那么一个进程最多只能创建 300 个左右的线程。
- 64 位系统,用户态的虚拟空间大到有 128T,理论上不会受虚拟内存大小的限制,而会受系统的参数或性能限制。
- /proc/sys/kernel/threads-max,表示系统支持的最大线程数,默认值是
14553; - /proc/sys/kernel/pid_max,表示系统全局的 PID 号数值的限制,每一个进程或线程都有 ID,ID 的值超过这个数,进程或线程就会创建失败,默认值是
32768;(默认2^15,64位系统最多可以修改参数设置为2^22) - /proc/sys/vm/max_map_count,表示限制一个进程可以拥有的VMA(虚拟内存区域)的数量,具体什么意思我也没搞清楚,反正如果它的值很小,也会导致创建线程失败,默认值是
65530。
- /proc/sys/kernel/threads-max,表示系统支持的最大线程数,默认值是
内存回收
4.3 内存满了,会发生什么? | 小林coding (xiaolincoding.com)
内核在给应用程序分配物理内存的时候,如果空闲物理内存不够,那么就会进行内存回收的工作,主要有两种方式:
- 后台内存回收:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能。

- 图中绿色部分:如果剩余内存(pages_free)大于 页高阈值(pages_high),说明剩余内存是充足的;
- 图中蓝色部分:如果剩余内存(pages_free)在页高阈值(pages_high)和页低阈值(pages_low)之间,说明内存有一定压力,但还可以满足应用程序申请内存的请求;
- 图中橙色部分:如果剩余内存(pages_free)在页低阈值(pages_low)和页最小阈值(pages_min)之间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值(pages_high)为止。虽然会触发内存回收,但是不会阻塞应用程序,因为两者关系是异步的。
- 图中红色部分:如果剩余内存(pages_free)小于页最小阈值(pages_min),说明用户可用内存都耗尽了,此时就会触发直接内存回收,这时应用程序就会被阻塞,因为两者关系是同步的。
在经历完直接内存回收后,空闲的物理内存大小依然不够,那么就会触发 OOM 机制,OOM killer 就会根据每个进程的内存占用情况和 oom_score_adj 的值进行打分,得分最高的进程就会被首先杀掉。
我们可以通过调整进程的 /proc/[pid]/oom_score_adj 值,来降低被 OOM killer 杀掉的概率。
申请内存超出物理内存
4.4 在 4GB 物理内存的机器上,申请 8G 内存会怎么样? | 小林coding (xiaolincoding.com)
- 在 32 位操作系统,因为进程理论上最大能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
- 在 64位 位操作系统,因为进程理论上最大能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有 Swap 分区:
- 如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
- 如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;
预读失效和缓存污染
4.5 如何避免预读失效和缓存污染的问题? | 小林coding (xiaolincoding.com)
传统的 LRU 算法法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;(被提前加载进来的页,并没有被访问,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率 。
- 缓存污染导致缓存命中率下降;(批量扫描数据,这些只被访问过一次的数据踢掉了热点数据后不会被访问了,比如select扫描数据库)
为了避免「预读失效」造成的影响,Linux 和 MySQL 对传统的 LRU 链表做了改进:
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active list)和非活跃 LRU 链表(inactive list)。
- MySQL Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
为了避免「缓存污染」造成的影响,Linux 操作系统和 MySQL Innodb 存储引擎分别提高了升级为热点数据的门槛:
- Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
- MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
- 如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;(代表数据依然是短时间内被访问)
- 如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域;(代表数据长期内都会被访问,视作热点数据)
通过提高了进入 active list (或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
缓冲与非缓冲 I/O
文件操作的标准库是可以实现数据的缓存,那么根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O:
- 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
- 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
这里所说的「缓冲」特指标准库内部实现的缓冲。
比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数,毕竟系统调用是有 CPU 上下文切换的开销的。比如说printf。
直接与非直接 I/O
我们都知道磁盘 I/O 是非常慢的,所以 Linux 内核为了减少磁盘 I/O 次数,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是「页缓存」,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
那么,根据是「否利用操作系统的缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O:
- 直接 I/O,不会发生内核缓存和用户程序之间数据复制,而是直接经过文件系统访问磁盘。(然而还是会读到内核态再拷贝到用户态,但是内核不留备份)
- 非直接 I/O,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
如果你在使用文件操作类的系统调用函数时,指定了 O_DIRECT 标志,则表示使用直接 I/O。如果没有设置过,默认使用的是非直接 I/O。
如果用了非直接 I/O 进行写数据操作,内核什么情况下才会把缓存数据写入到磁盘?
以下几种场景会触发内核缓存的数据写入磁盘:
- 在调用
write的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上; - 用户主动调用
sync,内核缓存会刷到磁盘上; - 当内存十分紧张,无法再分配页面时,也会把内核缓存的数据刷到磁盘上;
- 内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上
进程发生了崩溃,已写入的数据会丢失吗
不会
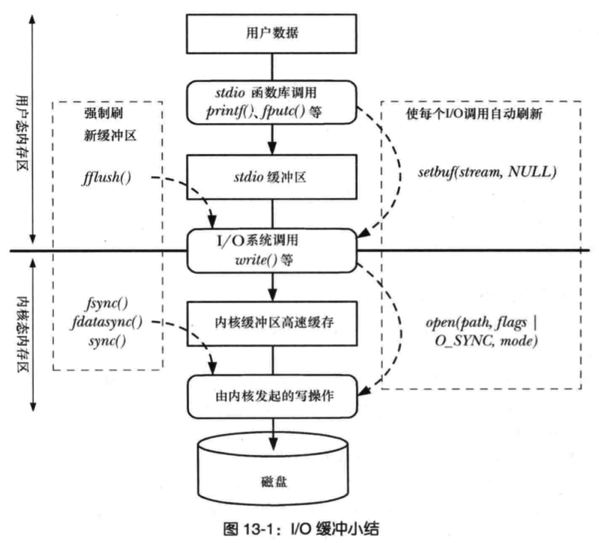
因为进程在执行 write (使用非直接 IO)系统调用的时候,实际上是将文件数据写到了内核的 page cache,它是文件系统中用于缓存文件数据的缓冲,所以即使进程崩溃了,文件数据还是保留在内核的 page cache,我们读数据的时候,也是从内核的 page cache 读取,因此还是依然读的进程崩溃前写入的数据。
内核会找个合适的时机,将 page cache 中的数据持久化到磁盘。但是如果 page cache 里的文件数据,在持久化到磁盘化到磁盘之前,系统发生了崩溃,那这部分数据就会丢失了。
当然, 我们也可以在程序里调用 fsync 函数,在写文件的时候,立刻将文件数据持久化到磁盘,这样就可以解决系统崩溃导致的文件数据丢失的问题。
- 注意printf和fputs是写入标准库缓冲(缓存IO),调用fflush可以把标准库缓冲写入内核缓存
- 而fsync这些就是把内核缓存写入磁盘
一致性哈希
不同的负载均衡算法适用的业务场景也不同的。轮询这类的策略只能适用与每个节点的数据都是相同的场景,访问任意节点都能请求到数据。但是不适用分布式系统,因为分布式系统意味着数据水平切分到了不同的节点上,访问数据的时候,一定要寻址存储该数据的节点。
哈希算法虽然能建立数据和节点的映射关系,但是每次在节点数量发生变化的时候,最坏情况下所有数据都需要迁移,这样太麻烦了,所以不适用节点数量变化的场景。为了减少迁移的数据量,就出现了一致性哈希算法。
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
引入虚拟节点后,可以提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
虚拟节点除了会提高节点的均衡度,还会提高系统的稳定性。当节点变化时,会有不同的节点共同分担系统的变化,因此稳定性更高。
比如,当某个节点被移除时,对应该节点的多个虚拟节点均会移除,而这些虚拟节点按顺时针方向的下一个虚拟节点,可能会对应不同的真实节点,即这些不同的真实节点共同分担了节点变化导致的压力。
而且,有了虚拟节点后,还可以为硬件配置更好的节点增加权重,比如对权重更高的节点增加更多的虚拟机节点即可。
因此,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。


函数调用机制
局部变量占用的内存是在程序执行过程中“动态”地建立和释放的。这种“动态”是通过栈由系统自动管理进行的。当任何一个函数调用发生时,系统都要作以下工作:
(1)建立栈空间;
(2)保护现场:主调函数运行状态和返回地址入栈;
(3)为被调函数中的局部变量分配空间,完成参数传递;
(4)执行被调函数函数体;
(5)释放被调函数中局部变量占用的栈空间;
(6)回复现场:取主调函数运行状态及返回地址,释放栈空间;
(7)继续主调函数后续语句。
CPU多核
每个核都能执行一个线程
多核比多CPU贵,性能好,因为单CPU内通过总线通信快、延迟低,且共享同一块cache
CPU的根本任务就是执行指令,即“0”和“1”组成的机器码。CPU架构可以划分成3个模块,分别是控制单元、运算单元和存储单元,这三部分由CPU内部总线连接起来。
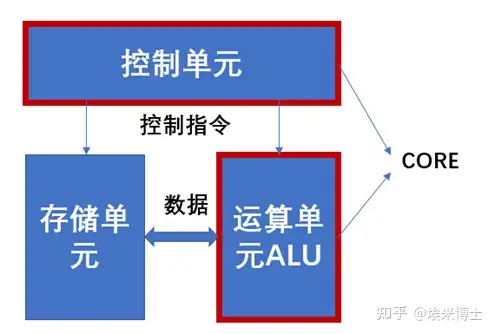
- 控制单元是整个CPU的指挥控制中心,包括指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)、时序发生器和程序计数器等部件,对协调整个电脑有序工作极为重要。
- 运算单元是核心组成部分,其包括执行算术运算和逻辑运算。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
- 存储单元包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。
通常,控制单元和运算单元统称为一个核Core,换言之,单核是指CPU中包括一个控制单元和一个运算单元。那么对于多核CUP而言,就是由多个核组织(多个控制单元和多个运算单元),共用存储单元。
多CPU
多个CPU常见于分布式系统,用于普通消费级市场的不多,多用于cluster,云计算平台什么的。
多CPU架构最大的瓶颈就是I/O,尤其是各个CPU之间的通讯。这主要是每个CPU都有自己的cache,又共享内存,会产生缓存一致性问题,这样速度就慢了。
多核CPU与多个CPU并不冲突,相反,两者会相互结合。目前有些大型机经常会有多个CPU,每个CPU都是多核的。如2个物理CPU,每个物理CPU都有2个核,那么最终的CPU就是4核的。
进程间通信编程
(42条消息) Linux下C++进程间通信机制_linux c++ 进程间通信 单变量设置_醉如泥的博客-CSDN博客
匿名管道
int pipe(int fd[2]) ; 创建一个无名管道fd包含2个文件描述符的数组,fd[0]用于读,fd[1]用于写若成功返回0,否则返回-1。
1 | //一般某个进程用于读,另一个进程用于写,用于读的进程需要close(fd[1]),用于写的进程需要close(fd[0]); |
命名管道
命名管道相当于一个文件。
1、FIFO 在文件系统中作为一个特殊的文件而存在,但 FIFO 中的内容却存放在内存中。
2、当使用 FIFO 的进程退出后,FIFO 文件将继续保存在文件系统中以便以后使用。
3、FIFO 有名字,不相关的进程可以通过打开命名管道进行通信。
int mkfifo(const char *pathname,mode_t mode);
1 |
|
信号量
1 |
|
消息队列
1 | 1、int msgget(key_t key,int msgflg) |
1 |
|
共享内存
共享内存将相同的物理内存地址映射到用户空间,用户可以直接操作
1 | 1、int shmget(key_t key,int size,int shmflg) |
也可以两个进程同时mmap到一个文件,mmap把文件加载到内核空间,然后把这块空间映射到用户空间,用户直接操作这块空间就相当于对内核空间的内存进行读写,然后内核刷脏页,不用在内核和用户中进行切换和拷贝。
下面是二者区别:
1、mmap保存到实际硬盘,实际存储并没有反映到主存上。优点:储存量可以很大(多于主存);缺点:进程间读取和写入速度要比主存的要慢。
2、shm保存到物理存储器(主存),实际的储存量直接反映到主存上。优点,进程间访问速度(读写)比磁盘要快;缺点,储存量不能非常大(多于主存)
使用上看:如果分配的存储量不大,那么使用shm;如果存储量大,那么使用mmap。
CPU时间片大小
Windows 系统中线程轮转时间也就是时间片大约是20ms,如果某个线程所需要的时间小于20ms,那么不到20ms就会切换到其他线程;如果一个线程所需的时间超过20ms,系统也最多只给20ms,除非意外发生(那可能导致整个系统无响应),而Linux/unix中则是5~800ms。
map中红黑树和哈希表比较
- 有序无序:map始终保证遍历的时候是按key的大小顺序的,这是一个主要的功能上的差异。
- 时间复杂度:红黑树的插入删除查找性能都是O(logN),而哈希表的插入删除查找性能理论上都是O(1)。红黑树是相对于稳定的,最差情况下都是高效的。哈希表的插入删除操作的理论上时间复杂度是常数时间的,这有个前提就是哈希表不发生数据碰撞。在发生碰撞的最坏的情况下,哈希表的插入和删除时间复杂度最坏能达到**O(n)**。
- 空间性能:红黑树占用的内存更小(仅需要为其存在的节点分配内存),而Hash事先应该分配足够的内存存储散列表,即使有些槽可能弃用
- 范围查找:map可以做范围查找(中序遍历),而unordered_map不可以。
- 扩容导致迭代器失效。 map的iterator除非指向元素被删除,否则永远不会失效。unordered_map的iterator在对unordered_map修改时有时会失效。
红黑树适合数据量较高的情况。
- put和remove过程中,红黑树要通过左旋,右旋、变色这些操作来保持平衡,另外构造红黑树要比构造链表复杂,在链表的节点不多的时候,从整体的性能看来, 数组+链表+红黑树的结构可能不一定比数组+链表的结构性能高。就好比杀鸡焉用牛刀的意思。
- HashMap频繁的扩容,会造成底部哈希表不断的进行拆分和重组,这是非常耗时的。因此,也就是链表长度比较长的时候转变成红黑树才会显著提高效率。
浏览器为什么使用进程
浏览器使用进程的主要目的是为了提高浏览器的稳定性和安全性,以及增强用户的体验。
- 将浏览器的不同组件(如渲染引擎、JavaScript 解释器、网络请求等)放在不同的进程中可以避免它们之间的相互影响和崩溃。如果一个组件崩溃了,只会导致它所在的进程崩溃,而不会影响到其他进程和组件,从而提高了浏览器的稳定性。此外,通过将插件和扩展程序放在单独的进程中,可以保护浏览器不受它们可能引发的安全漏洞的影响。
- 现代网页使用了大量的代码和资源,包括HTML、CSS、JavaScript等等,这些资源需要浏览器来解析和执行。如果所有的代码和资源都运行在同一个进程中,会造成该进程负载过重,导致浏览器响应缓慢、卡顿、甚至崩溃。因此,将每个网页放到单独的进程中运行,可以将负载分散到多个进程中,从而提高浏览器的性能和稳定性。
- 使用多进程还可以提供更好的用户体验。例如,使用多进程可以在一个标签页崩溃时仅仅关闭该标签页,而不是整个浏览器,从而避免用户丢失已经打开的其他标签页。此外,多进程还可以提供更好的隔离性,使得网站之间的资源无法相互访问,从而增强用户的隐私和安全性。
综上所述,使用进程是浏览器提高稳定性、安全性、性能和用户体验的有效手段之一。
最佳线程数
CPU 密集型
(计算比较多,比如复杂算法)
一个完整请求,I/O操作可以在很短时间内完成, CPU还有很多运算要处理,也就是说 CPU 计算的比例占很大一部分
对于计算密集型的任务,一个有Ncpu个处理器的系统通常通过使用一个Ncpu + 1个线程的线程池来获得最优的利用率(计算密集型的线程恰好在某时因为发生一个页错误或者因其他原因而暂停,刚好有一个“额外”的线程,可以确保在这种情况下CPU周期不会中断工作)。
1 | 最佳线程= cpu核数(逻辑) +1 |
I/O密集型程序
与 CPU 密集型程序相对,一个完整请求,CPU运算操作完成之后还有很多 I/O 操作要做,也就是说 I/O 操作占比很大部分
单核:
1 | 最佳线程数 = ((线程IO时间+线程CPU时间)/线程CPU时间 )* CPU数目 |
计算示例
多核:
1 | 最佳线程数 = CPU核心数 * (1/CPU利用率) = CPU核心数 * (1 + (I/O耗时/CPU耗时)) |
物理CPU(核)和逻辑CPU(核)
一个物理CPU核上如果只有一套寄存器,那就只能运行一个程序的指令,这里面可能有指令空闲的时候(比如load要等几个周期)。
超线程技术就是在一个物理核上做两套寄存器,就能装两个程序的指令,在一个程序指令空闲时插入另一个程序的指令,相当于两个核,也就是两个逻辑核。
锁、信号量底层实现
所谓的锁,在计算机里本质上就是一块内存空间。当这个空间被赋值为1的时候表示加锁了,被赋值为0的时候表示解锁了,仅此而已。多个线程抢一个锁,就是抢着要把这块内存赋值为1。在一个多核环境里,内存空间是共享的。每个核上各跑一个线程,那如何保证一次只有一个线程成功抢到锁呢?这必须要硬件的某种guarantee。
锁总线从而原子赋值
- CPU如果提供一些用来构建锁的atomic指令,譬如x86的CMPXCHG(加上LOCK prefix),能够完成atomic的compare-and-swap(CAS),用这样的硬件指令就能实现spin lock。本质上LOCK前缀的作用是锁定系统总线(或者锁定某一块cache line)来实现atomicity,可以了解下基础的缓存一致协议譬如MSEI。简单来说就是,如果指令前加了LOCK前缀,就是告诉其他核,一旦我开始执行这个指令了,在我结束这个指令之前,谁也不许动。缓存一致协议在这里面扮演了重要角色,这里先不赘述。这样便实现了一次只能有一个核对同一个内存地址赋值。
互斥锁需要维护挂起进程
- 一个spin lock就是让没有抢到锁的线程不断在while里面循环进行compare-and-swap,燃烧CPU,直到前面的线程放手(对应的内存被赋值0)。这个过程不需要操作系统的介入,这是运行程序和硬件之间的故事。如果需要长时间的等待,这样反复CAS轮询就比较浪费资源,这个时候程序可以向操作系统申请被挂起,然后持锁的线程解锁了以后再通知它。这样CPU就可以用来做别的事情,而不是反复轮询。但是OS切换线程也需要一些开销,所以是否选择被挂起,取决于大概是否需要等很长时间,如果需要,则适合挂起切换为别的线程。
- 线程向操作系统请求被挂起是通过一个系统调用,在linux上的实现就是futex,宏观来讲,OS需要一些全局的数据结构来记录一个被挂起线程和对应的锁的映射关系,这样一个数据结构天然是全局的,因为多个OS线程可能同时操作它。所以,实现高效的锁本身也需要锁。有没有一环套一环的感觉?futex的巧妙之处就在于,它知道访问这个全局数据结构不会太耗时,于是futex里面的锁就是spin lock。linux上pthread mutex的实现就是用的futex。
这里面的关系是,互斥锁需要挂起进程,就需要有数据结构记录,这个数据结构本身又不是线程安全的,就需要自旋锁来维护。
信号量与自旋锁的实现机制是不一样的,用处也是不一样的。
- 首先,自旋锁和信号量都使用了计数器来表示允许同时访问共享资源的最大进程数,但自旋锁的共享计数值是1,也就是说任意时刻只有一个进程在共享代码区运行;信号量却允许使用大于1的共享计数,即共享资源允许被多个不同的进程同时访问,当然,信号量的计数器也能设为1,这时信号量也称为互斥量。
- 其次,自旋锁用于保护短时间能够完成操作的共享资源,使用期间不允许进程睡眠和进程切换;信号量常用于暂时无法获取的共享资源,如果获取失败则进程进入不可中断的睡眠状态,只能由释放资源的进程来唤醒。
- 最后,自旋锁可以用于中断服务程序之中;信号量不能在中断服务程序中使用,因为中断服务程序是不允许进程睡眠的。
信号量的使用方式如下:
1 | down(sem); |
首先看函数down(sem)的定义:
1 | static inline void down(struct semaphore * sem) |
这里面包含了一些汇编代码,%0代表sem->count。也就是说先将sem->count减1,LOCK_PREFIX表示执行这条指令时将总线锁住,保证减1操作是原子的。减1之后如果大于或等于0就转到标号2处执行,也就跳过了__down_failed函数直接到函数尾部并返回,成功获取信号量;否则减1之后sem->count小于0则顺序执行后面的__down_failed函数。
1 | static inline void up(struct semaphore * sem) |
首先将sem->count加1,是原子操作,如果加1后sem->count大于0则说明没有进程在等待信号量资源,无须唤醒队列中进程,直接跳转到标号1处返回;否则运行__up_wakeup唤醒等待队列中的进程。
唤醒进程中一个关键的指令是调用函数__up:
1 | fastcall void __up(struct semaphore *sem) |
__up的的工作就是唤醒等待队列中的所有进程,但是由于sem等待队列中的进程 的TASK_EXCLUSIVE标志为 1,因此不会唤醒后续进程了。也就是说up(sem)操作实际上是将sem->count自增1,然后唤醒等待队列中的第一个进程(如果有的话)。
计算机网络
vxlan优势
VXLAN vs VLAN - 知乎 (zhihu.com)
- 子网数量多(不是主要原因)
- 减少交换机mac表,因为一台物理机可以有许多虚拟机(每台虚拟机都有自己的mac地址),交换机要都记录虚拟机的mac是很困难的,但如果物理机就对应一个vtep,那么交换机看到的只是一台vtep在传输数据。(主要原因)
TCP 粘包
4.6 如何理解是 TCP 面向字节流协议? | 小林coding (xiaolincoding.com)
TCP基于字节流,无法判断发送方报文段边界(TCP并不维护数据边界)
多个数据包被连续存储于连续的缓存中,在对数据包进行读取时由于无法确定发生方的发送边界,而采用某一估测值大小来进行数据读出,若发送方发送数据包的长度和接收方在缓存中读取的数据包长度不一致,就会发生粘包。
很多地方这里没讲清楚:
- 实际上TCP报文中的报文头部是可以提供正确的数据信息的,这个过程由内核封装与解封,对接收端来说它看到的信息是绝对正确的。
- 问题出在接收端即使收到了正确的信息,也分不清消息的边界,也就是说接收端看到的一条消息可能与发送端的不一样,这就是问题所在。
- 例如发送两条信息”hello”和”world”,接收端可能当作一条消息处理”helloworld”或者当成不同的多片报文处理。
解决方法主要是确定边界:
- 发送方关闭Nagle算法,使用TCP_NODELAY选项关闭Nagle功能
- 发送定长的数据包。每个数据包的长度一样,接收方可以很容易区分数据包的边界
- 数据包末尾加上\r\n标记,模仿FTP协议,但问题在于如果数据正文中也含有\r\n,则会误判为消息的边界
- 数据包头部加上数据包的长度。数据包头部定长4字节,可以存储数据包的整体长度
- 应用层自定义规则
Nagle算法主要用来预防小分组的产生。在广域网上,大量TCP小分组极有可能造成网络的拥塞。
Nagle时针对每一个TCP连接的。它要求一个TCP连接上最多只能有一个未被确认的小分组。在该分组的确认到达之前不能发送其他小分组。TCP会搜集这些小的分组,然后在之前小分组的确认到达后将刚才搜集的小分组合并发送出去。
DNS 解析过程以及 DNS 劫持
DNS查询的过程简单描述就是:主机向本地域名服务器发起某个域名的DNS查询请求,如果本地域名服务器查询到对应IP,就返回结果,否则本地域名服务器直接向根域名服务器发起DNS查询请求,要么返回结果,要么告诉本地域名服务器下一次的请求服务器IP地址,下一次的请求服务器可能是顶级域名服务器也可能还是根域名服务器,然后继续查询。(这是迭代查询,也可以递归查询,就是本地域名服务器直接去查上级服务器,不用本地主机去访问)
在完成整个域名解析的过程之后,并没有收到本该收到的IP地址,而是接收到了一个错误的IP地址。比如输入的网址是百度,但是却进入了奇怪的网址,并且地址栏依旧是百度。在这个过程中,攻击者一般是修改了本地路由器的DNS地址,从而访问了一个伪造的DNS服务器,这个伪造的服务器解析域名的时候返回了一个攻击者精心设计的网站,这个网站可能和目标网站一模一样,当用户输入个人账户时,数据会发送给攻击者,从而造成个人财产的丢失。
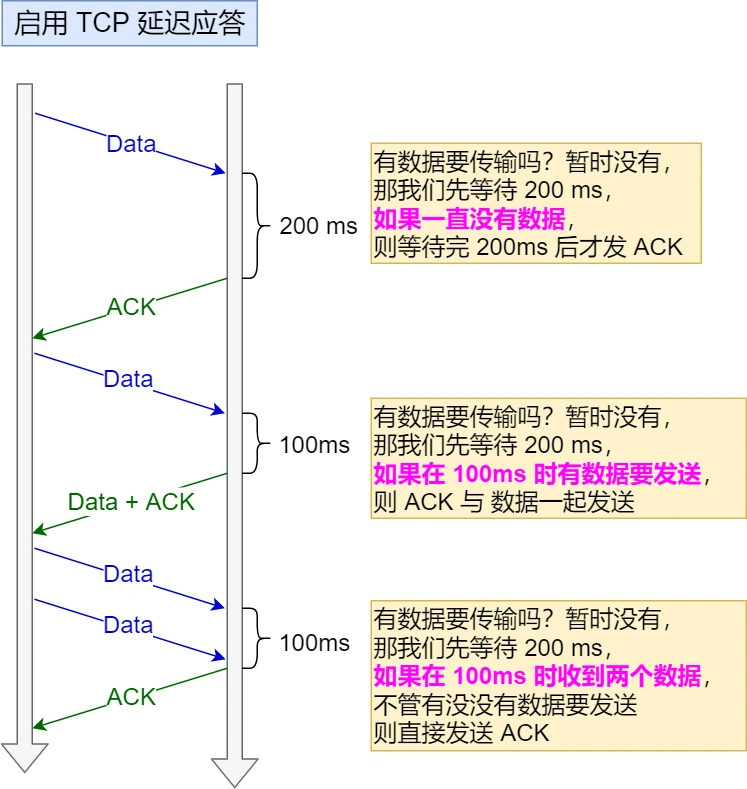
TCP 延迟确认
当发送没有携带数据的 ACK,它的网络效率也是很低的,因为它也有 40 个字节的 IP 头 和 TCP 头,但却没有携带数据报文。 为了解决 ACK 传输效率低问题,所以就衍生出了 TCP 延迟确认。 TCP 延迟确认的策略:
- 当有响应数据要发送时,ACK 会随着响应数据一起立刻发送给对方
- 当没有响应数据要发送时,ACK 将会延迟一段时间,以等待是否有响应数据可以一起发送
- 如果在延迟等待发送 ACK 期间,对方的第二个数据报文又到达了,这时就会立刻发送 ACK
当被动关闭方在 TCP 挥手过程中,「没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。
ECN 显式拥塞通知
显式拥塞通知Explicit Congestion Notification(ECN)是TCP/IP协议的扩展,在RFC 3168 (2001) 中进行了定义。ECN支持端到端的网络拥塞通知。
它通过在IP头部嵌入一个拥塞指示器和在TCP头部嵌入一个拥塞确认实现。兼容ECN的交换机和路由器会在检测到拥塞时对网络数据包打标记。IP头部的拥塞指示也可以用于RoCEv2的拥塞控制。下面是IP头部的前四个帧的格式:
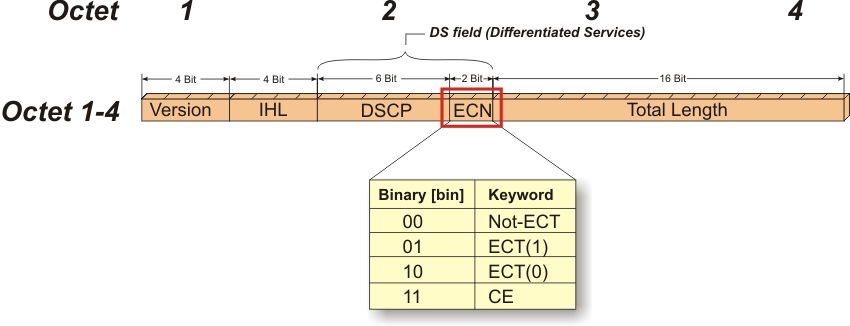
通常情况下,当网络中出现拥塞的时候,TCP/IP会主动丢弃数据包。源端检测到丢包后,就会减小拥塞窗口,降低传输速率。
但如果端到端能成功协商ECN的话,支持ECN的路由器就可以发生拥塞时在IP报头中设置一个标记,发出即将发生拥塞的信号,而不是直接丢弃数据包。
ECN减少了TCP的丢包数量,通过避免重传,减少了延迟(尤其是抖动),提升了应用的性能。
- ECN需要主动队列管理AQM策略结合才能发挥作用。路由器在队列溢出前检测到拥塞,在IP报头中设置Congestion Experienced (CE) Codepoint代码点来指示正在发生拥塞。
- 在当前的Internet上,丢包是对端节点进行拥塞通知的重要机制,解决路由器”满队列”的方法便是在队列充满之前丢包,这样端节点便能在队列溢出前对拥塞做出反应。这种方法便称为”主动式队列管理”(Active Queue Management)。AQM是一族基于FIFO调度策略的队列管理机制,使得路由器能够控制在什么时候丢多少包,以支持端到端的拥塞控制。
RED 随机早期检测
RED(随机早期检测)可以有效防止TCP全局同步。其做法是在队列满之前就对已入队的报文进行随机丢弃,RED的特点在于“早期”和“随机”,这使得不同的流量在不同的时刻以“无规律”的方式丢弃,从而有效避免了所有的TCP连接发生同步震荡。
- Low-Limit:最低丢弃门限,平均队列长度超过门限时,RED开始丢弃报文,值越低,队列越早开始丢弃报文
- High-Limit:最高丢弃门限,平均队列长度超过此门限时,RED将丢弃所有到来的报文。
- Pmax:最大丢弃概率,即RED丢弃报文条件下报文被丢弃的最大概率,这个值通常不为100%。
- 当前平均队列长度小于Low-Limit时,不丢弃报文
- 当前平均队列长度超过High-Limit时,丢弃所有到来的报文
- 当前平均队列长度在Low-Limit和High-Limit之间时,开始随机丢弃到来的报文。
尾部丢弃
队列]满时路由器进行尾丢弃,即新到的所有数据包都全部丢弃,丢弃的结果造成高延迟、高抖动、丧失服务保证、TCP全局同步、TCP饿死等问题,从而导致应用超时、数据重传和实时业务不可用等一系列问题
TCP全局同步:没有差别的丢弃会造成所有TCP流的报文几乎在同一时刻丢弃,TCP又几乎在同一时刻重传。TCP窗口会在几乎同一时刻缩小,然后又几乎同一时刻增大,这将造成所有TCP连接的流量以相同的“频率”持续震荡。TCP全局同步的结果是TCP传输效率急剧下降,并且带宽的平均利用率大大降低。
增加队列长度可以减少丢弃,但无法从根本上解决问题,队列长度受限于资源,不能无限制增加,增加队列长度也增加了报文的平均延迟和抖动,在尾丢弃发生前,使不同TCP连接的报文在不同时刻被丢弃,则各个TCP连接的流量震荡就不会同步。
TCP什么时候会把一个包分成多个发送
一般情况下,如果TCP数据包的大小小于网络链路的MTU大小,则不需要分包。但是,在某些情况下,即使TCP数据包的大小小于MTU,也可能发生分包。例如,在某些网络中,可能会对数据包进行分段,以便进行负载均衡或实现其他网络优化。此外,在某些安全设备中,也可能会对数据包进行拆分和重新组装,以便进行检查和过滤。因此,虽然TCP数据包小于MTU大小,但在某些情况下可能仍然会发生分包。
TCP 11种状态
详解TCP的11种状态 - 腾讯云开发者社区-腾讯云 (tencent.com)
数据库MySQL
B+树如何减少IO
在InnoDB引擎中存放数据的单位是页,每一页的大小是16KB。
对于InnoDB引擎而言,每一个数据页都存放的是同一个高度的树结点。从根页开始,通过指针寻找到下一层高度的索引页时,要从硬盘里把索引页拿出来,就产生了IO。
红黑树太高了,IO太多。B树非叶结点有数据(存储了当前节点对应的索引的数据),所以层数还是比B+树高,因为阶少1。以及,B+树叶子节点有双向链表,能做范围查询。
为什么用B+树不用哈希表
- 哈希索引不支持排序与范围查找,因为哈希表是无序的。
- 因为哈希表中会存在哈希冲突,所以哈希索引的性能是不稳定的,而B+树索引的性能是相对稳定的,每次查询都是从根节点到叶子节点。
- 哈希索引不支持模糊查询及多列索引的最左前缀匹配。
innodb 和 myisam 的区别
关于索引,innodb索引到数据,myisam索引到地址
innodb增删改更快:MyIsam是表级锁,如果在增删改频繁操作的场景下,会慢。
myisam查询更快:
- 1)数据块,InnoDB要缓存,MyISAM只缓存索引块, 这中间还有换进换出的减少;
- 2)InnoDB寻址要映射到块,再到行,MyISAM记录的直接是文件的OFFSET,定位比InnoDB要快
- 3)InnoDB还需要维护MVCC一致; 虽然你的场景没有,但他还是需要去检查和维护
InnoDB 的 MVCC
它是一种用来解决读-写冲突的无锁并发控制机制。在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能。
隐藏列:InnoDB中每行数据都有隐藏列,隐藏列中包含了本行数据的事务id、指向undo log的指针等。
基于undo log的版本链:每行数据的隐藏列中包含了指向undo log的指针,而每条undo log也会指向更早版本的undo log,从而形成一条版本链。
ReadView(一致性视图):通过隐藏列和版本链,MySQL可以将数据恢复到指定版本。但是具体要恢复到哪个版本,则需要根据ReadView来确定。所谓ReadView,是指事务(记做事务A)在某一时刻给整个事务系统(trx_sys)打快照,之后再进行读操作时,会将读取到的数据中的事务id与trx_sys快照比较,从而判断数据对该ReadView是否可见,即对事务A是否可见。
连接池最大最小连接
这实际上是动态控制连接数,在资源和响应时间中做一个均衡。
数据库连接池最小连接数和最大连接数:
- 最小连接数是连接池一直保持的数据连接。如果应用程序对数据库连接的使用量不大的话,一直维持较多的连接数就会有大量的数据库连接资源被浪费掉。
- 最大连接数是连接池能申请的最大连接数。如果数据连接请求超过此数,后面的数据连接请求将被加入到等待队列中,这会影响之后的数据库操作。
- 超过最小连接数量的连接请求等价于建立一个新的数据库连接。这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放。
上面的解释,可以这样理解:数据库池连接数量一直保持一个不少于最小连接数的数量,当数量不够时,数据库会创建一些连接,直到一个最大连接数,之后连接数据库就会等待。
对于连接的管理可使用空闲池。即把已经创建但尚未分配出去的连接按创建时间存放到一个空闲池中。
- 每当用户请求一个连接时,系统首先检查空闲池内有没有空闲连接。
- 如果有就把建立时间最长(通过容器的顺序存放实现)的那个连接分配给他(实际是先做连接是否有效的判断,如果可用就分配给用户,如不可用就把这个连接从空闲池删掉,重新检测空闲池是否还有连接);
- 如果没有则检查当前所开连接池是否达到连接池所允许的最大连接数(maxconn)如果没有达到,就新建一个连接,如果已经达到,就等待一定的时间(timeout)。
- 如果在等待的时间内有连接被释放出来就可以把这个连接分配给等待的用户,如果等待时间超过预定时间timeout 则返回空值(null)。
- 系统对已经分配出去正在使用的连接只做计数,当使用完后再返还给空闲池。对于空闲连接的状态,可开辟专门的线程定时检测,这样会花费一定的系统开销,但可以保证较快的响应速度。也可采取不开辟专门线程,只是在分配前检测的方法。
Linux 内核
huge page
64 位的 Linux 系统中(英特尔 x64 CPU),虚拟内存地址转换成物理内存地址的过程:
页表 分为 4 级:页全局目录、页上级目录、页中间目录 和 页表 目的是为了减少内存消耗。
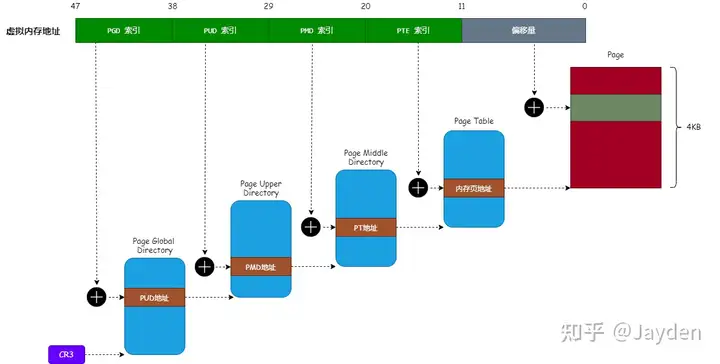
有些场景我们希望使用更大的内存页作为映射单位(如 2MB)。使用更大的内存页作为映射单位有如下好处:
- 减少
TLB(Translation Lookaside Buffer)的失效情况。 - 减少
页表的内存消耗。
Tips:
TLB是一块高速缓存,TLB 缓存虚拟内存地址与其映射的物理内存地址。MMU 首先从 TLB 查找内存映射的关系,如果找到就不用回溯查找页表。否则,只能根据虚拟内存地址,去页表中查找其映射的物理内存地址。比如要查第100页实际的物理页,那么TLB就记录了(100,x)的映射,x就是物理页。如果TLB没有记录的话,就要去页表找,一方面页表比较大,一方面内存比缓存慢,都导致性能下降。
因为映射的内存页越大,所需要的 页表 就越小(条目少),大大减少由内核加载的映射表的数量;页表 越小,TLB 失效的情况就越少。
使用大于 4KB 的内存页作为内存映射单位的机制叫 HugePages,目前 Linux 常用的 HugePages 大小为 2MB 和 1GB,我们以 2MB 大小的内存页作为例子。
要映射更大的内存页,只需要增加偏移量部分。
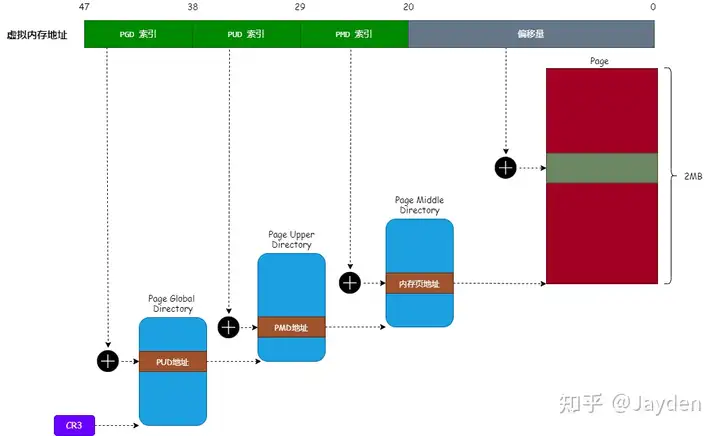
在linux中,使用分三步:
挂载 Hugetlb 文件系统:
- ```shell
$ mkdir /mnt/huge
$ mount none /mnt/huge -t hugetlbfs1
2
3
4
5
* **初始化**HugePages:`/proc/sys/vm/nr_hugepages` 文件保存了内核可以使用的 HugePages 数量
* ```shell
$ echo 20 > /proc/sys/vm/nr_hugepages //设置了可用的 HugePages 数量为 20 个
- ```shell
使用mmap:要使用 HugePages,必须使用
mmap系统调用把虚拟内存映射到 Hugetlb 文件系统中的文件
epoll
select和epoll的区别
- 首先select是posix支持的,而epoll是linux特定的系统调用,因此,epoll的可移植性就没有select好,但是考虑到epoll和select一般用作服务器的比较多,而服务器中大多又是linux,所以这个可移植性的影响应该不会很大。
- 其次,select可以监听的文件描述符有限,最大值为1024,而epoll可以监听的文件描述符则是系统对整个进程限制的最大文件描述符。
- 接下来就要谈epoll和select的性能比较了,这个一般情况下应该是epoll表现好一些,否则linux也不会去特定实现epoll函数了,那么epoll为什么比select更高效呢?原因有很多,第一点,epoll通过每次有就绪事件时都将其插入到一个就绪队列中,使得epoll_wait的返回结果中只存储了已经就绪的事件,而select则返回了所有被监听的事件,事件是否就绪需要应用程序去检测,那么如果已被监听但未就绪的事件较多的话,对性能的影响就比较大了。第二点,每一次调用select获得就绪事件时都要将需要监听的事件重复传递给操作系统内核,而epoll对监听文件描述符的处理则和获得就绪事件的调用分开,这样获得就绪事件的调用epoll_wait就不需要重新传递需要监听的事件列表,这种重复的传递需要监听的事件也是性能低下的原因之一。除此之外,epoll的实现中使用了mmap调用使得内核空间和用户空间共享内存,从而避免了过多的内核和用户空间的切换引起的开销。
- 然后就是epoll提供了两种工作模式,一种是水平触发模式,这种模式和select的触发方式是一样的,要只要文件描述符的缓冲区中有数据,就永远通知用户这个描述符是可读的,这种模式对block和noblock的描述符都支持,编程的难度也比较小;而另一种更高效且只有epoll提供的模式是边缘触发模式,只支持nonblock的文件描述符,他只有在文件描述符有新的监听事件发生的时候(例如有新的数据包到达)才会通知应用程序,在没有新的监听时间发生时,即使缓冲区有数据(即上一次没有读完,或者甚至没有读),epoll也不会继续通知应用程序,使用这种模式一般要求应用程序收到文件描述符读就绪通知时,要一直读数据直到收到EWOULDBLOCK/EAGAIN错误,使用边缘触发就必须要将缓冲区中的内容读完,否则有可能引起死等,尤其是当一个listen_fd需要监听到达连接的时候,如果多个连接同时到达,如果每次只是调用accept一次,就会导致多个连接在内核缓冲区中滞留,处理的办法是用while循环抱住accept,直到其出现EAGAIN。这种模式虽然容易出错,但是性能要比前面的模式更高效,因为只需要监听是否有事件发生,发生了就直接将描述符加入就绪队列即可。
select的缺点
select的缺点:
- 单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在linux内核头文件中,有这样的定义:#define __FD_SETSIZE 1024)
- 内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销;
- (不是返回就绪数组)select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
1 | 通俗版本可能是这样的: |
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
epoll底层
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
1 | struct eventpoll{//置于缓存中,很快 |
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
1 | 有的人误以为 epoll 高效的全部因为这棵红黑树,这就有点夸大红黑树的作用了。 |
所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。也是通过这个回调关系(更具体来说是一个指针),根据socket能直接找到epitem(我们创建记录的fd只是为了能找到socket),epitem中又包含了fd供用户使用。那为什么又要红黑树呢?因为要管理这些事件,当事件要关闭时还要找得到事件来关闭。
在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
1 | struct epitem{//事件对应一个fd |
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。


api
int epoll_create(int size)
- 创建一个指示epoll内核事件表的文件描述符,该描述符将用作其他epoll系统调用的第一个参数,size不起作用。(从Linux 2.6.8开始,max_size参数将被忽略,但必须大于零。)
- 成功时,返回一个非负文件描述符。发生错误时,返回-1,并且将errno设置为指示错误
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
该函数用于操作内核事件表监控的文件描述符上的事件:注册、修改、删除
epfd:为epoll_creat的句柄
op:表示动作,用3个宏来表示:
- EPOLL_CTL_ADD (注册新的fd到epfd),相当于把fd加到epfd这棵红黑树上
- EPOLL_CTL_MOD (修改已经注册的fd的监听事件),
- EPOLL_CTL_DEL (从epfd删除一个fd);
fd:文件描述符
event:告诉内核需要监听的事件,结构如下:
1
2
3
4
5
6
7
8
9
10
11typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events,是一串比特,设置类型时把类型或起来 */
epoll_data_t data; /* User data variable */
};events描述事件类型,其中epoll事件类型有以下几种
- EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭)
- EPOLLOUT:表示对应的文件描述符可以写
- EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来)
- EPOLLERR:表示对应的文件描述符发生错误
- EPOLLHUP:表示对应的文件描述符被挂断;
- EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)而言的
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout)
该函数用于等待所监控文件描述符上有事件的产生,返回就绪的文件描述符个数
events:用来存内核得到事件的集合,
maxevents:告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,
timeout:是超时时间
- -1:阻塞
- 0:立即返回,非阻塞
- >0:指定毫秒,没有事件触发会等待,但有事件触发就立即返回
返回值:成功返回有多少文件描述符就绪,时间到时返回0,出错返回-1
触发模式:
LT水平触发模式
- 当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,当应用程序下一次调用epoll_wait时,epoll还会再次向应用程序通知此事件,直到该事件被处理完毕。
ET边缘触发模式
- 当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序必须立即处理该事件,因为后续的epoll_wait调用将不再向应用程序通知这一事件。
- 必须要一次性将数据读取完,使用非阻塞I/O,读取到出现eagain
ET模式在很大程度上降低了同一个epoll事件被重复触发的次数,故效率要比LT模式高。LT模式是epoll的默认工作模式
EPOLLONESHOT
- 一个线程读取某个socket上的数据后开始处理数据,在处理过程中该socket上又有新数据可读,此时另一个线程被唤醒读取,此时出现两个线程处理同一个socket
- 我们期望的是一个socket连接在任一时刻都只被一个线程处理,通过epoll_ctl对该文件描述符注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理,当该线程处理完后,需要通过epoll_ctl重置epolloneshot事件
ET和LT模式的应用场景分别是:
- ET模式适用于高并发、高性能的网络服务器,如Nginx、Redis等。ET模式可以避免重复处理相同的事件,减少系统开销。但是ET模式需要注意数据的完整读写,否则可能会导致数据丢失或错乱。
- LT模式适用于低并发、低性能的网络服务器,如Apache等。LT模式可以简化编程逻辑,保证数据的完整读写。但是LT模式可能会造成事件的频繁触发,增加系统开销。
unix域套接字
多进程reactor模式下,主进程要给其他进程传送文件描述符时,需要使用unix域套接字。因为线程是共享文件描述符的,同一个int对应的文件是相同的,但不同进程间相同的文件描述符对应的文件可能是不同的,所以不能简单传送一个数字。
进程间传递打开的文件描述符,并不是传递文件描述符的值。
文件描述符的值与文件没有关系,只是文件在该进程中的一个标志。同一个文件在不同进程中的文件描述符的值可能不一样,且一样的文件描述符的值可能指向不同的文件。

- 文件描述符表(项):存在于进程中,不同的进程有各自的文件描述符表,每个表项存放者文件描述相关的结构,包括fd值即文件表指针。
- 文件表(项):存在内核中,进程中每个打开的文件生成的文件描述符表项都在内核会关联一个文件表项,包括当前文件偏移量,这样才能使每个进程都有它自己的对该文件的当前偏移量。V结点指针:指向的是同一V结点
- V结点表(项):存在于内核中,每个打开的文件只有一个V结点,包含文件类型,对文件进行操作的函数指针,有的还包括 i 节点。
UNIX域套接字用于在同一台机器上运行的进程之间的通信。UNIX域套接字提供流和数据包两种接口。UNIX域套接字是套接字和管道之间的混合物。为了创建一对非命名的、相互连接的UNIX域套接字,可以使用socketpair函数。
1 |
|
pipe创建的管道,第一描述符的写端和第二描述符的读端都被关闭,socketpair创建的则是全双工UNIX域套接字。
使用面向网络的域套接字接口,可以创建命名UNIX域套接字,使无关进程之间也可以用UNIX域套接字进行通信。UNIX域套接字的地址由sockaddr_un结构表示:
1 |
|
UNIX域套接字没有端口号,依靠唯一的路径名来标识。
UNIX域套接字可以用来传送文件描述符。描述符传递不是简单的传送一个int类型的描述符的值,而是在接收进程中创建一个新的描述符,这个描述符与发送进程的描述符指向内核文件表中的相同项。
当发送进程将描述符传送给接收进程后,通常它关闭该描述符。被发送者关闭的描述符并不真正关闭文件或设备,因为描述符在接收进程里仍视为打开的,即使接收者还没有明确地收到这个描述符。
惊群效应
深入浅出 Linux 惊群:现象、原因和解决方案 - 腾讯云开发者社区-腾讯云 (tencent.com)
惊群效应也有人叫做雷鸣群体效应,不过叫什么,简言之,惊群现象就是多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只可能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群。
惊群效应到底消耗了什么?
- 系统对用户进程/线程频繁地做无效的调度,上下文切换系统性能大打折扣。
- 为了确保只有一个线程得到资源,用户必须对资源操作进行加锁保护,进一步加大了系统开销。
Accept”惊群”现象
在网络分组通信中,网络数据包的接收是异步进行的,因为你不知道什么时候会有数据包到来。因此,网络收包大体分为两个过程:
1 | [1] 数据包到来后的事件通知 |

对于高性能的服务器而言,为了利用多 CPU 核的优势,大多采用多个进程(线程)同时在一个 listen socket 上进行 accept 请求。多个进程阻塞在 Accept 调用上,那么在协议栈将 Client 的请求 socket 放入 listen socket 的 accept 队列的时候,是要唤醒一个进程还是全部进程来处理呢?
linux 内核通过睡眠队列来组织所有等待某个事件的 task,而 wakeup 机制则可以异步唤醒整个睡眠队列上的 task,wakeup 逻辑在唤醒睡眠队列时,会遍历该队列链表上的每一个节点,调用每一个节点的 callback,从而唤醒睡眠队列上的每个 task。这样,在一个 connect 到达这个 lisent socket 的时候,内核会唤醒所有睡眠在 accept 队列上的 task。N 个 task 进程(线程)同时从 accept 返回,但是,只有一个 task 返回这个 connect 的 fd,其他 task 都返回-1**(EAGAIN)**。这是典型的 accept”惊群”现象。
在linux2.6版本以后,linux内核已经解决了accept()函数的“惊群”现象,大概的处理方式就是,当内核接收到一个客户连接后,只会唤醒等待队列上的第一个进程(线程),所以如果服务器采用accept阻塞调用方式,在最新的linux系统中已经没有“惊群效应”了
select/poll/Epoll “惊群”现象
通常一个 server 有很多其他网络 IO 事件要处理,我们并不希望 server 阻塞在 accept 调用上,为提高服务器的并发处理能力,我们一般会使用 select/poll/epoll I/O 多路复用技术,同时为了充分利用多核 CPU,服务器上会起多个进程(线程)同时提供服务。于是,在某一时刻多个进程(线程)阻塞在 select/poll/epoll_wait 系统调用上,当一个请求上来的时候,多个进程都会被 select/poll/epoll_wait 唤醒去 accept,然而只有一个进程(线程 accept 成功,其他进程(线程 accept 失败,然后重新阻塞在 select/poll/epoll_wait 系统调用上。
在多进程服务中使用 epoll 的时候,是先 epoll_create 得到 epoll fd 后在 fork 子进程,还是先 fork 子进程,然后每个子进程在 epoll_create 自己独立的 epoll fd 呢?有什么异同?
先 epoll_create 后 fork
这样,多个进程公用一个 epoll 实例(父子进程的 epoll fd 指向同一个内核 epoll 对象),这种情况下,epoll 有以下这些特性:
- [1] epoll在ET模式下不存在“惊群”现象,LT模式是epoll“惊群”的根源,并且LT模式下的“惊群”没办法避免。
- [2] LT的“惊群”是链式唤醒的,唤醒过程直到当前epi的事件被处理了,无法获得到新的事件才会终止唤醒过程。 例如有A、B、C、D…等多个进程task睡眠在epoll的睡眠队列上,并且都监控同一个listen fd的可读事件。一个请求上来,会首先唤醒A进程,A在epoll_wait的处理过程中会唤醒进程B,这样进程B在epoll_wait的处理过程中会唤醒C,这个时候A的epoll_wait处理完成返回,进程A调用accept读取了当前这个请求,进程C在自己的epoll_wait处理过程中,从epi中获取不到事件了,于是终止了整个链式唤醒过程。 (因为LT会一直触发直到事件完成,这是epoll产生的惊群,而非fd唤醒导致的)
- [3] ET模式下,一个fd上的同事多个事件上来,只会唤醒一个睡眠在epoll上的task,如果该task没有处理完这些事件,在没有新的事件上来前,epoll不会在通知task去处理。
由于 ET 的事件通知模式,通常在 ET 模式下的 epoll_wait 返回,我们会循环 accept 来处理所有未处理的请求,直到 accept 返回 EAGAIN 才退出 accept 流程。否则,没处理遗留下来的请求,这个时候如果没有新的请求过来触发 epoll_wait 返回,这样遗留下来的请求就得不到及时处理。这种处理模式,会带来一种类”惊群”现象。考虑,下面的一个处理过程:A、B、C三个进程在监听listen fd的EPOLLIN事件,都睡眠在epoll_wait上,都是ET模式。
- [1] listen fd上一个请求C_1上来,该请求唤醒了A进程,A进程从epoll_wait返回准备去accept该请求来处理。
- [2] 这个时候,第二个请求C_2上来,由于睡眠队列上是B、C,于是epoll唤醒B进程,B进程从epoll_wait返回准备去accept该请求来处理。
- [3] A进程在自己的accept循环中,首选accept得到C_1,接着A进程在第二个循环继续accept,继续得到C_2。
- [4] B进程在自己的accept循环中,调用accept,由于C_2已经被A拿走了,于是B进程accept返回EAGAIN错误,于是B进程退出accept流程重新睡眠在epoll_wait上。
- [5] A进程继续第三个循环,这个时候已经没有请求了, accept返回EAGAIN错误,于是A进程也退出accept处理流程,进入请求的处理流程。
可以看到,B 进程被唤醒了,但是并没有事情可以做,同时,epoll 的 ET 这样的处理模式,负载容易出现不均衡。(可以用epolloneshot)
先 fork 后 epoll_create
用法上,通常是在父进程创建了 listen fd 后,fork 多个 worker 子进程来共同处理同一个 listen fd 上的请求。这个时候,A、B、C…等多个子进程分别创建自己独立的 epoll fd,然后将同一个 listen fd 加入到 epoll 中,监听其可读事件。这种情况下,epoll 有以下这些特性:
- [1] 由于相对同一个listen fd而言, 多个进程之间的epoll是平等的,于是,listen fd上的一个请求上来,会唤醒所有睡眠在listen fd睡眠队列上的epoll,epoll又唤醒对应的进程task,从而唤醒所有的进程(这里不管listen fd是以LT还是ET模式加入到epoll)。 (这是fd导致的惊群,会唤醒挂载在fd下的所有epoll)
- [2] 多个进程间的epoll是独立的,对epoll fd的相关epoll_ctl操作相互独立不影响。
在使用友好度方面,多进程独立 epoll 实例要比共用 epoll 实例的模式要好很多。独立 epoll 模式要解决 fd 的排他唤醒 epoll 即可。
linux4.5 以后的内核版本中,增加了 EPOLLEXCLUSIVE, 该选项只能通过 EPOLL_CTL_ADD 对需要监控的 fd(例如 listen fd)设置 EPOLLEXCLUSIVE 标记。这样 epoll entry 是通过排他方式挂载到 listen fd 等待队列的尾部的,睡眠在 listen fd 的等待队列上的 epoll entry 会加上 WQ_FLAG_EXCLUSIVE 标记。listen fd 上的事件上来,在遍历并唤醒等待队列上的 entry 的时候,遇到并唤醒第一个带 WQ_FLAG_EXCLUSIVE 标记的 entry 后,就结束遍历唤醒过程。于是,多进程独立 epoll 的”惊群”问题得到解决。
“惊群”之 SO_REUSEPORT
对于大多采用 MPM 机制(multi processing module)TCP 服务而言,基本上都是多个进程或者线程同时在一个 Listen socket 上进行监听请求。根据前面介绍的 Linux 睡眠队列的唤醒方式,基本睡眠在这个 listen socket 上的 Task 只能要么全部被唤醒,要么被唤醒一个。
这是因为单个fd会唤醒挂载在自身上的睡眠的epoll,epoll唤醒task,那如果每个task对应一个fd,就解决了惊群效应。
于是,基本的解决方案是起多个 listen socket,好在我们有 SO_REUSEPORT(linux 3.9 以上内核支持),它支持多个进程或线程 bind 相同的 ip 和端口,支持以下特性:
- [1] 允许多个socket bind/listen在相同的IP,相同的TCP/UDP端口
- [2] 目的是同一个IP、PORT的请求在多个listen socket间负载均衡
- [3] 安全上,监听相同IP、PORT的socket只能位于同一个用户下
于是,在一个多核 CPU 的服务器上,我们通过 SO_REUSEPORT 来创建多个监听相同 IP、PORT 的 listen socket,每个进程监听不同的 listen socket。这样,在只有 1 个新请求到达监听的端口的时候,内核只会唤醒一个进程去 accept,而在同时并发多个请求来到的时候,内核会唤醒多个进程去 accept,并且在一定程度上保证唤醒的均衡性。SO_REUSEPORT 在一定程度上解决了”惊群”问题,但是,由于 SO_REUSEPORT 根据数据包的四元组和当前服务器上绑定同一个 IP、PORT 的 listen socket 数量,根据固定的 hash 算法来路由数据包的,其存在如下问题:
- [1] Listen Socket数量发生变化的时候,会造成握手数据包的前一个数据包路由到A listen socket,而后一个握手数据包路由到B listen socket,这样会造成client的连接请求失败。
- [2] 短时间内各个listen socket间的负载不均衡。
NAPI
关于epoll,NAPI技术可以一次收集多个请求,加入到就绪队列后再返回。
NAPI是linux新的网卡数据处理API,据说是由于找不到更好的名字,所以就叫NAPI(New API),在2.5之后引入。简单来说,NAPI是综合中断方式与轮询方式的技术。
中断的好处是响应及时,如果数据量较小,则不会占用太多的CPU事件;缺点是数据量大时,会产生过多中断,而每个中断都要消耗不少的CPU时间,从而导致效率反而不如轮询高。轮询方式与中断方式相反,它更适合处理大量数据,因为每次轮询不需要消耗过多的CPU时间;缺点是即使只接收很少数据或不接收数据时,也要占用CPU时间。
NAPI 是 Linux 上采用的一种提高网络处理效率的技术,它的核心概念就是不采用中断的方式读取数据,而代之以首先采用中断唤醒数据接收的服务程序,然后 POLL 的方法来轮询数据。
随着网络的接收速度的增加,NIC 触发的中断能做到不断减少,目前 NAPI 技术已经在网卡驱动层和网络层得到了广泛的应用,驱动层次上已经有 E1000 系列网卡,RTL8139 系列网卡,3c50X 系列等主流的网络适配器都采用了这个技术,而在网络层次上,NAPI 技术已经完全被应用到了著名的netif_rx 函数中间,并且提供了专门的 POLL 方法–process_backlog 来处理轮询的方法;根据实验数据表明采用NAPI技术可以大大改善短长度数据包接收的效率,减少中断触发的时间。
NAPI 对数据包到达的事件的处理采用轮询方法,在数据包达到的时候,NAPI 就会强制执行dev->poll方法。而和不像以前的驱动那样为了减少包到达时间的处理延迟,通常采用中断的方法来进行。
以前的网络设备驱动程序架构已经不能适用于每秒产生数千个中断的高速网络设备,并且它可能导致整个系统处于饥饿状态(译者注:饥饿状态的意思是系统忙于处理中断程序,没有时间执行其他程序)。有些网络设备具有中断合并,或者将多个数据包组合在一起来减少中断请求这种高级功能。
NAPI 存在一些比较严重的缺陷:
1. 对于上层的应用程序而言,系统不能在每个数据包接收到的时候都可以及时地去处理它,而且随着传输速度增加,累计的数据包将会耗费大量的内存,经过实验表明在 Linux 平台上这个问题会比在 FreeBSD 上要严重一些;
2. 另外一个问题是对于大的数据包处理比较困难,原因是大的数据包传送到网络层上的时候耗费的时间比短数据包长很多(即使是采用 DMA 方式)使得轮询等待时间长(因为在网络层轮询等待数据包),所以正如前面所说的那样,NAPI 技术适用于对高速率的短长度数据包的处理。
Linux中线程为什么也称为轻量级进程
线程是概念上的,Linux中线程也是一个进程,只是这些进程之间互相共享数据,也就称为轻量级进程
线程的创建
在Linux系统中,线程是通过POSIX提供的线程库创建的,它与进程中的其他线程共享数据段,但线程拥有自己的线程栈以及独立的运行序列。Linux线程的创建实在内核外进行的,有POSIX提供的线程库实现。在进程创建时,内核提供的两个系统调用分别为**_clone()和fork()最终都用不同的参数对应到do_fork()**这个内核API。
do_fork()提供很多参数选项,即CLONE_VM(共享内存空间)、CLONE_FS(共享文件系统信息)、CLONE_FILES(共享文件描述符表)、CLONE_SIGHAND(共享信号句柄表)和CLONE_PID(共享进程ID,仅对核内进程,即0号进程有效)等。
当执行fork()时,对应内核调用do_fork()时不使用上述的任何共享属性,这也导致进程拥有独立的运行环境。相反,在通过pthread_create()来创建线程时,则通过选项设置所有这些共享属性来调用__clone(),而这些参数又全部传给内核态的do_fork(),从而导致所创建的“进程”拥有共享的运行环境。因此在Linux系统中,线程通常被称为“轻量级进程”。
线程的管理
在Linux内核中,线程是以轻量级进程的形式存在的,拥有独立的进程表项;而所有的线程创建、同步、删除等操作都在核外pthread库中进行。这种模式称为基于核心轻量级进程的**”一对一”线程模型**。
轻量级进程是建立在内核线程的基础上的,内核线程运行在内核态中,线程最终的调度都落在内核线程的调度上,比如一个内核线程负责IO、一个内核线程负责内存管理等等。linux内是一对一(一个lwp对应一个内核线程)


用户线程为什么必须映射到内核线程
- 只有内核线程才是处理器分配的单位。
- 用户线程对用户不透明,但对os是透明的(看不到),os只能看到内核线程。
- 对于用户级线程来说,用户程序运行用户级线程,必须要通过映射到内核级线程后,在内核级线程上运行它。内核线程将被操作系统调度器指派到处理器内核。
具体来说:
- 用户线程是由用户在用户库的帮助下创建的线程,只对创建进程和它的运行环境可见(内核不知道这些线程的创建)。用户线程只是停留在创建进程的地址空间中,由创建进程运行和管理,没有内核的干预,也就是说,这些线程的执行出现的任何问题都不是内核的问题。
- 内核线程是由内核创建的,对它来说是可见的。一个用户进程在所提供的库的帮助下,要求内核为该进程创建一个可执行的线程,而内核则代表该进程创建该线程,并将其放在现有的可执行线程列表中。在这个过程中,线程的创建、执行和管理是由内核负责的。
- 作为内核的一部分,调度器只知道内核级的线程,因为如前所述,内核不知道用户线程的存在,因为它们是在创建进程的地址空间中创建的,因此内核对它们没有控制权。内核中的CPU调度程序只是在其拥有的线程 “列表 “中查看可供执行的线程列表,并开始调度它们。
如果没有为线程映射到内核线程:
- 内存中的每个进程都是一个 “内核线程”,这意味着该进程也在内核的线程列表中。因此,这意味着内核将用户进程映射到其中一个内核线程中去执行它。
- 一个进程所创建的所有用户线程都在指定给整个进程的同一个内核级线程上执行。每当轮到指定的进程在CPU上执行时,它的内核线程就会被安排到CPU上,从而执行该进程。
- 因为所有的线程都是由创建进程本身控制的,用户线程将被逐一映射到指定的内核线程上,从而被执行。
简而言之,用户线程需要被映射到内核线程,因为是内核将线程安排到CPU上执行,为此它必须知道它所安排的线程。对于一个简单的进程来说,内核只知道这个进程的存在,而不知道在这个进程中创建的用户线程,所以内核只会把这个进程的线程安排到CPU上,所有在这个进程中的其他用户线程如果要被执行,就必须一个一个地映射到指定给创建进程的内核线程。
内核线程有两种,一种是完成特定工作的,一种是与用户进程做映射的。
用户进程和内核线程是一体的,调度内核线程相当于调度用户进程。执行普通代码的时候在用户空间,就不需要内核线程。执行系统调用就需要进入内核态,这时就调度内核线程来完成。内核线程的堆栈就是因为有函数操作什么的要保存变量
优先级调度和完全公平调度差别
- 调度策略:传统的优先级调度算法根据进程的优先级来决定调度顺序,而完全公平调度算法采用时间片轮转的策略,平等地为每个进程分配 CPU 时间。
- 公平性:传统的优先级调度算法可能会导致低优先级进程长时间得不到调度,出现“饥饿”现象,而完全公平调度算法可以保证所有进程都能够得到公平的 CPU 时间分配,避免了饥饿现象。
- 响应时间:传统的优先级调度算法可以让高优先级进程更快地得到响应和执行,但可能会导致低优先级进程的响应时间较长;而完全公平调度算法可以保证所有进程的响应时间相对平均,但短进程的等待时间可能会增加,影响系统的响应速度。
- 预测性:传统的优先级调度算法通常需要根据应用的特点和需求来调整优先级,而完全公平调度算法不需要做出太多的调整和优化,更容易保持稳定。
进程静态优先级和动态优先级
在操作系统中,进程的优先级通常可以分为静态优先级和动态优先级两种类型。静态优先级决定时间片大小,动态优先级决定进程的调度。
静态优先级是指进程在创建时就确定的优先级,一旦确定就不会发生变化。通常情况下,静态优先级由进程的创建者指定,可以通过系统调用如 nice() 或 setpriority() 来设置。在 Linux 系统中,进程的静态优先级范围是从 -20(最高优先级)到 19(最低优先级),默认值为 0。
动态优先级则是指进程在运行时根据系统负载情况和进程运行状态等动态调整的优先级。在 Linux 系统中,动态优先级主要由 CFS 调度器进行控制,CFS 调度器使用一种称为虚拟运行时间(virtual runtime)的机制来计算进程的运行时间,并根据进程的虚拟运行时间来决定其动态优先级。当进程的虚拟运行时间越长时,其动态优先级就会越低,从而使得其他优先级更高的进程能够获得更多的 CPU 时间。
需要注意的是,静态优先级和动态优先级并不是相互独立的,而是相互影响的。在 CFS 调度器中,进程的静态优先级会被用来计算其初始的虚拟运行时间,从而影响其动态优先级的计算。因此,静态优先级越高的进程通常会获得更多的 CPU 时间,而动态优先级则可以在系统负载高峰时更加灵活地分配 CPU 时间,以保证系统的响应性能和公平性。
C++ 程序占cpu过高如何排查
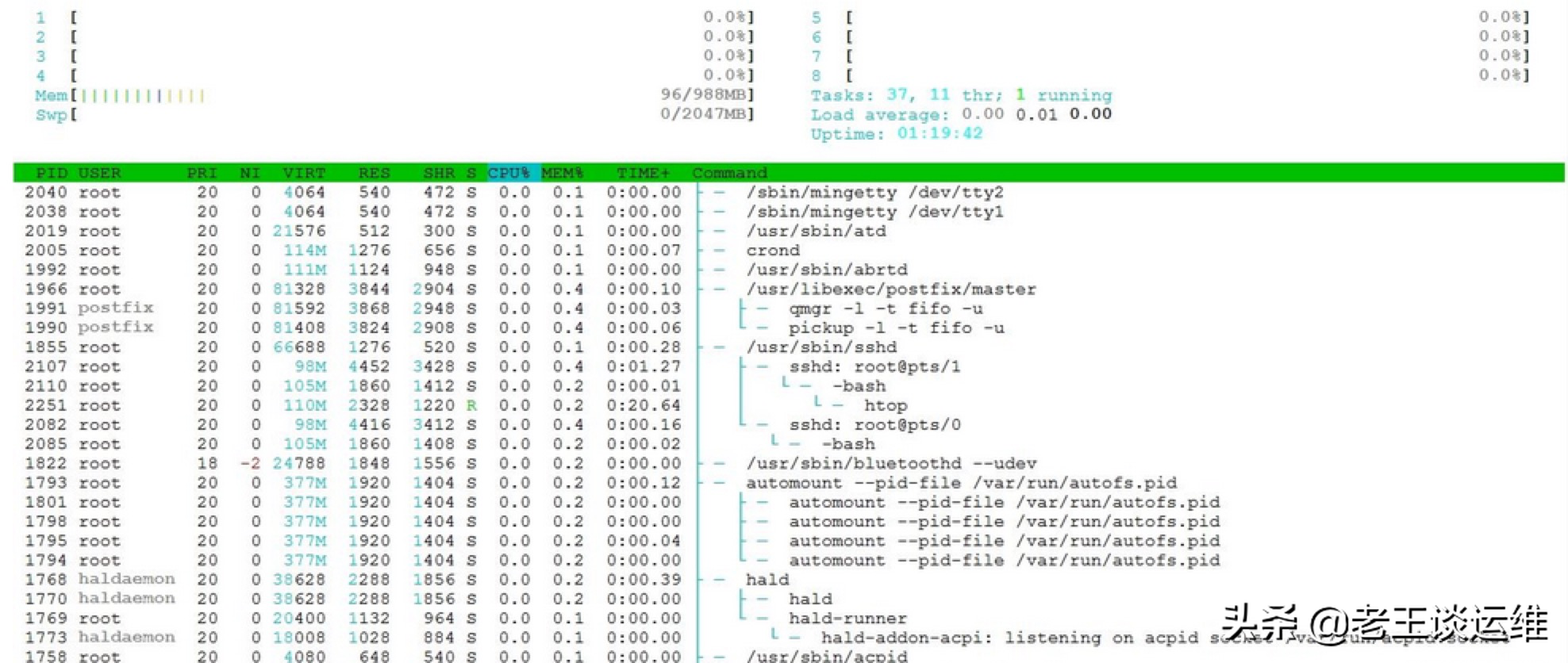
- 1.定位程序
- 监控cpu运行状,显示进程运行信息列表:
top -c - 按CPU使用率排序,键入大写的
P - 此时知道了最高的进程的PID
- 监控cpu运行状,显示进程运行信息列表:
- 2.查看进程中线程的信息
top -Hp 进程号。 同样输入大写P,top的输出会按使用cpu多少排序,获取最高的那个线程号(H是线程模式)- -c: 命令行列显示程序名以及参数
- -d: 启动时设置刷新时间间隔
- -H: 设置线程模式
- -i: 只显示活跃进程
- -n: 显示指定数量的进程
- -p: 显示指定PID的进程
- -u: 显示指定用户的进程
- 查看线程堆栈
pstack 进程号,会输出所有线程的堆栈信息- 在信息中搜索线程号,查看对应的堆栈,看看是哪一行代码的问题
linux查看内存
free命令
命令格式: free –m
- -b 以Byte为单位显示内存使用情况。
- -k 以KB为单位显示内存使用情况。
- -m 以MB为单位显示内存使用情况。
- -h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。
用途:用于检查有关系统RAM的使用情况(查看系统的可用和已用内存)
可用内存计算公式:
可用内存 =free +buffers +cached, 实际操作即:215 +11+57 =253MB;

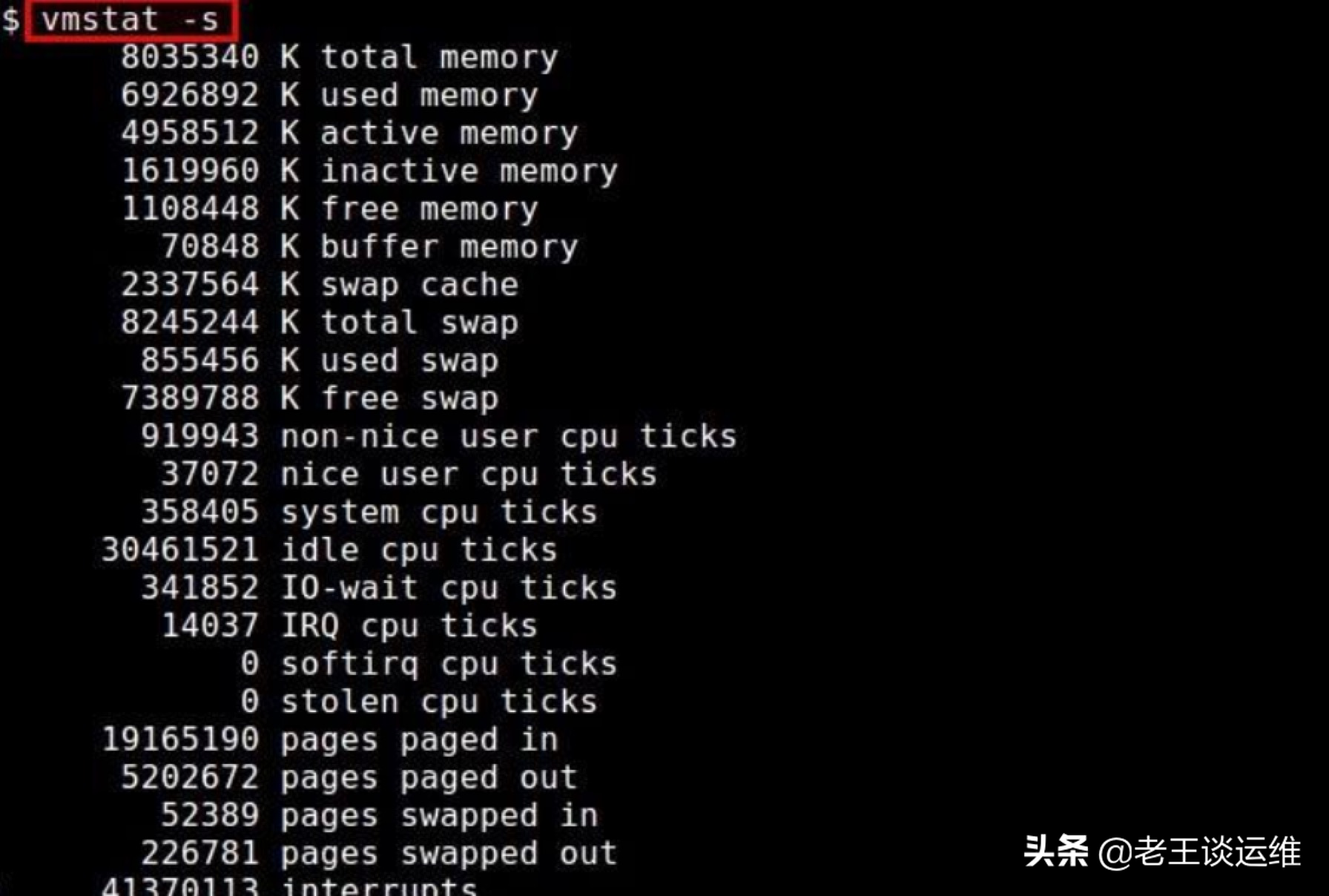
vmstat 指令
命令格式:vmstat -s(参数)
用途: 用于查看系统的内存存储信息,是一个报告虚拟内存统计信息的小工具,vmstat 命令报告包括:进程、内存、分页、阻塞 IO、中断、磁盘、CPU。
从图中我们可以看出可用内存和可用交换内存条数目,即系统中的可用内存。
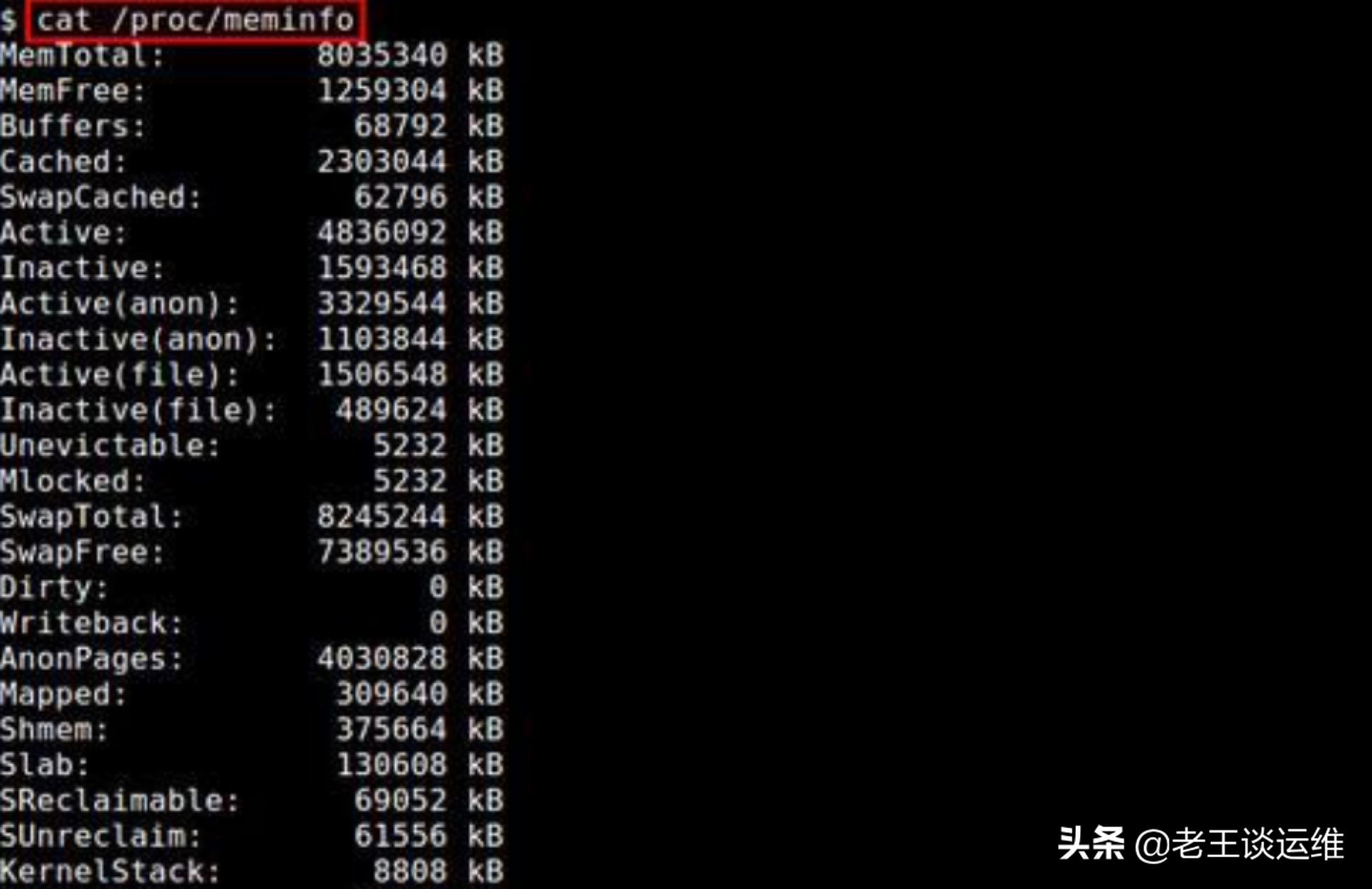
/proc/meminfo 指令
命令格式:cat /proc/meminfo
用途:用于从/proc文件系统中提取与内存相关的信息。这些文件包含有系统和内核的内部信息。
从中我们可以很清晰明了的看出内存中的各种指标情况,例如 MemFree的空闲内存和SwapFree中的交换内存。
PS:你还可以使用命令 less /proc/meminfo 直接读取该文件。通过使用 less 命令,可以在长长的输出中向上和向下滚动,找到你需要的内容哦~
top 指令
命令格式:top
用途: 用于打印系统中的CPU和内存使用情况。
小试牛刀:
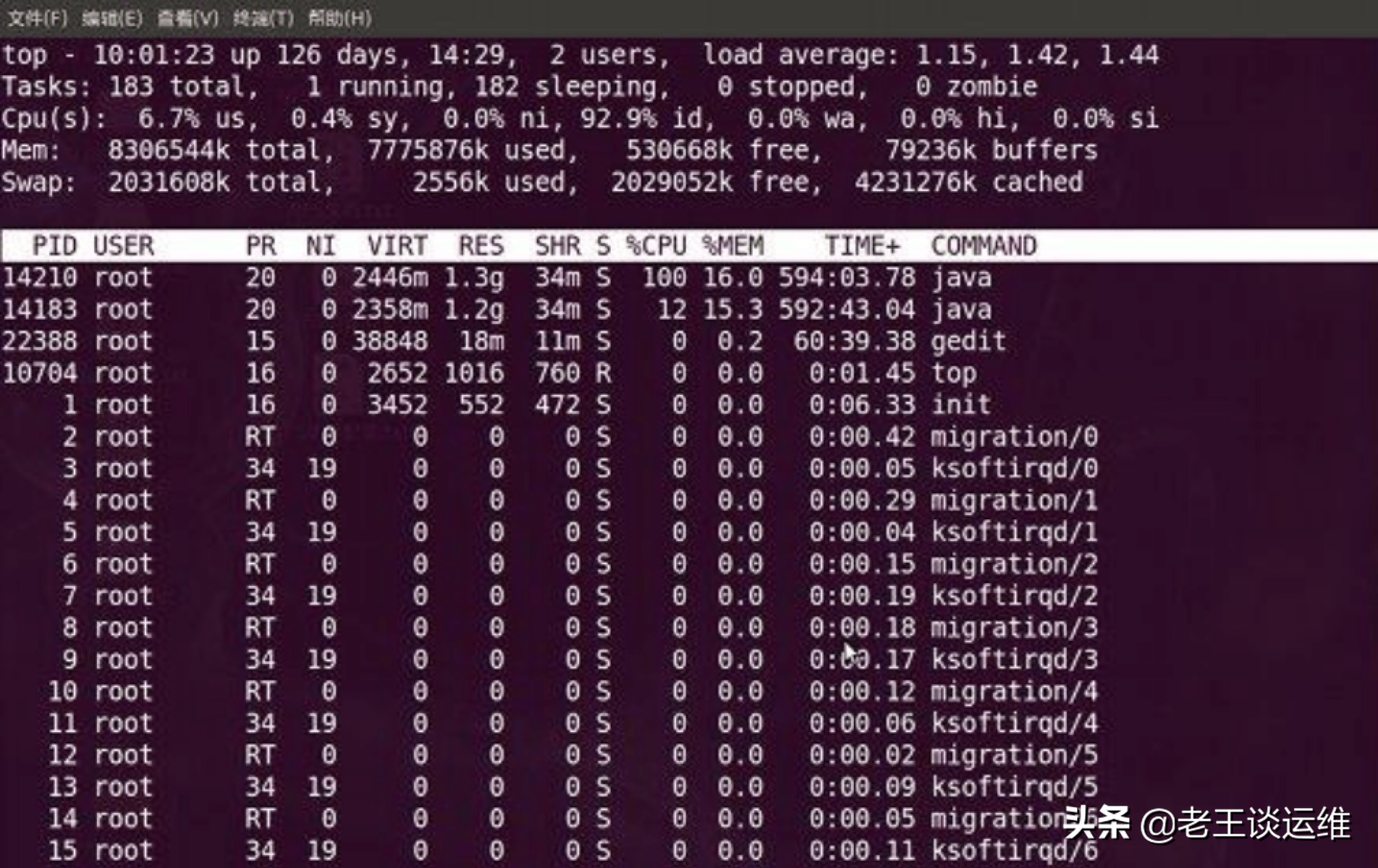
输出结果中,可以很清晰的看出已用和可用内存的资源情况。top 最好的地方之一就是发现可能已经失控的服务的进程 ID 号(PID)。有了这些 PID,你可以对有问题的任务进行故障排除(或 kill)。
PS:如果你想让 top 显示更友好的内存信息,使用命令 top -o %MEM,这会使 top 按进程所用内存对所有进程进行排序。
htop 指令
命令格式:htop
用途:详细分析CPU和内存使用情况。
程序是如何跑起来的
文件角度:ELF文件格式,装入内存
生成进程、调度,程序计数器
linux下查看端口命令
netstat命令参数:
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。
-n : 不进行DNS轮询,显示IP(可以加速操作)
即可显示当前服务器上所有端口及进程服务,于grep结合可查看某个具体端口及服务情况··
1 | netstat -ntlp``//查看当前所有tcp端口·``netstat -ntulp |grep80``//查看所有80端口使用情况·``netstat -an | grep3306``//查看所有3306端口使用情况· |
查看一台服务器上面哪些服务及端口
1 | netstat -lanp |
查看一个服务有几个端口。比如要查看mysqld
1 | ps -ef |grep mysqld |
查看某一端口的连接数量,比如3306端口
1 | netstat -pnt |grep :3306|wc |
查看某一端口的连接客户端IP 比如3306端口
1 | netstat -anp |grep3306 |
lsof -i :port,使用lsof -i :port就能看见所指定端口运行的程序,同时还有当前连接。
1 | nmap 端口扫描``netstat -nupl (UDP类型的端口)``netstat -ntpl (TCP类型的端口)``netstat -anp 显示系统端口使用情况 |
业务
Web 安全
HTTP状态
HTTP CODE 2xx
状态码:200 ok
含义:客户端请求成功
状态码:204 No Content
含义:请求处理成功,但没有资源返回。204不允许返回任何实体的主体
状态码:206 Partial Content
含义:客户发送了一个带有Range头的GET请求,服务器完成了它。使用video去播放视频,返回206,说明视频范围
HTTP CODE 3xx
状态码:301 Moved Permanently
含义:永久重定向。该状态吗表示请求的资源已被分配了新的URI,以后应按 Location 首部字段提示的 URI 重新保存。
状态码:302 Found
含义:和 301 Moved Permanently 状态码相似,但 302 状态码代表的资源不是被永久移动,只是临时性质的。
状态码:303 See Other
含义:303 状态码和 302 Found 状态码有着相同的功能,但 303 状态码明确表示客户端应当采用 GET 方法获取资源。
状态码:304 Not Modified
含义:
1、304 虽然被划分在 3XX 类别中,但是和重定向没有关系。
2、资源已找到,但未符合条件请求。
条件请求是啥:
采用 GET方法的请求报文中包含 If-Match,If-ModifiedSince,If-None-Match,If-Range,If-Unmodified-Since
中任一首部。
HTTP CODE 4xx
状态码:400 Bad Request
含义:请求报文中存在语法错误。当错误发生是,需要修改请求的内容后再次发送请求。
另外,浏览器会像200 OK一样对待该状态码。
状态码:401 Unauthorized
含义:返回含有 401 的响应必须包含一个适用于被请求资源的 WWW-Authenticate
首部用以质询(challenge)用户信息。当浏览器初次接收到 401 响应,会弹出认证用的对话窗口。
状态码:403 Forbidden
含义:该状态码表明对请求资源的访问被服务器拒绝了。服务器端没有必要给出拒绝的详细理由。
未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源 IP 地址试图访问)等列举的情况都可能是发生 403 的原因。
状态码:404 Not Found
含义:该状态吗表明服务器上无法找到请求的资源。
HTTP CODE 5xx
状态码:500 Intertnal Server Error
含义:服务器本身发生错误。也有可能是 Web应用存在的 bug 或某些临时的故障
状态码:503 Intertnal Server Error
含义:该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
web安全漏洞
1. SQL 注入
SQL 注入就是通过给 web 应用接口传入一些特殊字符,达到欺骗服务器执行恶意的 SQL 命令。
SQL 注入漏洞属于后端的范畴,但前端也可做体验上的优化。
原因
当使用外部不可信任的数据作为参数进行数据库的增、删、改、查时,如果未对外部数据进行过滤,就会产生 SQL 注入漏洞。
比如:
1 | name = "外部输入名称"; |
上面的 SQL 语句目的是通过用户输入的用户名查找用户信息,因为由于 SQL 语句是直接拼接的,也没有进行过滤,所以,当用户输入 '' or '1'='1' 时,这个语句的功能就是搜索 users 全表的记录。
1 | select * from users where name='' or '1'='1'; |
解决方案
具体的解决方案很多,但大部分都是基于一点:不信任任何外部输入。
1.预编译
1 | String sql = "select id, no from user where id=?"; |
将sql语句预先编译好,也就是SQL引擎会预先进行语法分析,产生语法树,生成执行计划,也就是说,后面你输入的参数,无论你输入的是什么,都不会影响该sql语句的 语法结构了,因为语法分析已经完成了,而语法分析主要是分析sql命令,比如 select ,from ,where ,and, or ,order by 等等。所以即使你后面输入了这些sql命令,也不会被当成sql命令来执行了,因为这些sql命令的执行, 必须先的通过语法分析,生成执行计划,既然语法分析已经完成,已经预编译过了,那么后面输入的参数,是绝对不可能作为sql命令来执行的,只会被当做字符串字面值参数。
2.类型检查,只允许某种类型的输入
1 | $uid=checkuid($uid); //检测$uid是不是数字类型,不是不继续往下运行 |
这段语句是为了保证了id是数字类型,checkid是一个自定义的函数,但是千万别直接里面写一个is_numeric就结束了,这很容易就可以用16进制或者是科学计数法去绕过的。
3.过滤特殊字符,相当于提前定义黑名单,但出现纰漏还是能绕过去。
2. XSS 攻击
XSS 攻击全称跨站脚本攻击(Cross-Site Scripting),简单的说就是攻击者通过在目标网站上注入恶意脚本并运行,获取用户的敏感信息如 Cookie、SessionID 等,影响网站与用户数据安全。
XSS 攻击更偏向前端的范畴,但后端在保存数据的时候也需要对数据进行安全过滤。
反射型的 XSS 攻击,主要是由于服务端接收到客户端的不安全输入,在客户端触发执行从而发起 Web 攻击。
具体而言,反射型 XSS 只是简单地把用户输入的数据 “反射” 给浏览器,这种攻击方式往往需要攻击者诱使用户点击一个恶意链接,或者提交一个表单,或者进入一个恶意网站时,注入脚本进入被攻击者的网站。这是一种非持久型的攻击。
比如:在某购物网站搜索物品,搜索结果会显示搜索的关键词。搜索关键词填入<script>alert('handsome boy')</script>,点击搜索。页面没有对关键词进行过滤,这段代码就会直接在页面上执行,弹出 alert。
基于存储的 XSS 攻击,是通过提交带有恶意脚本的内容存储在服务器上,当其他人看到这些内容时发起 Web 攻击。一般提交的内容都是通过一些富文本编辑器编辑的,很容易插入危险代码。
比较常见的一个场景是攻击者在社区或论坛上写下一篇包含恶意 JavaScript 代码的文章或评论,文章或评论发表后,所有访问该文章或评论的用户,都会在他们的浏览器中执行这段恶意的 JavaScript 代码。这是一种持久型的攻击。
基于 DOM 的 XSS 攻击是指通过恶意脚本修改页面的 DOM 结构,是纯粹发生在客户端的攻击。
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞,而其他两种 XSS 都属于服务端的安全漏洞。
1 | <script> |
点击 Submit 按钮后,会在当前页面插入一个链接,其地址为用户的输入内容。如果用户在输入时构造了如下内容:
1 | " onclick=alert(/xss/) |
用户提交之后,页面代码就变成了:
1 | <a href onlick="alert(/xss/)">testLink</a> |
此时,用户点击生成的链接,就会执行对应的脚本。DOM 型 XSS 攻击,实际上就是网站前端 JavaScript 代码本身不够严谨,把不可信的数据当作代码执行了。在使用 .innerHTML、.outerHTML、document.write() 时要特别小心,不要把不可信的数据作为 HTML 插到页面上
原因
当攻击者通过某种方式向浏览器页面注入了恶意代码,并且浏览器执行了这些代码。
比如:
在一个文章应用中(如微信文章),攻击者在文章编辑后台通过注入 script 标签及 js 代码,后端未加过滤就保存到数据库,前端渲染文章详情的时候也未加过滤,这就会让这段 js 代码执行,引起 XSS 攻击。
防御 XSS 的根本之道
通过前面的介绍可以得知,XSS 攻击有两大要素:
- 攻击者提交恶意代码。
- 浏览器执行恶意代码。
根本的解决方法:从输入到输出都需要过滤、转义。
对于输入来讲可以编码、转义、过滤;对于输出来讲,可以编码、转义
一些危险的标签也需要禁止,例如: <iframe>,<script>,<base>,<form>
3. CSRF 攻击
[(42条消息) CSRF攻击与防御(写得非常好)_涛歌依旧的博客-CSDN博客](https://blog.csdn.net/stpeace/article/details/53512283#:~:text=防御CSRF攻击: 目前防御 CSRF 攻击主要有三种策略:验证 HTTP Referer 字段;在请求地址中添加 token,根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。)
CSRF 攻击全称跨站请求伪造(Cross-site Request Forgery),简单的说就是攻击者盗用了你的身份,以你的名义发送恶意请求。
原因
一个典型的 CSRF 攻击有着如下的流程:
- 受害者登录
a.com,并保留了登录凭证(Cookie) - 攻击者引诱受害者访问了
b.com b.com向a.com发送了一个请求:a.com/act=xx(浏览器会默认携带a.com的 Cookie)a.com接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求a.com以受害者的名义执行了act=xx- 攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让
a.com执行了自己定义的操作
受害者 Bob 在银行有一笔存款,通过对银行的网站发送请求 http://bank.example/withdraw?account=bob&amount=1000000&for=bob2 可以使 Bob 把 1000000 的存款转到 bob2 的账号下。通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,并且该 session 的用户 Bob 已经成功登陆。
黑客 Mallory 自己在该银行也有账户,他知道上文中的 URL 可以把钱进行转帐操作。Mallory 可以自己发送一个请求给银行:http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory。但是这个请求来自 Mallory 而非 Bob,他不能通过安全认证,因此该请求不会起作用。
这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码: src=”http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory ”,并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 url 就会从 Bob 的浏览器发向银行,而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。这时,悲剧发生了,这个 url 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。等以后 Bob 发现账户钱少了,即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。而 Mallory 则可以拿到钱后逍遥法外。
解决方案
(1)验证 HTTP Referer 字段
根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站,比如需要访问 http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用户必须先登陆 bank.example,然后通过点击页面上的按钮来触发转账事件。这时,该转帐请求的 Referer 值就会是转账按钮所在的页面的 URL,通常是以 bank.example 域名开头的地址。而如果黑客要对银行网站实施 CSRF 攻击,他只能在他自己的网站构造请求,当用户通过黑客的网站发送请求到银行时,该请求的 Referer 是指向黑客自己的网站。因此,要防御 CSRF 攻击,银行网站只需要对于每一个转账请求验证其 Referer 值,如果是以 bank.example 开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。
这种方法的显而易见的好处就是简单易行,网站的普通开发人员不需要操心 CSRF 的漏洞,只需要在最后给所有安全敏感的请求统一增加一个拦截器来检查 Referer 的值就可以。特别是对于当前现有的系统,不需要改变当前系统的任何已有代码和逻辑,没有风险,非常便捷。
然而,这种方法并非万无一失。Referer 的值是由浏览器提供的,虽然 HTTP 协议上有明确的要求,但是每个浏览器对于 Referer 的具体实现可能有差别,并不能保证浏览器自身没有安全漏洞。使用验证 Referer 值的方法,就是把安全性都依赖于第三方(即浏览器)来保障,从理论上来讲,这样并不安全。事实上,对于某些浏览器,比如 IE6 或 FF2,目前已经有一些方法可以篡改 Referer 值。如果 bank.example 网站支持 IE6 浏览器,黑客完全可以把用户浏览器的 Referer 值设为以 bank.example 域名开头的地址,这样就可以通过验证,从而进行 CSRF 攻击。
即便是使用最新的浏览器,黑客无法篡改 Referer 值,这种方法仍然有问题。因为 Referer 值会记录下用户的访问来源,有些用户认为这样会侵犯到他们自己的隐私权,特别是有些组织担心 Referer 值会把组织内网中的某些信息泄露到外网中。因此,用户自己可以设置浏览器使其在发送请求时不再提供 Referer。当他们正常访问银行网站时,网站会因为请求没有 Referer 值而认为是 CSRF 攻击,拒绝合法用户的访问。
(2)在请求地址中添加 token 并验证
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 <input type="hidden" name="csrftoken" value="tokenvalue"/>,这样就把 token 以参数的形式加入请求了。但是,在一个网站中,可以接受请求的地方非常多,要对于每一个请求都加上 token 是很麻烦的,并且很容易漏掉,通常使用的方法就是在每次页面加载时,使用 javascript 遍历整个 dom 树,对于 dom 中所有的 a 和 form 标签后加入 token。这样可以解决大部分的请求,但是对于在页面加载之后动态生成的 html 代码,这种方法就没有作用,还需要程序员在编码时手动添加 token。
该方法还有一个缺点是难以保证 token 本身的安全。特别是在一些论坛之类支持用户自己发表内容的网站,黑客可以在上面发布自己个人网站的地址。由于系统也会在这个地址后面加上 token,黑客可以在自己的网站上得到这个 token,并马上就可以发动 CSRF 攻击。为了避免这一点,系统可以在添加 token 的时候增加一个判断,如果这个链接是链到自己本站的,就在后面添加 token,如果是通向外网则不加。不过,即使这个 csrftoken 不以参数的形式附加在请求之中,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。
(3) 验证码,验证码提供一个操作确认,那用户就知道这个网站背后在搞什么鬼。
4.SSRF 攻击
服务端请求伪造(Server-Side Request Forgery),指的是攻击者在未能取得服务器所有权限时,利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。SSRF攻击通常针对外部网络无法直接访问的内部系统。
很多web应用都提供了从其他的服务器上获取数据的功能。使用指定的URL,web应用便可以获取图片,下载文件,读取文件内容等。SSRF的实质是利用存在缺陷的web应用作为代理攻击远程和本地的服务器。一般情况下, SSRF攻击的目标是外网无法访问的内部系统,黑客可以利用SSRF漏洞获取内部系统的一些信息(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)。SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。
攻击者想要访问主机B上的服务,但是由于存在防火墙或者主机B是属于内网主机等原因导致攻击者无法直接访问主机B。而服务器A存在SSRF漏洞,这时攻击者可以借助服务器A来发起SSRF攻击,通过服务器A向主机B发起请求,从而获取主机B的一些信息。
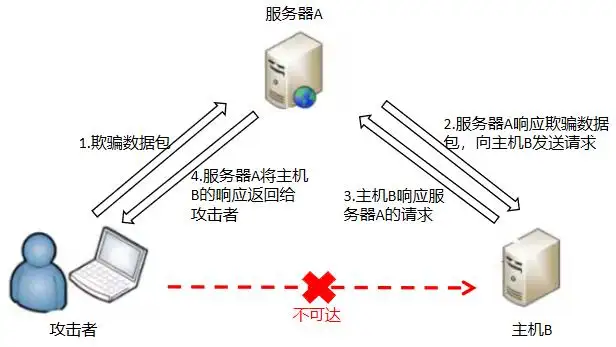
案例:
1.探测内部主机端口信息
提交参数值为url:port,根据返回错误不同,可对内网状态进行探测如端口开放状态等。访问一个可以访问的IP:PORT,如http://127.0.0.1:7001。根据返回错误不同,可对内网状态进行探测如端口开放状态等。
当我们访问一个不存在的端口时,比如 http://127.0.0.1:7000,将会返回:could not connect over HTTP to server
当我们访问存在的端口时,比如 http://127.0.0.1:7001。可访问的端口将会得到错误,一般是返回status code
2.获取内网主机敏感信息
在服务器上有一个ssrf.php的页面,该页面的功能是获取URL参数,然后将URL的内容显示到网页页面上。我们访问该链接:http://127.0.0.1/ssrf.php?url=http://127.0.0.1/test.php ,它会将test.php页面显示
可以将URL参数换成内网的地址,则会泄露服务器内网的信息。将URL换成file://的形式,就可以读取本地文件。

如何防御SSRF
1、限制ip如127.0.0.1
2、禁用除http和https外的协议,如:file://、gopher://、dict://等。
3、限制请求的端口为http常用的端口,如 80、443、8080。
4、统一错误信息,避免用户可以根据错误信息来判断远程服务器的端口状态。
5、对请求地址设置白名单或者限制内网IP,以防止对内网进行攻击。
5. DDoS 攻击
DoS 攻击全称拒绝服务(Denial of Service),简单的说就是让一个公开网站无法访问,而 DDoS 攻击(分布式拒绝服务 Distributed Denial of Service)是 DoS 的升级版。
这个就完全属于后端的范畴了。
原因
攻击者不断地提出服务请求,让合法用户的请求无法及时处理,这就是 DoS 攻击。
攻击者使用多台计算机或者计算机集群进行 DoS 攻击,就是 DDoS 攻击。
解决方案
防止 DDoS 攻击的基本思路是限流,限制单个用户的流量(包括 IP 等)。
高并发
好文:我没有高并发项目经验,但是面试的时候经常被问到高并发、性能调优方面的问题,有什么办法可以解决吗? - 知乎 (zhihu.com)
通用的设计方法
通用的设计方法主要是从「纵向」和「横向」两个维度出发,俗称高并发处理的两板斧:纵向扩展)和横向扩展。
纵向扩展(scale-up)
它的目标是提升单机的处理能力,方案又包括:
1、提升单机的硬件性能:通过增加内存、 CPU核数、存储容量、或者将磁盘 升级成SSD 等堆硬 件 的 方 式 来 提升 。
2、提升单机的软件性能:使用缓存减少IO次数,使用并发或者异步的方式增加吞吐量。
横向扩展(scale-out)
因为单机性能总会存在极限,所以最终还需要引入横向扩展,通过集群部署以进一步提高并发处理能力,又包括以下2个方向:
1、做好分层架构:这是横向扩展的前提,因为高并发系统往往业务复杂,通过分层处理可以简化复杂问题,更容易做到横向扩展。
上面这种图是互联网最常见的分层架构,当然真实的高并发系统架构会在此基础上进一步完善。比如会做动静分离并引入CDN,反向代理层可以是LVS+Nginx,Web层可以是统一的API网关,业务服务层可进一步按垂直业务做微服务化,存储层可以是各种异构数据库。
2、各层进行水平扩展:无状态水平扩容,有状态做分片路由。业务集群通常能设计成无状态的,而数据库和缓存往往是有状态的,因此需要设计分区键做好存储分片,当然也可以通过主从同步、读写分离)的方案提升读性能。
具体的实践方案
高性能的实践方案
集群、并行计算(多线程、池化)、缓存(多级、预热)减少IO、异步化
1、集群部署,通过负载均衡减轻单机压力。
2、多级缓存,包括静态数据使用CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点key、缓存穿透、缓存并发、数据一致性等问题的处理。
3、分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。
4、考虑NoSQL数据库的使用,比如HBase、TiDB等,但是团队必须熟悉这些组件,且有较强的运维能力。
5、异步化,将次要流程通过多线程、MQ、甚至延时任务进行异步处理。
6、限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx接入层的限流、服务端的限流。
7、对流量进行 削峰填谷 ,通过 MQ承接流量。
8、并发处理,通过多线程将串行逻辑并行化。
9、预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
10、 缓存预热 ,通过异步 任务 提前 预热数据到本地缓存或者分布式缓存中。
11、减少IO次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式干掉RPC调用。
12、减少IO时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存key的大小、压缩缓存value等。
13、程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For循环的计算逻辑优化,或者采用更高效的算法。
14、各种池化技术的使用和池大小的设置,包括HTTP请求池、线程池(考虑CPU密集型还是IO密集型设置核心参数)、数据库和Redis连接池等。
15、JVM优化,包括新生代和老年代的大小、GC算法的选择等,尽可能减少GC频率和耗时。
16、锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
上述方案无外乎从计算和 IO 两个维度考虑所有可能的优化点,需要有配套的监控系统实时了解当前的性能表现,并支撑你进行性能瓶颈分析,然后再遵循二八原则,抓主要矛盾进行优化。
高可用的实践方案
1、对等节点的故障转移,Nginx和服务治理框架均支持一个节点失败后访问另一个节点。
2、非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL的主从切换等)。
3、接口层面的超时设置、重试策略和幂等设计。
4、降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
5、限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。
6、MQ场景的消息可靠性保证,包括producer端的重试机制、broker侧的持久化、consumer端的ack机制)等。
7、灰度发布,能支持按机器维度进行小流量部署,观察系统日志)和业务指标,等运行平稳后再推全量。
8、监控报警:全方位的监控体系,包括最基础的CPU、内存、磁盘、网络的监控,以及Web服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
9、灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题。
高可用的方案主要从冗余、取舍、系统运维3个方向考虑,同时需要有配套的值班机制和故障处理流程,当出现线上问题时,可及时跟进处理。
高扩展的实践方案
1、合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层(但是需要评估性能,会存在网络多一跳的情况)。
2、存储层的拆分:按照业务维度做垂直拆分、按照数据特征维度进一步做水平拆分(分库分表)。
3、业务层的拆分:最常见的是按照业务维度拆(比如电商场景的商品服务、订单服务等),也可以按照核心接口和非核心接口拆,还可以按照请求源拆(比如To C和To B,APP和H5 )。
高并发确实是一个复杂且系统性的问题,如果业务场景不同,高并发的落地方案也会存在差异,但是总体的设计思路和可借鉴的方案基本类似。
高并发设计同样要秉承架构设计的3个原则:简单、合适和演进。” 过早的优化是万恶之源 “,不能脱离业务的实际情况,更不要过度设计,合适的方案就是最完美的。
- 多进程:指在同一个时间里,同一个计算机系统中允许两个或两个以上的进程处于运行状态。多进程可以提高系统的并发能力,但也会消耗更多的资源。
- 多线程:指在一段完整的代码中,利用多个独立运行的程序片段(线程)来完成多项任务。多线程可以提高资源使用效率和系统性能,但也会带来同步和安全问题。
- 异步IO:指操作系统在接收到IO请求后,不需要等待IO操作完成就返回给用户程序,而是在IO操作完成后再通知用户程序。异步IO可以避免用户程序阻塞等待IO结果,提高响应速度和吞吐量。
- 缓存:指将数据或计算结果存储在内存或其他快速访问的介质中,以减少重复读取或计算的开销。缓存可以显著提高系统性能和用户体验,但也需要考虑缓存失效、更新、一致性等问题。
- 负载均衡:指将请求或任务分配到多个服务器或节点上,以实现负载平衡、故障转移、扩展性等目标。负载均衡可以提高系统可用性和扩展性,但也需要考虑负载均衡算法、策略、状态等问题。
- 集群:指将多台服务器或节点组织成一个逻辑单元,以实现高可用、高性能、高扩展等目标。集群可以提高系统容错能力和并发能力,但也需要考虑集群管理、协调、通信等问题。
- 无状态:指服务不保存任何客户端请求相关的数据或状态信息,而是根据每次请求携带的全部信息进行处理。无状态可以简化服务逻辑和部署方式,提高服务可扩展性和可维护性。
- 微服务:指将一个大型复杂的应用拆分成若干个小型独立的服务,每个服务负责一个特定功能,并通过轻量级协议进行通信。微服务可以提高应用模块化、灵活性、可测试性等优点,但也需要考虑服务划分、治理、监控等问题。
- 消息队列:指使用先进先出(FIFO)原则对消息进行排队处理,并允许多个生产者发送消息给多个消费者接收消息的机制。消息队列可以实现异步处理、解耦合、流量削峰等功能,但也需要考虑消息可靠性、顺序性、延迟性等问题。
负载均衡
负载均衡器:DNS、硬件、LVS、Nginx该如何搭配? - 知乎 (zhihu.com)
DNS负载均衡的原理是利用DNS系统本身的分布式特性,将同一个域名解析为不同的IP地址,从而将用户请求分发到不同的服务器上,实现负载均衡。
DNS负载均衡的优点是实现简单,成本低,无需额外的设备或软件。DNS负载均衡的缺点是服务器故障切换延迟大,流量调度不均衡,流量分配策略太简单。
软件负载均衡的原理是在普通的服务器上运行负载均衡软件,实现负载均衡功能。常见的软件负载均衡有Nginx、HAproxy、LVS等。
软件负载均衡的优点是可扩展性强,灵活性高,成本低。软件负载均衡的缺点是性能不如硬件负载均衡,对服务器资源消耗较大,配置和管理相对复杂。
nginx和lvs是两种常用的软件负载均衡,它们的实现原理有以下区别:
- nginx是基于应用层的负载均衡,它通过代理模式,将用户请求转发到后端服务器,并将响应结果返回给用户。lvs是基于网络层的负载均衡,它通过修改数据包的目标地址,将用户请求直接发送到后端服务器,并让后端服务器直接返回响应结果给用户。
- nginx支持多种负载均衡算法,如轮询、加权轮询、最少连接、ip_hash等。lvs支持三种负载均衡模式,如NAT、DR、TUN等。
- nginx可以对请求和响应进行处理,如缓存、压缩、重写等。 lvs只对数据包进行转发,不对内容进行处理。
- nginx可以检测后端服务器的健康状态,并在故障时自动切换。lvs需要配合keepalived或其他工具来实现健康检查和故障切换。
- nginx消耗较多的服务器资源,性能受限于代理模式和IO操作。lvs消耗较少的服务器资源,性能较高且稳定。
消息队列
深入消息队列MQ,看这篇就够了! - 知乎 (zhihu.com)
base理论适用场景
分布式之 BASE理论 - 码农教程 (manongjc.com)
base理论的详细解释如下:
- 基本可用(Basically Available):基本可用是指分布式系统在出现故障时,允许损失部分可用性,即保证核心功能可用。例如,eBay在出现网络分区时,可以关闭部分非核心功能,如评论、推荐等,保证用户可以正常浏览和购买商品。
- 软状态(Soft State):软状态是指分布式系统中的数据存在中间状态,并且该状态不会影响系统整体可用性。例如,微博中的用户关注关系,在缓存和数据库之间可能存在不一致的情况,但这并不影响用户查看自己或者其他人的微博。
- 最终一致性(Eventually Consistent):最终一致性是指分布式系统中的数据在经过一定时间或者一定操作后,最终能够达到一致的状态。例如,淘宝中的订单状态,在用户付款后可能需要经过多个步骤才能更新为已付款,但最终会达到与支付宝一致的状态。
场景:
- eBay:eBay使用了多个数据库来存储不同类型的数据,例如商品信息、用户信息、交易信息等。eBay允许数据在不同数据库之间存在不一致的情况,例如用户在一个数据库中修改了地址,但在另一个数据库中还没有更新。这就是基本可用的体现,即eBay保证了用户可以正常浏览和购买商品,但不保证所有的数据都是最新的。eBay通过异步消息和定期同步的方式来保证数据最终一致,即经过一段时间后,所有的数据库都会收到用户修改地址的消息,并更新相应的数据。这就是软状态和最终一致性的体现,即eBay允许数据存在中间状态,并且该状态不会影响系统整体可用性。
- 微博:微博使用了分布式缓存和数据库来存储用户的微博和关注关系。微博允许用户在缓存中看到自己发表的微博,但其他用户可能需要等待一段时间才能看到。这就是基本可用的体现,即微博保证了用户可以正常发表和查看自己或者其他人的微博,但不保证所有的用户都能实时看到最新的微博。微博通过缓存失效和后台同步的方式来保证数据最终一致,即经过一段时间后,所有的缓存都会失效,并从数据库中获取最新的数据。这就是软状态和最终一致性的体现,即微博允许数据存在中间状态,并且该状态不会影响系统整体可用性。
- 淘宝:淘宝使用了分布式事务服务来处理订单、支付、库存等业务。淘宝允许订单在不同状态之间存在短暂的不一致,例如用户付款后,订单状态可能还没有及时更新。这就是基本可用的体现,即淘宝保证了用户可以正常下单和付款,但不保证所有的订单都能实时反映支付情况。淘宝通过补偿机制和人工干预的方式来保证数据最终一致,即经过一定操作或者时间后,所有的订单都会达到与支付宝一致
缓存穿透、击穿、雪崩
缓存穿透
如果出现以下这两种特殊情况,比如:
- 用户请求的id在缓存中不存在。
- 恶意用户伪造不存在的id发起请求。
这样的用户请求导致的结果是:每次从缓存中都查不到数据,而需要查询数据库,同时数据库中也没有查到该数据,也没法放入缓存。也就是说,每次这个用户请求过来的时候,都要查询一次数据库。
很显然,缓存根本没起作用,好像被穿透了一样,每次都会去访问数据库。
解决手段:
- 校验:可以对用户id做检验。比如合法id是15xxxxxx,以15开头的。如果用户传入了16开头的id,比如:16232323,则参数校验失败,直接把相关请求拦截掉。这样可以过滤掉一部分恶意伪造的用户id。
- 把空对象缓存起来。当第一次从数据库中查询出来的结果为空时,我们就将这个空对象加载到缓存,并设置合理的过期时间,这样,就能够在一定程度上保障后端数据库的安全。但是缓存空对象要占用缓存空间,这种空对象太多了性能就不高。
- 布隆过滤器,布隆过滤器可以针对大数据量的、有规律的键值进行处理。一条记录是不是存在,本质上是一个 Bool 值,只需要使用 1bit 就可以存储。我们可以使用布隆过滤器将这种表示是、否等操作,压缩到一个数据结构中。
布隆过滤器第一次初始化的时候,会把数据库中所有已存在的key,经过一些列的hash算法(比如:三次hash算法)计算,每个key都会计算出多个位置,然后把这些位置上的元素值设置成1。

之后,有用户key请求过来的时候,再用相同的hash算法计算位置。
- 如果多个位置中的元素值都是1,则说明该key在数据库中已存在。这时允许继续往后面操作。
- 如果有1个以上的位置上的元素值是0,则说明该key在数据库中不存在。这时可以拒绝该请求,而直接返回。
- 存在误判的情况。 因为是哈希,有冲突。
- 存在数据更新问题。如果增加了一个用户,但是同步布隆过滤器的过程中网络异常了,同步失败,那么接下来用户的请求就会被拦截。
所以布隆过滤器也要看业务需求。
缓存击穿
我们在访问热点数据时,比如我们在某个商城购买某个热门商品,为了保证访问速度,通常情况下,商城系统会把商品信息放到缓存中。但如果某个时刻,该商品到了过期时间失效了。此时,如果有大量的用户请求同一个商品,但该商品在缓存中失效了,一下子这些用户请求都直接怼到数据库,可能会造成瞬间数据库压力过大,而直接挂掉。

解决办法:
- 对于比较热点的数据,我们可以在缓存中设置这些数据永不过期(热点过去后再手动释放);
- 自动续期:本质上也是保证缓存不失效。可以用job给指定key自动续期。比如说,我们有个分类功能,设置的缓存过期时间是30分钟。但有个job每隔20分钟执行一次,自动更新缓存,重新设置过期时间为30分钟。
- 使用分布式锁,保证对于每个 Key 同时只有一个线程去查询后端的服务,某个线程在查询后端服务的同时,其他线程没有获得分布式锁的权限,需要进行等待。不过在高并发场景下,这种解决方案对于分布式锁的访问压力比较大。
缓存雪崩
缓存雪崩是缓存击穿的升级版,缓存击穿说的是某一个热门key失效了,而缓存雪崩说的是有多个热门key同时失效。
缓存雪崩目前有两种:
- 有大量的热门缓存,同时失效。会导致大量的请求,访问数据库。而数据库很有可能因为扛不住压力,而直接挂掉。
- 缓存服务器down机了,可能是机器硬件问题,或者机房网络问题。总之,造成了整个缓存的不可用。
归根结底都是有大量的请求,透过缓存,而直接访问数据库了。

解决办法:
高可用:针对缓存服务器down机的情况,在前期做系统设计时,可以做一些高可用架构。比如可以用缓存集群等,避免出现单节点故障导致整个服务不可用的情况。
过期时间加上随机数:可以在设置的过期时间基础上,再加个1
60秒的随机数。实际过期时间 = 过期时间 + 160秒的随机数这样即使在高并发的情况下,多个请求同时设置过期时间,由于有随机数的存在,也不会出现太多相同的过期key。服务降级:我们需要配置一些默认的兜底数据。程序中有个全局开关,比如有10个请求在最近一分钟内,从redis中获取数据失败,则全局开关打开。后面的新请求,就直接从配置中心中获取默认的数据。

微服务雪崩
【原创】谈谈服务雪崩、降级与熔断 - 孤独烟 - 博客园 (cnblogs.com)
假设存在如下调用链
而此时,Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。
此时,如果Service C因为抗不住请求,变得不可用。那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。紧接着,Service A也会不可用,这一过程如下图所示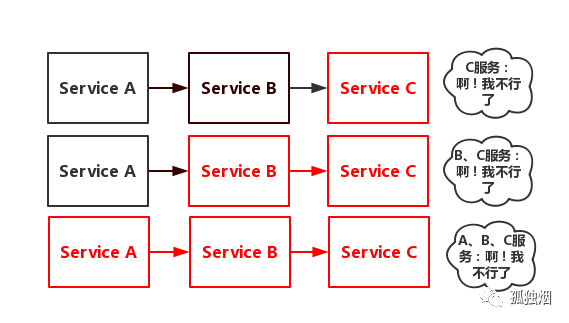
如上图所示,一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩。
服务熔断
服务熔断:当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
服务熔断重点在“断”,切断对下游服务的调⽤,直接返回错误信息或其他信息。
服务降级
这里有两种场景:
- 当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
- 当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
其实乍看之下,很多人还是不懂熔断和降级的区别!
其实应该要这么理解:
- 服务降级有很多种降级方式!如开关降级、限流降级、熔断降级!
- 服务熔断属于降级方式的一种!
从实现上来说,熔断和降级必定是一起出现。因为当发生下游服务不可用的情况,这个时候为了对最终用户负责,就需要进入上游的降级逻辑了。因此,将熔断降级视为降级方式的一种,也是可以说的通的。
服务降级大多是属于一种业务级别的处理。这里要讲的是另一种降级方式,也就是开关降级。这也是我们生产上常用的另一种降级方式。
做法很简单,做个开关,然后将开关放配置中心。在配置中心更改开关,决定哪些服务进行降级。那么,在应用程序中部下开关的这个过程,业内也有一个名词,称为埋点!
那接下来最关键的一个问题,哪些业务需要埋点?
(1)简化执行流程:自己梳理出核心业务流程和非核心业务流程。然后在非核心业务流程上加上开关,一旦发现系统扛不住,关掉开关,结束这些次要流程。
(2)关闭次要功能:一个微服务下肯定有很多功能,那自己区分出主要功能和次要功能。然后次要功能加上开关,需要降级的时候,把次要功能关了吧!
(3)降低一致性:假设业务上发现执行流程没法简化了,也没啥次要功能可以关了,那只能降低一致性了,即将核心业务流程的同步改异步,将强一致性改最终一致性。
服务限流
限流是指上游服务对本服务请求 QPS 超过阙值时,通过一定的策略(如延迟处理、拒绝处理)对上游服务的请求量进行限制,以保证本服务不被压垮,从而持续提供稳定服务。常见的限流算法有滑动窗口、令牌桶、漏桶等。
1.计算器方式(滑动计数器):定义一个原子类,针对于某一个服务实现次数记录,一旦达到阈值之后,这时候可以直接走服务降级(返回一个友好提示给客户端)。
举个例子:限制每60秒内只能接受客户端10个请求,如果超过10个请求则直接拒绝访问服务。固定速率 10R/M。
滑动窗口计数器算法原理:创建6个独立的格子,每个格子都有自己独立的计数器。每个格子独立计数10秒。
2.令牌桶算法(Token):令牌桶分为2个动作,动作1(固定速率往桶中存入令牌)、动作2(客户端如果想访问请求,先从桶中获取token)。
- 漏桶算法
以固定速率从桶中流出水滴,以任意速率往桶中放入水滴,桶容量大小是不会发生改变的。
流入:以任意速率往桶中放入水滴。
流出:以固定速率从桶中流出水滴。
水滴:是唯一不重复的标识。
因为桶中的容量是固定的,如果流入水滴的速率>流出的水滴速率,桶中的水滴可能会溢出。那么溢出的水滴请求都是拒绝访问的,或者直接调用服务降级方法。前提是同一时刻。
限流的目的:为了保护服务,避免服务宕机。
| 措施 | 产生原因 | 针对服务 |
|---|---|---|
| 熔断 | 下游服务不可用 | 下游服务 |
| 降级 | 自身服务的处理能力不够 | 自身服务 |
| 限流 | 上游服务请求增多 | 上游服务 |
用户密码应该如何存储
用户密码到底要怎么加密存储? - 知乎 (zhihu.com)
用户密码保存到数据库时,常见的加密方式有哪些,我们该采用什么方式来保护用户的密码呢?以下几种方式是常见的密码保存方式:
1、直接明文保存,比如用户设置的密码是“123456”,直接将“123456”保存在数据库中,这种是最简单的保存方式,也是最不安全的方式。但实际上不少互联网公司,都可能采取的是这种方式。
2、使用对称加密算法来保存,比如3DES、AES等算法,使用这种方式加密是可以通过解密来还原出原始密码的,当然前提条件是需要获取到密钥。不过既然大量的用户信息已经泄露了,密钥很可能也会泄露,当然可以将一般数据和密钥分开存储、分开管理,但要完全保护好密钥也是一件非常复杂的事情,所以这种方式并不是很好的方式。

3、使用MD5、SHA1等单向HASH算法保护密码,使用这些算法后,无法通过计算还原出原始密码,而且实现比较简单,因此很多互联网公司都采用这种方式保存用户密码,曾经这种方式也是比较安全的方式,但随着彩虹表技术的兴起,可以建立彩虹表进行查表破解,目前这种方式已经很不安全了。
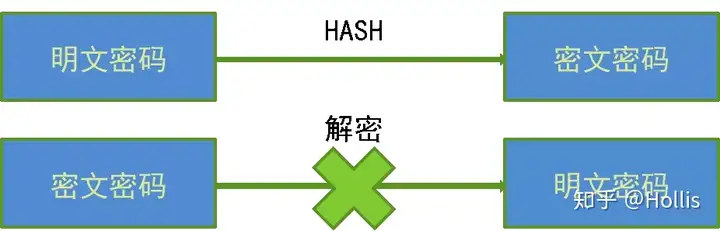
彩虹表就是把简单的数字密码组合(和各种常见密码)的哈希先尽可能的计算出来,这些明文和哈希结果的对应关系就是一张彩虹表。由于大家喜欢使用简单好记的密码,所以试着计算出一个常用范围内的所有字母组合的哈希的彩虹表,可以破解绝大多数人的密码。当彩虹表足够大时,这种存储方式实际上与明文无异。
4、特殊的单向HASH算法,由于单向HASH算法在保护密码方面不再安全,于是有些公司在单向HASH算法基础上进行了加盐。
加盐哈希是目前业界最常见的做法。
加盐哈希的步骤如下:
- 用户注册时,给他随机生成一段字符串,这段字符串就是盐(Salt)
- 把用户注册输入的密码和盐拼接在一起,叫做加盐密码
- 对加盐密码进行哈希,并把结果和盐都储存起来
在登陆时,先取出盐,再同样进行拼接、计算哈希,就能判断密码的合法性。
加盐哈希的做法,既保证了储存数据的不可逆,又防止了上一章的彩虹表攻击方式。这种方式下,黑客拿到数据库后,如果再要用遍历所有常用的密码组合的方式做彩虹表,那他需要对所有常用密码+盐值进行哈希运算。而每个用户的盐值都不相同,之前彩虹表的「一次运算无数次使用」变成了「一次运算一次使用」。这样的成本是难以接受的,由于攻击成本远高于收益,系统达到相对安全,所以这是一个比较安全的做法。
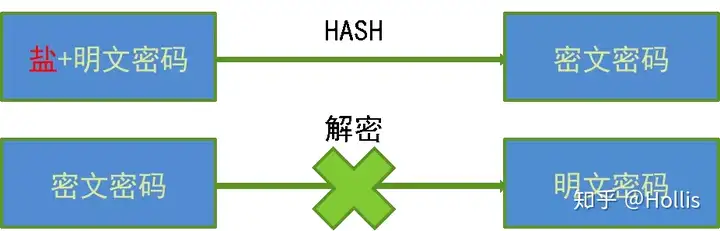
5、PBKDF2算法,该算法原理大致相当于在HASH算法基础上增加随机盐,并进行多次HASH运算,随机盐使得彩虹表的建表难度大幅增加,而多次HASH也使得建表和破解的难度都大幅增加。使用PBKDF2算法时,HASH算法一般选用sha1或者sha256,随机盐的长度一般不能少于8字节,HASH次数至少也要1000次,这样安全性才足够高。
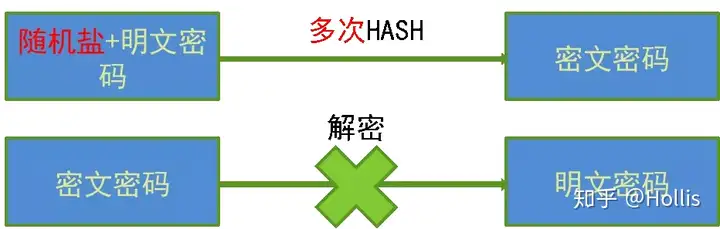
一次密码验证过程进行1000次HASH运算,对服务器来说可能只需要1ms,但对于破解者来说计算成本增加了1000倍,而至少8字节随机盐,更是把建表难度提升了N个数量级,使得大批量的破解密码几乎不可行,该算法也是美国国家标准与技术研究院推荐使用的算法。
6、bcrypt、scrypt等算法,这两种算法也可以有效抵御彩虹表,使用这两种算法时也需要指定相应的参数,使破解难度增加。
下表对比了各个算法的特性:
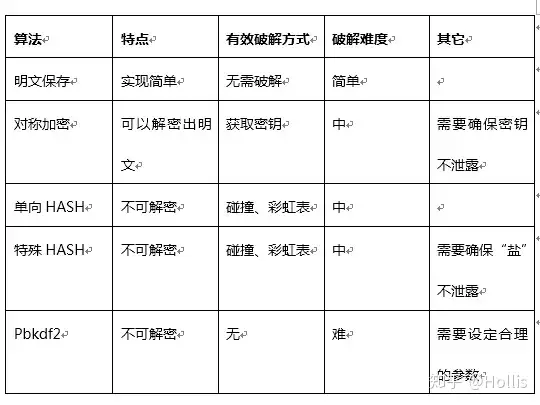
软件工程
类图关系
在UML类图中表示具体类
具体类在类图中用矩形框表示,矩形框分为三层:第一层是类名字。第二层是类的成员变量;第三层是类的方法。成员变量以及方法前的访问修饰符用符号来表示:
- “+”表示
public; - “-”表示
private; - “#”表示
protected; - 不带符号表示
default。
在UML类图中表示抽象类
抽象类在UML类图中同样用矩形框表示,但是抽象类的类名以及抽象方法的名字都用斜体字表示,如图所示。
在UML类图中表示接口
接口在类图中也是用矩形框表示,但是与类的表示法不同的是,接口在类图中的第一层顶端用构造型 <
在类图中表示关系
类和类、类和接口、接口和接口之间存在一定关系,UML类图中一般会有连线指明它们之间的关系。关系共有六种类型,分别是实现关系、泛化关系、关联关系、依赖关系、聚合关系、组合关系,如图所示。
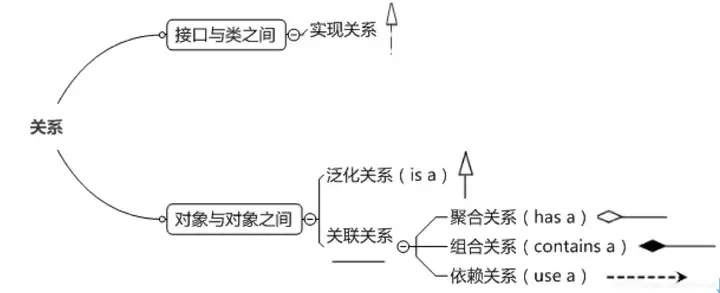
实现关系
实现关系是指接口及其实现类之间的关系。在UML类图中,实现关系用空心三角和虚线组成的箭头来表示,从实现类指向接口。
泛化关系
泛化关系(Generalization)是指对象与对象之间的继承关系。如果对象A和对象B之间的“is a”关系成立,那么二者之间就存在继承关系,对象B是父对象,对象A是子对象。例如,一个年薪制员工“is a”员工,很显然年薪制员工Salary对象和员工Employee对象之间存在继承关系,Employee对象是父对象,Salary对象是子对象。
在UML类图中,泛化关系用空心三角和实线组成的箭头表示,从子类指向父类。

关联关系
关联关系(Association)是指对象和对象之间的连接,它使一个对象知道另一个对象的属性和方法。也就是说,如果一个对象的类代码中,包含有另一个对象的引用,那么这两个对象之间就是关联关系。
关联关系有单向关联和双向关联。如果两个对象都知道(即可以调用)对方的公共属性和操作,那么二者就是双向关联。如果只有一个对象知道(即可以调用)另一个对象的公共属性和操作,那么就是单向关联。大多数关联都是单向关联,单向关联关系更容易建立和维护,有助于寻找可重用的类。
在UML图中,双向关联关系用带双箭头的实线或者无箭头的实线双线表示。单向关联用一个带箭头的实线表示,箭头指向被关联的对象。这就是导航性(Navigatity)。

一个对象可以持有其它对象的数组或者集合。在UML中,通过放置多重性(multipicity)表达式在关联线的末端来表示。多重性表达式可以是一个数字、一段范围或者是它们的组合。多重性允许的表达式示例如下:
- 数字:精确的数量
*或者0..*:表示0到多个0..1:表示0或者1个1..*:表示1到多个
关联关系又分为依赖关联、聚合关联和组合关联三种类型。
依赖关系
依赖(Dependency)关系是一种弱关联关系。如果对象A用到对象B,但是和B的关系不是太明显的时候,就可以把这种关系看作是依赖关系。如果对象A依赖于对象B,则 A “use a” B。比如驾驶员和汽车的关系,驾驶员使用汽车,二者之间就是依赖关系。
在UML类图中,依赖关系用一个带虚线的箭头表示,由使用方指向被使用方,表示使用方对象持有被使用方对象的引用,如图所示。

依赖关系在具体代码表现形式为B为A的构造器或方法中的局部变量、方法或构造器的参数、方法的返回值,或者A调用B的静态方法。
聚合关系
聚合(Aggregation)是关联关系的一种特例,它体现的是整体与部分的拥有关系,即 “has a” 的关系。此时整体与部分之间是可分离的,它们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享,所以聚合关系也常称为共享关系。例如,公司部门与员工的关系,一个员工可以属于多个部门,一个部门撤消了,员工可以转到其它部门。
在UML图中,聚合关系用空心菱形加实线箭头表示,空心菱形在整体一方,箭头指向部分一方,如图所示。

组合关系
组合(Composition)也是关联关系的一种特例,它同样体现整体与部分间的包含关系,即 “contains a” 的关系。但此时整体与部分是不可分的,部分也不能给其它整体共享,作为整体的对象负责部分的对象的生命周期。这种关系比聚合更强,也称为强聚合。如果A组合B,则A需要知道B的生存周期,即可能A负责生成或者释放B,或者A通过某种途径知道B的生成和释放。
例如,人包含头、躯干、四肢,它们的生命周期一致。当人出生时,头、躯干、四肢同时诞生。当人死亡时,作为人体组成部分的头、躯干、四肢同时死亡。
在UML图中,组合关系用实心菱形加实线箭头表示,实心菱形在整体一方,箭头指向部分一方,如图所示。

在实际应用开发时,两个对象之间的关系到底是聚合还是组合,有时候很难区别。在代码中,仅从类代码本身是区分不了聚合和组合的。如果一定要区分,那么如果在删除整体对象的时候,必须删掉部分对象,那么就是组合关系,否则可能就是聚合关系。从业务角度上来看,如果作为整体的对象必须要部分对象的参与,才能完成自己的职责,那么二者之间就是组合关系,否则就是聚合关系。
例如,汽车与轮胎,汽车作为整体,轮胎作为部分。如果用在二手车销售业务环境下,二者之间就是聚合关系。因为轮胎作为汽车的一个组成部分,它和汽车可以分别生产以后装配起来使用,但汽车可以换新轮胎,轮胎也可以卸下来给其它汽车使用。如果用在驾驶系统业务环境上,汽车如果没有轮胎,就无法完成行驶任务,二者之间就是一个组合关系。
再比如网上书店业务中的订单和订单项之间的关系,如果订单没有订单项,也就无法完成订单的业务,所以二者之间是组合关系。而购物车和商品之间的关系,因为商品的生命周期并不被购物车控制,商品可以被多个购物车共享,因此,二者之间是聚合关系。
编程题笔试复盘
米哈游笔试
米哈游遇到一个没见过的题,有思路就挺简单,题目意思是:
给两个字符串s,t,问s能不能通过增加或删除”mhy”这个子序列若干次,变成t。因为是子序列,所以m、h、y不用连续。
如果没见过这道题是话,就容易陷入子序列的顺序性上,实际上序列是“mhy”和“hmy”是一样的,因为“hmy”可以加一个“mhy”变成“mhmyhy”,然后再删掉一个“mhy”就变成了“mhy”。
所以在这道题上,不用考虑顺序,只用考虑出现的次数,如果不这样想是很难很难写的。
总结一下:对于子序列能添加、删除若干次的话,那么可能可以不用考虑这个序列中字符的顺序。