前言
前几天follow完了tinywebsever的项目,分析了很多代码,最后也能跑起来。不过感觉整体的代码框架有些杂乱,代码也有冗余、不清晰的地方,比如互斥锁在c++11已经有专门的实现,不需要自己实现了。
作者也推荐了另一个c++11写的更简洁更优雅的项目实现:markparticle/WebServer: C++ Linux WebServer服务器 (github.com)
上一个项目最大的好处是作者专门写了一系列分析的文章,而这个项目没有教程也没什么注释,因此打算再写篇博客分析一下代码,写下注释,更重要的是把代码框架、逻辑理清楚,以及看看c++11实现的方便之处。
另外,在这里说一下size_t,很多c系的程序员对这个类型用的比较少,但这个项目里经常出现。
可以参考下:(24 封私信 / 80 条消息) size_t 这个类型的意义是什么? - 知乎 (zhihu.com)。
主要还是为了可移植性,不同平台对于size_t的大小不同,64位系统是8字节,32位系统是4字节。为了方便移植,许多库函数的参数、返回值都是size_t。当换了个平台时,可以不改动代码而传入、接收更大或更小的值;并且系统不会使用更大的类型,从而加快速度。注意这些都是相对只用int、unsigned int、unsigned long作为类型对比的结果,用size_t有弹性。
但是,一个size_t类型的参数的用途却是用户定义的,比如可以把size_t就当int用,用来数组寻址等等,也可以用它来接收函数返回的参数然后作为一些长度,这些长度表示字节、还是两个字节都是用户决定的,它本身的值是多少就是多少。
一般用于作索引和表示单字节长度:
- size_t传达了语义:您立即知道它表示一个以字节为单位的大小或一个索引,而不仅仅是另一个整数。
- std::size_t是任何sizeof表达式的类型,并且保证能够表达C ++中任何对象(包括任何数组)的最大大小。通过扩展,它也保证对任何数组索引都足够大,因此它是数组上逐个索引循环的自然类型。
C++11可以将{}初始化器用于任何类型(可以使用等号,也可以不使用),这是一种通用的初始化语法。
在C++11中,集合(列表)的初始化已经成为C++的一个基本功能,被称为“初始化列表(initializer list)”
1 | int a[] = { 1, 2, 3 }; //C++98支持,C++11支持 |
线程池
应用了很多新特性,比较难理解,要耐心一点。
右值引用可参考:C++11右值引用(一看即懂) (biancheng.net)
std::move()可参考:C++11 move()函数:将左值强制转换为右值 (biancheng.net)
std::forward()可参考:C++11完美转发及实现方法详解 (biancheng.net)
1 | /* |
先介绍下std::mutex:头文件<mutex> ,实际上跟linux中pthread的互斥锁差不多,手动上锁和解锁。
- lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:(1). 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。(2). 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
- unlock(), 解锁,释放对互斥量的所有权。
- try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况,(1). 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。(2). 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
真正好用的是std::lock_guard:头文件<mutex> ,使用RAII机制,退出作用域就解锁。
template <class _Mutex> class lock_guard { // class with destructor that unlocks a mutex public: using mutex_type = _Mutex; //无adopt_lock参数,构造时加锁 explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) { // construct and lock _MyMutex.lock(); } //有adopt_lock参数,构造时不加锁 lock_guard(_Mutex& _Mtx, adopt_lock_t) : _MyMutex(_Mtx) {} // construct but don't lock //析构解锁 ~lock_guard() noexcept { _MyMutex.unlock(); } //屏蔽拷贝构造 lock_guard(const lock_guard&) = delete; lock_guard& operator=(const lock_guard&) = delete; private: _Mutex& _MyMutex; };lock_guard具有两种构造方法:
lock_guard(mutex& m)lock_guard(mutex& m, adopt_lock)其中mutex& m是互斥量,参数adopt_lock表示假定调用线程已经获得互斥体所有权并对其进行管理了。
再说下std::unique_lock:头文件<mutex>,也是使用RAII机制,定义和lock_guard相同。
主要还是说下二者的对比:
- std::unique_lock 与std::lock_guard都能实现自动加锁与解锁功能,但是std::unique_lock要比std::lock_guard更灵活,但是更灵活的代价是占用空间相对更大一点且相对更慢一点。
- 它提供了
lock()和unlock()接口,能记录现在处于上锁还是没上锁状态,在析构的时候,会根据当前状态来决定是否要进行解锁。而lock_guard一锁就锁住一个作用域,直到退出才解锁,没有lock和unlock接口,有时只想锁住一段代码,用unique_lock就更灵活。 unique_lock和lock_guard都不能复制,lock_guard不能移动,但是unique_lock可以- 可以参考[c++11]多线程编程(五)——unique_lock - 简书 (jianshu.com)
条件变量std::condition_variable:头文件 <condition_variable>,和linux的差不多了,可以看下(29条消息) C++11多线程条件变量std::condition_variable详解(转 )_山城盛夏的博客-CSDN博客_std::condition_variable 详解,当然不看也可以,无非是等待和唤醒。
关于std::function,主要是用来包装函数的,像函数一样调用,具体可以参考之前的博客:lambda表达式 | JySama
std::function是一个函数包装器,该函数包装器模板能包装任何类型的可调用实体,如普通函数,函数对象,lamda表达式等。包装器可拷贝,移动等,并且包装器类型仅仅依赖于调用特征,而不依赖于可调用元素自身的类型。std::function是C++11的新特性,包含在头文件<functional>中。
一个std::function类型对象实例可以包装下列这几种可调用实体:函数、函数指针、成员函数、静态函数、lamda表达式和函数对象。std::function对象实例可被拷贝和移动,并且可以使用指定的调用特征来直接调用目标元素。当std::function对象实例未包含任何实际可调用实体时,调用该std::function对象实例将抛出std::bad_function_call异常。
std::forward():完美转发
当我们将一个右值引用传入函数时,他在实参中有了命名,所以继续往下传或者调用其他函数时,根据C++ 标准的定义,这个参数变成了一个左值。那么他永远不会调用接下来函数的右值版本,这可能在一些情况下造成拷贝。为了解决这个问题 C++ 11引入了完美转发,根据右值判断的推倒,调用forward 传出的值,若原来是一个右值,那么他转出来就是一个右值,否则为一个左值。这样的处理就完美的转发了原有参数的左右值属性,不会造成一些不必要的拷贝。
std::forward必须配合T&&来使用。例如T&&接受左值int&时,T会被推断为int&,而T&&接受右值int&&时,T被推断为int。
std::thread:头文件<thread>,可移动不可复制
- 默认构造函数,创建一个空的
std::thread执行对象: thread() noexcept; - 初始化构造函数,创建一个
std::thread对象,该std::thread对象可被joinable,新产生的线程会调用fn函数,该函数的参数由args给出。- template <class Fn, class… Args> explicit thread(Fn&& fn, Args&&… args);
数据库
数据库如出一辙,很好理解
1 | /* |
1 | /* |
1 | /* |
日志系统
阻塞队列,用互斥锁再封装
1 | /* |
std::chrono::seconds:一个类,获取多少时间,这里以临时变量的形式传给wait_for,持续…seconds,超时结果就是timeout,和cv_status的timeout相等,借此判断是否超时。
std::cv_status:定义于头文件 <condition_variable>,带作用域枚举 std::cv_status 描述定时等待是否因时限返回。成员:
no_timeout:条件变量因notify_all、notify_one或虚假地被唤醒timeout:条件变量因时限耗尽被唤醒
wait_for:
返回值:若经过 rel_time 所指定的关联时限则为 std::cv_status::timeout,否则为 std::cv_status::no_timeout 。
1 | std::cv_status wait_for( std::unique_lock<std::mutex>& lock, |
1 | /* |
1 | /* |
缓冲区
1 | /* |
1 | /* |
定时器
注意:这里没有加锁,上层的调用要加锁
chrono可以稍微参考下:(29条消息) C++11的chrono库,可实现毫秒微秒级定时_oncealong的博客-CSDN博客_chrono sleep。里面提了三种类型,虽然不详细。
- std::chrono::high_resolution_clock:high_resolution_clock只不过是system_clock或者steady_clock的typedef。用于获取时间点。
- std::chrono::system_clock 它表示当前的系统时钟,系统中运行的所有进程使用now()得到的时间是一致的。
- std::chrono::steady_clock 为了表示稳定的时间间隔,后一次调用now()得到的时间总是比前一次的值大。用在需要得到时间间隔,并且这个时间间隔不会因为修改系统时间而受影响的场景;它是单调的时钟,相当于教练手中的秒表;只会增长,适合用于记录程序耗时,他表示的时钟是不能设置的。
- 可以使用now()方法取得时间,是一个纳秒,相对系统启动的时间多少。一般用time_point:
std::chrono::high_resolution_clock::time_point t1=std::chrono::high_resolution_clock::now();或者auto t1=std::chrono::high_resolution_clock::now();
- std::chrono::milliseconds:表示毫秒,是一个时间间隔。
- 在代码里面,now()+MS(timeout)被赋值到high_resolution_clock的time_point上,毫秒会转换为纳秒加上去。
1 | /* |
1 | /* |
HTTP
处理响应
涉及到一个string.data(),看到比较好的文章里面提到了一点:
为什么C语言风格的字符串要以’\0’结尾,C++(string)可以不要?
c语言用char*指针作为字符串时,在读取字符串时需要一个特殊字符0来标记指针的结束位置,也就是通常认为的字符串结束标记。而c++语言则是面向对象的(string),长度信息直接被存储在了对象的成员中,读取字符串可以直接根据这个长度来读取,所以就没必要需要结束标记了。而且结束标记也不利于读取字符串中夹杂0字符的字符串。
- 首先会尝试把文件信息写入stat结构体,根据文件找不找得到、文件权限,得到对应的状态码。stat结构体主要是获得文件size
- 如果状态码是404那些,就把路径和stat结构体修改为404那些html文件的路径,如果是200OK,就再不修改。
- 然后添加状态行、头部信息
- 最后添加文件内容信息:
- 先根据文件路径打开文件,可能是404那些html,也可能是真的文件。如果打开失败,会返回一个file not found的html
- 打开成功的话会尝试去内存映射,stat结构体的size在这有用。如果映射失败,也会返回一个file not found的html
- 如果打开成功,会添加文件的长度信息,把内存地址指针保存,可通过接口调用。因为不会真正写入文件内容
- 在添加文件长度信息后,顺便添加一个空行。
- 没有写入内容,等待外部写入。
1 | /* |
1 | /* |
处理请求
用到正则,语法:正则表达式 – 语法 | 菜鸟教程 (runoob.com)
几种用法:C++ regex库的三种正则表达式操作 - 上官栋 - 博客园 (cnblogs.com)
1 | /* |
1 | /* |
上层调用
1 | /* |
1 | /* |
服务器顶层
事务处理
1 | /* |
1 | /* |
顶层调用
1 | /* |
1 | /* |
main
config里啥东西没有,主要也没啥好配的,就直接main里面启动。服务器顶层的isclose没作用,ctrl+c终止进程,资源由操作系统自动回收。
1 | /* |
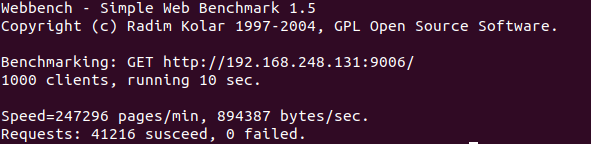
压力测试截图