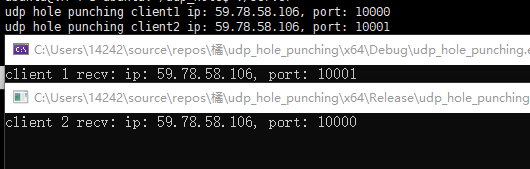
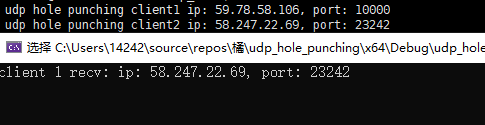
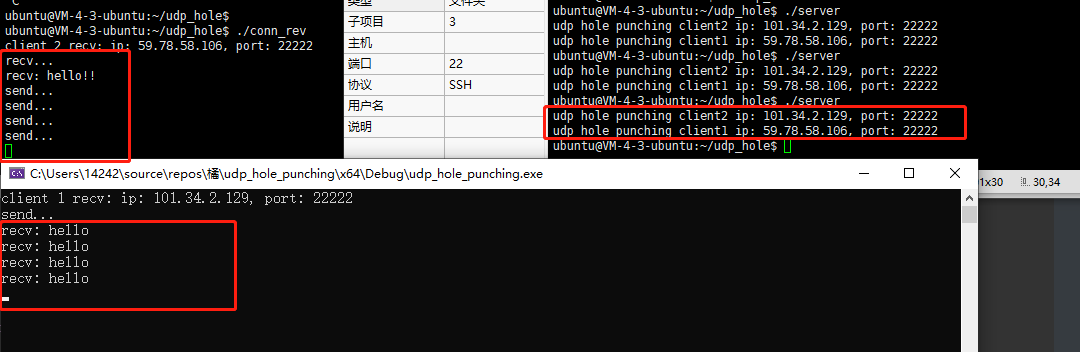
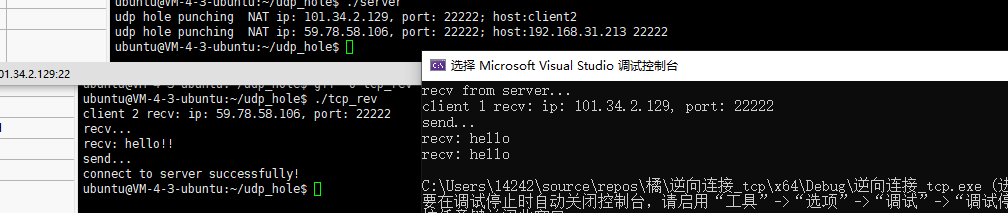
intmain() { int udpfd; int tcpfd; constint port = 22222; init_udp_Socket(udpfd, port); init_tcp_Socket(tcpfd,port); if (!udp_hole_punching(udpfd, SERVER_IP, udpPORT3)) { exit(1); }
intmain() { int udpfd; int tcpfd; constint port = 22222; init_udp_Socket(udpfd, port); init_tcp_Socket(tcpfd,port); if (!udp_hole_punching(udpfd, SERVER_IP, udpPORT3)) { exit(1); }
//bind port if (bind(listenfd, (struct sockaddr*)&socketaddr, sizeof(socketaddr)) == -1) { printf("bind port-%d error !\n", port); closesocket(listenfd); exit(1); }
//Using UDP requires disabling errors /* * If sending a datagram using the sendto function results in an "ICMP port unreachable" response and the select function is set for readfds, * the program returns 1 and the subsequent call to the recvfrom function does not work with a WSAECONNRESET (10054) error response. * In Microsoft Windows NT 4.0, this situation causes the select function to block or time out. */ BOOL bEnalbeConnRestError = FALSE; DWORD dwBytesReturned = 0; WSAIoctl(listenfd, SIO_UDP_CONNRESET, &bEnalbeConnRestError, sizeof(bEnalbeConnRestError), \ NULL, 0, &dwBytesReturned, NULL, NULL); }
int getNameRet = gethostname(name, sizeof(name));//get host name //get private ip list hostent* host = gethostbyname(name);//need to disable c4996 error
if (NULL == host) { return result; }
in_addr* pAddr = (in_addr*)*host->h_addr_list;
for (int i = 0; host->h_addr_list[i] != 0; i++) { char ip[20] = { '\0' };
vector<string> myipList = getIpList(); string myip = myipList[myipList.size() - 1]; //send the last one string myip_port = myip + " " + to_string(myPort); //send the private ip size_t res = sendto(udpfd, myip_port.c_str(), myip_port.size(), 0, (struct sockaddr*)&socketaddr, sizeof(socketaddr)); if (res == SOCKET_ERROR) { printf("udp sendto error!\n"); returnfalse; } returntrue;
}
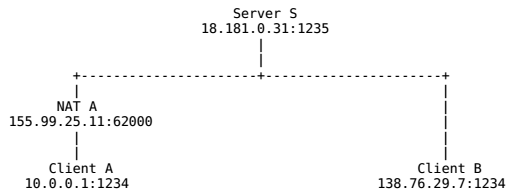
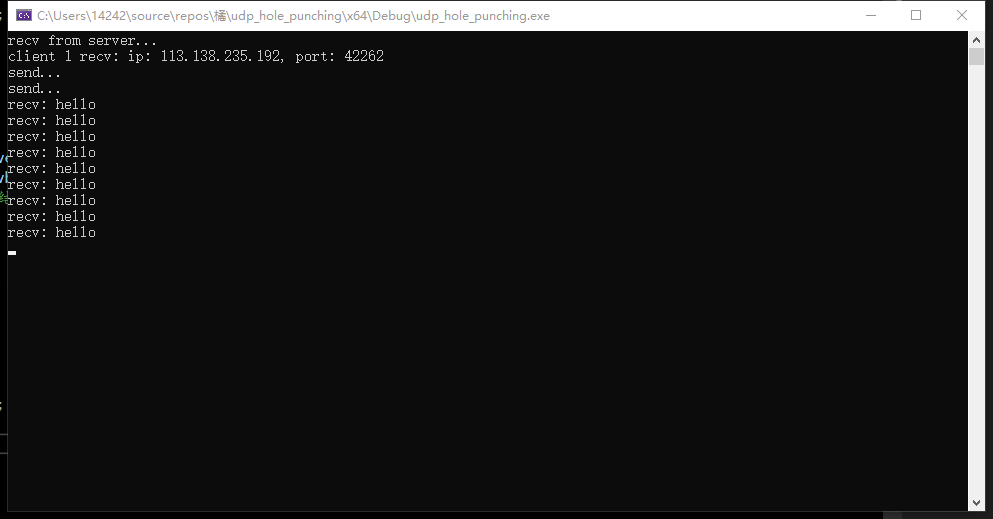
//send one or more messages to the other party(punch a hole) booludpHolePunch(SOCKET& udpfd, constchar* gateway_ip, constint gatewayPort) { structsockaddr_in gateway; gateway.sin_family = AF_INET; gateway.sin_port = htons(gatewayPort); inet_pton(AF_INET, gateway_ip, &gateway.sin_addr);
char sendbuf[10] = "hello!"; //send two messages int res = sendto(udpfd, sendbuf, strlen(sendbuf), 0, (struct sockaddr*)&gateway, sizeof(gateway)); if (res == SOCKET_ERROR) { printf("udp sendto error1!\n"); returnfalse; } res = sendto(udpfd, sendbuf, strlen(sendbuf), 0, (struct sockaddr*)&gateway, sizeof(gateway)); if (res == SOCKET_ERROR) { printf("udp sendto error2!\n"); returnfalse; } returntrue; }
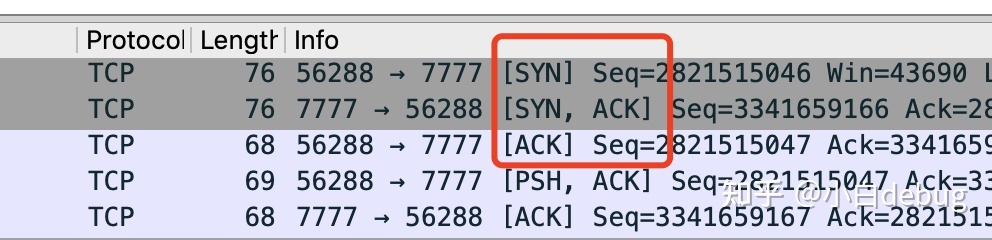
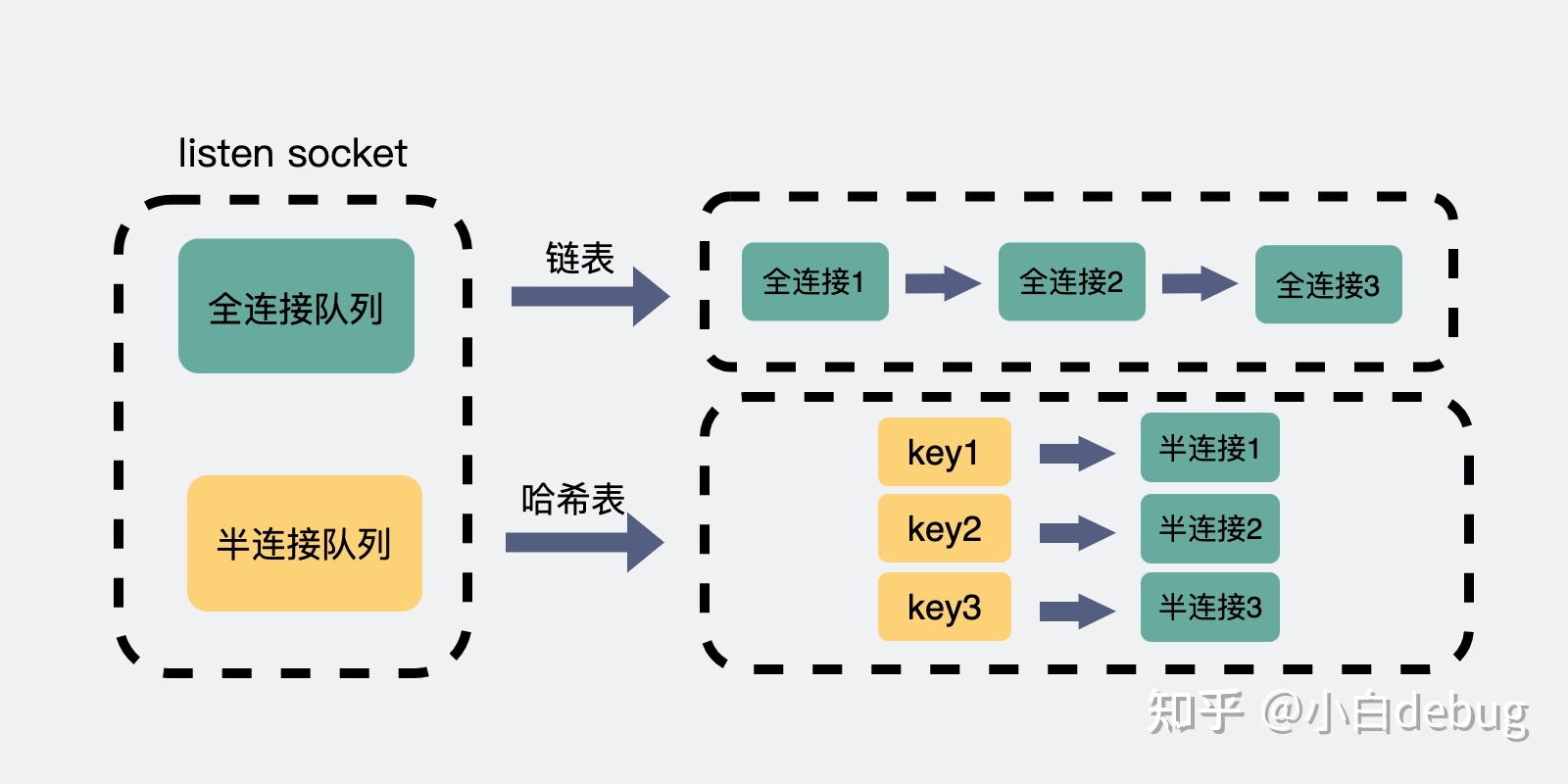
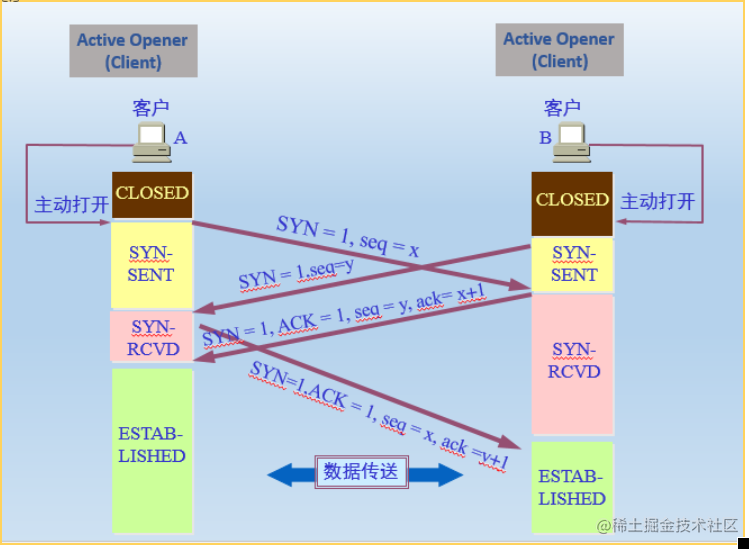
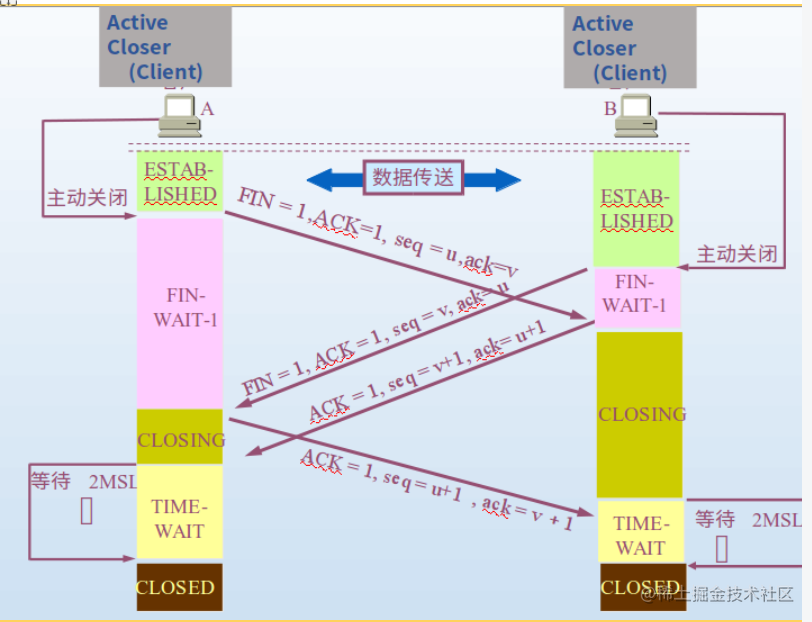
inttcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { ... /* Socket identity is still unknown (sport may be zero). * However we set state to SYN-SENT and not releasing socket * lock select source port, enter ourselves into the hash tables and * complete initialization after this. */ tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(&tcp_death_row, sk); ... }
注意这句注释 enter ourselves into the hash tables,在inet_hash_connect函数中,socket在调用connect的时候就会把自己加入到establish hash表,虽然它此时连syn都还没有发送。确切的讲,应该是在它调用的__inet_check_established函数中。
staticinttcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb, conststruct tcphdr *th) { structinet_connection_sock *icsk = inet_csk(sk); structtcp_sock *tp = tcp_sk(sk); structtcp_fastopen_cookie foc = { .len = -1 }; int saved_clamp = tp->rx_opt.mss_clamp; ... if (th->ack) { //包中带ACK标记,走此路径 ...//另外的处理流程 return-1; } if (th->syn) { /* We see SYN without ACK. It is attempt of * simultaneous connect with crossed SYNs. * Particularly, it can be connect to self. */ tcp_set_state(sk, TCP_SYN_RECV);
/* RFC1323: The window in SYN & SYN/ACK segments is * never scaled. */ tp->snd_wnd = ntohs(th->window); tp->snd_wl1 = TCP_SKB_CB(skb)->seq; tp->max_window = tp->snd_wnd;
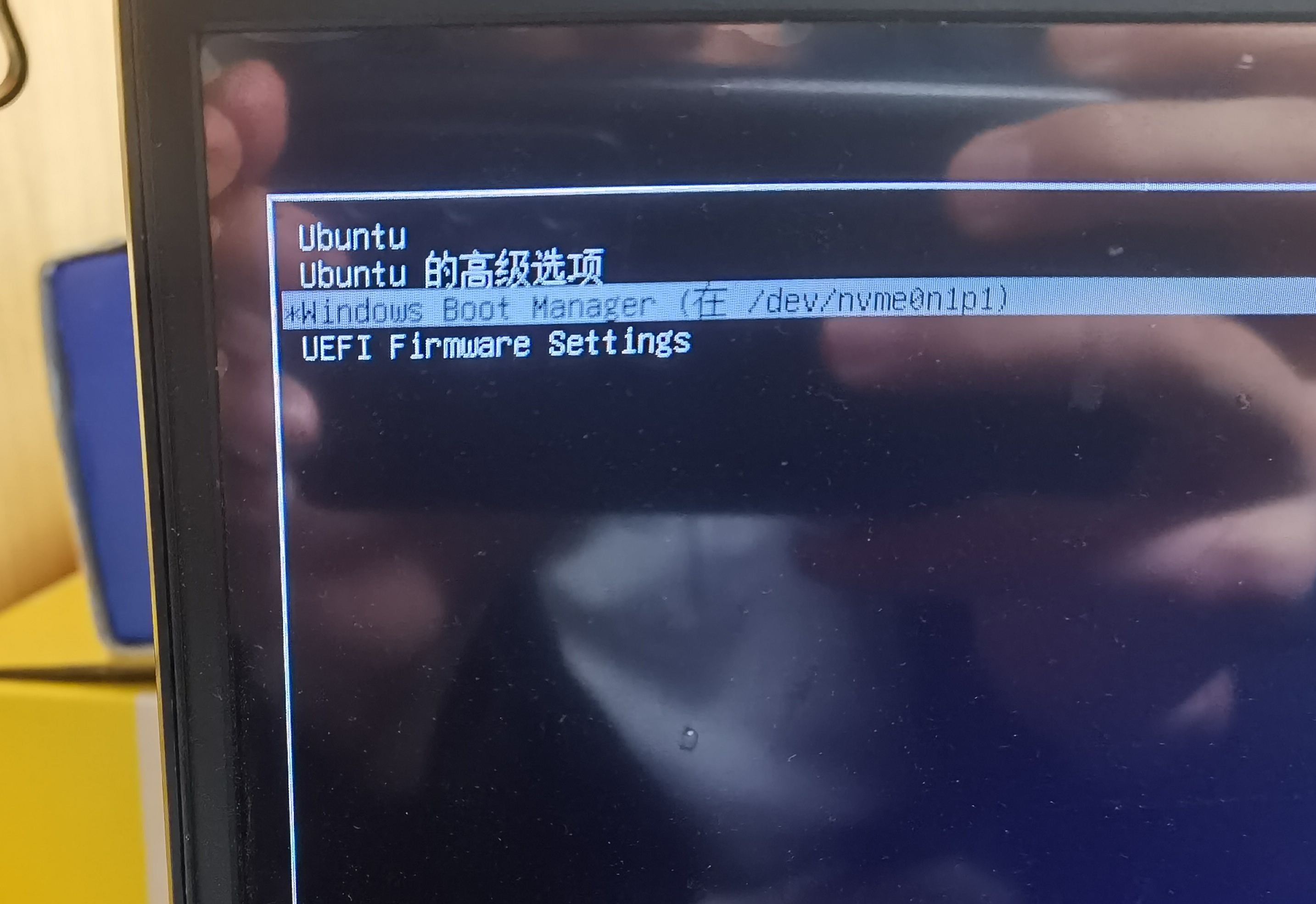
# If you change this file, run 'update-grub' afterwards to update # /boot/grub/grub.cfg. # For full documentation of the options in this file, see: # info -f grub -n 'Simple configuration'
//运行结果,数一下线程有没有正常退出 sun2@ubuntu:~/Desktop/websever_test$ g++ -std=c++14 -o test_threadpool test_threadpool.cpp -lpthread sun2@ubuntu:~/Desktop/websever_test$ ./test_threadpool this is [5] task this is [6] task this is [7] task this is [8] task this is [9] task this is [10] task this is [11] task this is [12] task this is [13] task this is [14] task [5] task quit! this is [15] task [6] task quit! this is [16] task [7] task quit! this is [17] task [8] task quit! this is [18] task [9] task quit! this is [19] task [10] task quit! thread exit! //1 [11] task quit! thread exit! //2 [12] task quit! thread exit! //3 [13] task quit! thread exit! //4 [14] task quit! thread exit! //5 [15] task quit! thread exit! //6 [16] task quit! thread exit! //7 [17] task quit! thread exit! //8 [18] task quit! thread exit! //9 [19] task quit! thread exit! //10 //test成功
日志系统
这一块比较复杂,分解知识点,一点点细学。
时间类chrono
这个在日志系统用了一点,不过也可以用来输出时间,就在这里学习了。
Duration
1 2 3 4
//duration表示一段时间间隔,用来记录时间长度,可以表示几秒钟、几分钟或者几个小时的时间间隔,duration的原型是: template<classRep, classPeriod = std::ratio<1>> class duration; //第一个模板参数Rep是一个数值类型,表示时钟个数;第二个模板参数是一个默认模板参数std::ratio,它的原型是: template<std::intmax_t Num, std::intmax_t Denom = 1> class ratio;
//测试结果 sun2@ubuntu:~/Desktop/websever_test/valist$ g++ -std=c++14 -o vstest vstest.cpp sun2@ubuntu:~/Desktop/websever_test/valist$ ./vstest ----------测试vsprintf------------- jy is 20 years old, good!
----------测试vsnprintf------------- 只有10的buffer size: xuepi is 拥有50的buffer size: xuepi is 20 years old, nice!
----------测试vsnprintf,并且size超出了buffer的大小------------- xuepi is 20 years old, nice! //可以看出即使超出了buffer的size也不会报错,而是继续向buffer拷贝,打印时因为首地址的关系会全打印出来 //这个size参数是给vsnprintf的,告诉它最多写多少进buffer,可以与buffer本身的大小无关,但一般会关联到buffer的大小
intmain() { int level; for(int i=0;i<1024;i++) { level = i%4; write(level,"hello, this is num [%d], for %s %d",i,"level",level); } fclose(logfp); return0; }
//我们想用一个函数封装write函数,比如logoinfo调用level1的write,并且还要能判断loglevel支不支持 //但函数封装变参函数,为了传递可变参数,实际上还要修改write的实现,不如用宏来实现,使用##__VA_ARGS__传递可变参数,让编译器把宏替换为真实的函数 //##__VA_ARGS__的优点是,对于宏调用,如果format是一个字符串也即后面没有可变参数,## 操作将使预处理器(preprocessor)去除掉它前面的那个逗号。 //宏与类无关了,这里必须isopen了才能使用 #define LOG_BASE(level, format, ...) \ do {\ Log* log = Log::instance();\ if (log->isopen() && log->getlevel() <= level) {\ log->write(level, format, ##__VA_ARGS__); \ }\ } while(0);
#define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0); #define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0); #define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0); #define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0);
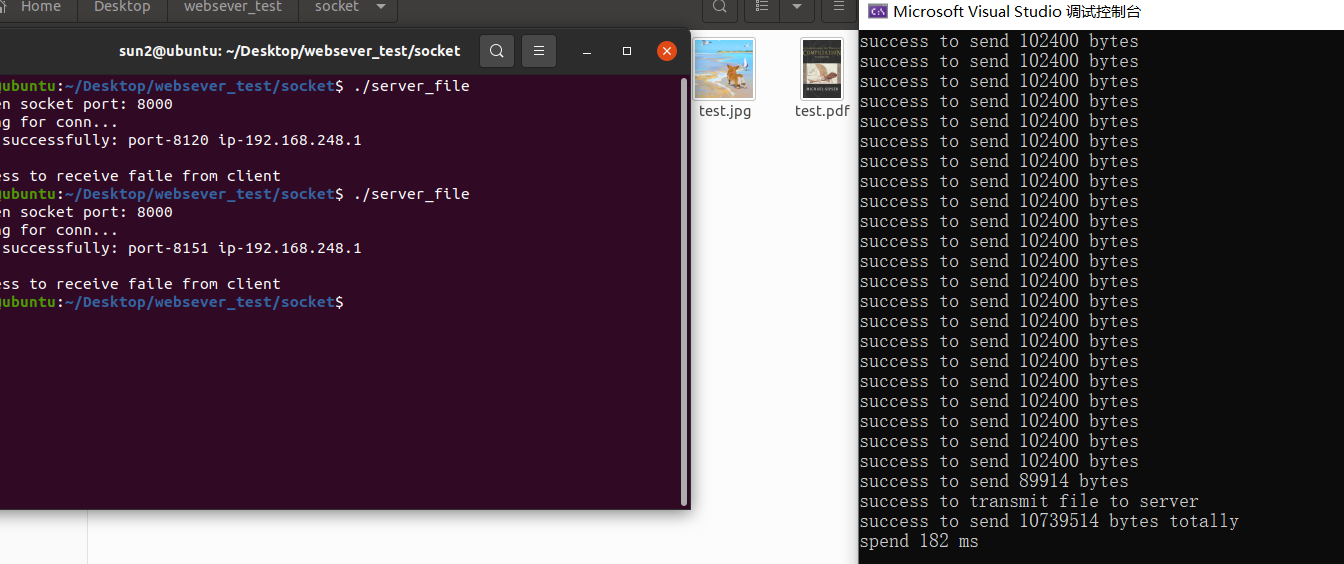
if (nSend == SOCKET_ERROR)//网络断开或copy出错 { std::cerr << "the connection to server has been failed" << std::endl; exit(1); } totalSend += nSend; printf("success to send %d bytes\n", nSend);
if (feof(fp))//读了,发完,再判断是否到达末尾 { printf("success to transmit file to server\n"); break; } } std::chrono::system_clock::time_point time2 = std::chrono::system_clock::now(); printf("success to send %d bytes totally\n", totalSend); std::cout<<"spend "<<std::chrono::duration_cast<std::chrono::milliseconds>(time2-time1).count()<<" ms"<<std::endl; closesocket(connfd); WSACleanup(); return0; }
当我们将一个右值引用传入函数时,他在实参中有了命名,所以继续往下传或者调用其他函数时,根据C++ 标准的定义,这个参数变成了一个左值。那么他永远不会调用接下来函数的右值版本,这可能在一些情况下造成拷贝。为了解决这个问题 C++ 11引入了完美转发,根据右值判断的推倒,调用forward 传出的值,若原来是一个右值,那么他转出来就是一个右值,否则为一个左值。这样的处理就完美的转发了原有参数的左右值属性,不会造成一些不必要的拷贝。
bool isOpen_; Buffer buff_;//一个日志仅有一个buffer,因为write被互斥锁锁住了 int level_; bool isAsync_;
FILE* fp_; std::unique_ptr<BlockDeque<std::string>> deque_; //智能指针,还没有实例 std::unique_ptr<std::thread> writeThread_;//指向一个thread,还没有实例 std::mutex mtx_; }; //以宏的形式,感觉写个string形式也行 #define LOG_BASE(level, format, ...) \ do {\ Log* log = Log::Instance();\ if (log->IsOpen() && log->GetLevel() <= level) {\ log->write(level, format, ##__VA_ARGS__); \ log->flush();\ }\ } while(0);
#define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0); #define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0); #define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0); #define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0);
ssize_tHttpConn::read(int* saveErrno){//读数据到自己的缓冲区 ssize_t len = -1; do { len = readBuff_.ReadFd(fd_, saveErrno);//调用读缓冲区 if (len <= 0) { break; } } while (isET);//如果是ET模式就一直读取直到len==0,LT模式就读一次就结束 return len; }
classWebServer { public: WebServer( int port, int trigMode, int timeoutMS, bool OptLinger, int sqlPort, constchar* sqlUser, constchar* sqlPwd, constchar* dbName, int connPoolNum, int threadNum, bool openLog, int logLevel, int logQueSize);
* ``` va_list的使用方法: a) 首先在函数中定义一个具有va_list型的变量,这个变量是指向参数的指针。 b) 然后用va_start宏初始化变量刚定义的va_list变量,使其指向第一个可变参数的地址。 c) 然后va_arg返回可变参数,va_arg的第二个参数是你要返回的参数的类型(如果多个可变参数,依次调用va_arg获取各个参数)。 d) 最后使用va_end宏结束可变参数的获取。
int vsnprintf (char * s, size_t n, const char * format, va_list arg );
```c++ #include<unistd.h> #include<fcntl.h> int fcntl(int fd, int cmd); int fcntl(int fd, int cmd, long arg); int fcntl(int fd, int cmd ,struct flock* lock);
* ```c++ struct stat { dev_t st_dev; /* ID of device containing file -文件所在设备的ID*/ ino_t st_ino; /* inode number -inode节点号*/ mode_t st_mode; /* protection -保护模式?*/ nlink_t st_nlink; /* number of hard links -链向此文件的连接数(硬连接)*/ uid_t st_uid; /* user ID of owner -user id*/ gid_t st_gid; /* group ID of owner - group id*/ dev_t st_rdev; /* device ID (if special file) -设备号,针对设备文件*/ off_t st_size; /* total size, in bytes -文件大小,字节为单位*/ blksize_t st_blksize; /* blocksize for filesystem I/O -系统块的大小*/ blkcnt_t st_blocks; /* number of blocks allocated -文件所占块数*/ time_t st_atime; /* time of last access -最近存取时间*/ time_t st_mtime; /* time of last modification -最近修改时间*/ time_t st_ctime; /* time of last status change - */ };
#include <stdio.h> #include <string.h> //for strerror() //#include <errno.h> int main() { int tmp = 0; for(tmp = 0; tmp <=256; tmp++) { printf("errno: %2d\t%s\n",tmp,strerror(tmp)); } return 0; } //输出信息如下: errno: 0 Success errno: 1 Operation not permitted errno: 2 No such file or directory errno: 3 No such process errno: 4 Interrupted system call errno: 5 Input/output error errno: 6 No such device or address errno: 7 Argument list too long errno: 8 Exec format error errno: 9 Bad file descriptor errno: 10 No child processes errno: 11 Resource temporarily unavailable errno: 12 Cannot allocate memory errno: 13 Permission denied errno: 14 Bad address errno: 15 Block device required errno: 16 Device or resource busy errno: 17 File exists errno: 18 Invalid cross-device link errno: 19 No such device errno: 20 Not a directory errno: 21 Is a directory errno: 22 Invalid argument errno: 23 Too many open files in system errno: 24 Too many open files errno: 25 Inappropriate ioctl for device errno: 26 Text file busy errno: 27 File too large errno: 28 No space left on device errno: 29 Illegal seek errno: 30 Read-only file system errno: 31 Too many links errno: 32 Broken pipe errno: 33 Numerical argument out of domain errno: 34 Numerical result out of range errno: 35 Resource deadlock avoided errno: 36 File name too long errno: 37 No locks available errno: 38 Function not implemented errno: 39 Directory not empty errno: 40 Too many levels of symbolic links errno: 41 Unknown error 41 errno: 42 No message of desired type errno: 43 Identifier removed errno: 44 Channel number out of range errno: 45 Level 2 not synchronized errno: 46 Level 3 halted errno: 47 Level 3 reset errno: 48 Link number out of range errno: 49 Protocol driver not attached errno: 50 No CSI structure available errno: 51 Level 2 halted errno: 52 Invalid exchange errno: 53 Invalid request descriptor errno: 54 Exchange full errno: 55 No anode errno: 56 Invalid request code errno: 57 Invalid slot errno: 58 Unknown error 58 errno: 59 Bad font file format errno: 60 Device not a stream errno: 61 No data available errno: 62 Timer expired errno: 63 Out of streams resources errno: 64 Machine is not on the network errno: 65 Package not installed errno: 66 Object is remote errno: 67 Link has been severed errno: 68 Advertise error errno: 69 Srmount error errno: 70 Communication error on send errno: 71 Protocol error errno: 72 Multihop attempted errno: 73 RFS specific error errno: 74 Bad message errno: 75 Value too large for defined data type errno: 76 Name not unique on network errno: 77 File descriptor in bad state errno: 78 Remote address changed errno: 79 Can not access a needed shared library errno: 80 Accessing a corrupted shared library errno: 81 .lib section in a.out corrupted errno: 82 Attempting to link in too many shared libraries errno: 83 Cannot exec a shared library directly errno: 84 Invalid or incomplete multibyte or wide character errno: 85 Interrupted system call should be restarted errno: 86 Streams pipe error errno: 87 Too many users errno: 88 Socket operation on non-socket errno: 89 Destination address required errno: 90 Message too long errno: 91 Protocol wrong type for socket errno: 92 Protocol not available errno: 93 Protocol not supported errno: 94 Socket type not supported errno: 95 Operation not supported errno: 96 Protocol family not supported errno: 97 Address family not supported by protocol errno: 98 Address already in use errno: 99 Cannot assign requested address errno: 100 Network is down errno: 101 Network is unreachable errno: 102 Network dropped connection on reset errno: 103 Software caused connection abort errno: 104 Connection reset by peer errno: 105 No buffer space available errno: 106 Transport endpoint is already connected errno: 107 Transport endpoint is not connected errno: 108 Cannot send after transport endpoint shutdown errno: 109 Too many references: cannot splice errno: 110 Connection timed out errno: 111 Connection refused errno: 112 Host is down errno: 113 No route to host errno: 114 Operation already in progress errno: 115 Operation now in progress errno: 116 Stale file handle errno: 117 Structure needs cleaning errno: 118 Not a XENIX named type file errno: 119 No XENIX semaphores available errno: 120 Is a named type file errno: 121 Remote I/O error errno: 122 Disk quota exceeded errno: 123 No medium found errno: 124 Wrong medium type errno: 125 Operation canceled errno: 126 Required key not available errno: 127 Key has expired errno: 128 Key has been revoked errno: 129 Key was rejected by service errno: 130 Owner died errno: 131 State not recoverable errno: 132 Operation not possible due to RF-kill errno: 133 Memory page has hardware error errno: 134~255 unknown error!
#define EDEADLK 35 /* Resource deadlock would occur */ #define ENAMETOOLONG 36 /* File name too long */ #define ENOLCK 37 /* No record locks available */ #define ENOSYS 38 /* Function not implemented */ #define ENOTEMPTY 39 /* Directory not empty */ #define ELOOP 40 /* Too many symbolic links encountered */ #define EWOULDBLOCK EAGAIN /* Operation would block */ #define ENOMSG 42 /* No message of desired type */ #define EIDRM 43 /* Identifier removed */ #define ECHRNG 44 /* Channel number out of range */ #define EL2NSYNC 45 /* Level 2 not synchronized */ #define EL3HLT 46 /* Level 3 halted */ #define EL3RST 47 /* Level 3 reset */ #define ELNRNG 48 /* Link number out of range */ #define EUNATCH 49 /* Protocol driver not attached */ #define ENOCSI 50 /* No CSI structure available */ #define EL2HLT 51 /* Level 2 halted */ #define EBADE 52 /* Invalid exchange */ #define EBADR 53 /* Invalid request descriptor */ #define EXFULL 54 /* Exchange full */ #define ENOANO 55 /* No anode */ #define EBADRQC 56 /* Invalid request code */ #define EBADSLT 57 /* Invalid slot */
#define EDEADLOCK EDEADLK
#define EBFONT 59 /* Bad font file format */ #define ENOSTR 60 /* Device not a stream */ #define ENODATA 61 /* No data available */ #define ETIME 62 /* Timer expired */ #define ENOSR 63 /* Out of streams resources */ #define ENONET 64 /* Machine is not on the network */ #define ENOPKG 65 /* Package not installed */ #define EREMOTE 66 /* Object is remote */ #define ENOLINK 67 /* Link has been severed */ #define EADV 68 /* Advertise error */ #define ESRMNT 69 /* Srmount error */ #define ECOMM 70 /* Communication error on send */ #define EPROTO 71 /* Protocol error */ #define EMULTIHOP 72 /* Multihop attempted */ #define EDOTDOT 73 /* RFS specific error */ #define EBADMSG 74 /* Not a data message */ #define EOVERFLOW 75 /* Value too large for defined data type */ #define ENOTUNIQ 76 /* Name not unique on network */ #define EBADFD 77 /* File descriptor in bad state */ #define EREMCHG 78 /* Remote address changed */ #define ELIBACC 79 /* Can not access a needed shared library */ #define ELIBBAD 80 /* Accessing a corrupted shared library */ #define ELIBSCN 81 /* .lib section in a.out corrupted */ #define ELIBMAX 82 /* Attempting to link in too many shared libraries */
#define ELIBEXEC 83 /* Cannot exec a shared library directly */ #define EILSEQ 84 /* Illegal byte sequence */ #define ERESTART 85 /* Interrupted system call should be restarted */ #define ESTRPIPE 86 /* Streams pipe error */ #define EUSERS 87 /* Too many users */ #define ENOTSOCK 88 /* Socket operation on non-socket */ #define EDESTADDRREQ 89 /* Destination address required */ #define EMSGSIZE 90 /* Message too long */ #define EPROTOTYPE 91 /* Protocol wrong type for socket */ #define ENOPROTOOPT 92 /* Protocol not available */ #define EPROTONOSUPPORT 93 /* Protocol not supported */ #define ESOCKTNOSUPPORT 94 /* Socket type not supported */ #define EOPNOTSUPP 95 /* Operation not supported on transport endpoint */ #define EPFNOSUPPORT 96 /* Protocol family not supported */ #define EAFNOSUPPORT 97 /* Address family not supported by protocol */ #define EADDRINUSE 98 /* Address already in use */ #define EADDRNOTAVAIL 99 /* Cannot assign requested address */ #define ENETDOWN 100 /* Network is down */ #define ENETUNREACH 101 /* Network is unreachable */ #define ENETRESET 102 /* Network dropped connection because of reset */ #define ECONNABORTED 103 /* Software caused connection abort */ #define ECONNRESET 104 /* Connection reset by peer */ #define ENOBUFS 105 /* No buffer space available */ #define EISCONN 106 /* Transport endpoint is already connected */ #define ENOTCONN 107 /* Transport endpoint is not connected */ #define ESHUTDOWN 108 /* Cannot send after transport endpoint shutdown */ #define ETOOMANYREFS 109 /* Too many references: cannot splice */ #define ETIMEDOUT 110 /* Connection timed out */ #define ECONNREFUSED 111 /* Connection refused */ #define EHOSTDOWN 112 /* Host is down */ #define EHOSTUNREACH 113 /* No route to host */ #define EALREADY 114 /* Operation already in progress */ #define EINPROGRESS 115 /* Operation now in progress */ #define ESTALE 116 /* Stale file handle */ #define EUCLEAN 117 /* Structure needs cleaning */ #define ENOTNAM 118 /* Not a XENIX named type file */ #define ENAVAIL 119 /* No XENIX semaphores available */ #define EISNAM 120 /* Is a named type file */ #define EREMOTEIO 121 /* Remote I/O error */ #define EDQUOT 122 /* Quota exceeded */
#define ENOMEDIUM 123 /* No medium found */ #define EMEDIUMTYPE 124 /* Wrong medium type */ #define ECANCELED 125 /* Operation Canceled */ #define ENOKEY 126 /* Required key not available */ #define EKEYEXPIRED 127 /* Key has expired */ #define EKEYREVOKED 128 /* Key has been revoked */ #define EKEYREJECTED 129 /* Key was rejected by service */
/* for robust mutexes */ #define EOWNERDEAD 130 /* Owner died */ #define ENOTRECOVERABLE 131 /* State not recoverable */
#define ERFKILL 132 /* Operation not possible due to RF-kill */
#define EHWPOISON 133 /* Memory page has hardware error */
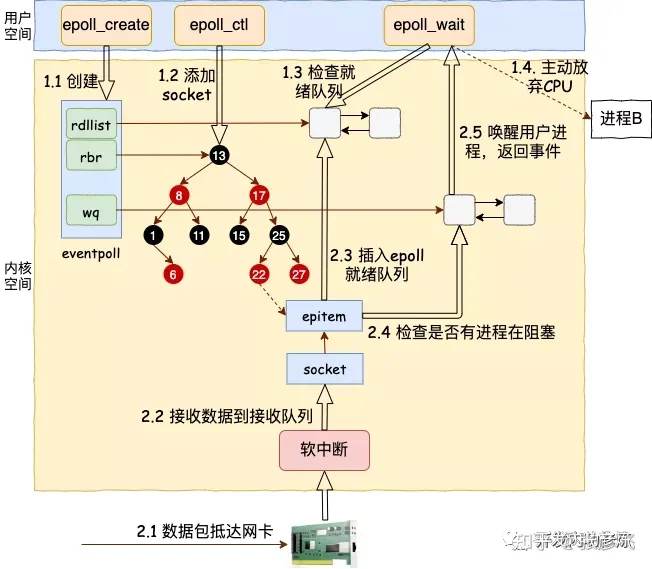
while (!stop_server) { //等待所监控文件描述符上有事件的产生 int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1); if (number < 0 && errno != EINTR) { break; } //对所有就绪事件进行处理 for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd;//通过epollfd监听到的就绪事件会放在events数组
//处理新到的客户连接 if (sockfd == listenfd) { structsockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); //LT水平触发 #ifdef LT int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { continue; } if (http_conn::m_user_count >= MAX_FD) { show_error(connfd, "Internal server busy"); continue; } #endif
//ET非阻塞边缘触发 #ifdef ET //需要循环接收数据 while (1) { int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { break; } if (http_conn::m_user_count >= MAX_FD) { show_error(connfd, "Internal server busy"); break; } users[connfd].init(connfd, client_address); } continue; #endif }
//定义http响应的一些状态信息 constchar *ok_200_title = "OK"; constchar *error_400_title = "Bad Request"; constchar *error_400_form = "Your request has bad syntax or is inherently impossible to staisfy.\n"; constchar *error_403_title = "Forbidden"; constchar *error_403_form = "You do not have permission to get file form this server.\n"; constchar *error_404_title = "Not Found"; constchar *error_404_form = "The requested file was not found on this server.\n"; constchar *error_500_title = "Internal Error"; constchar *error_500_form = "There was an unusual problem serving the request file.\n";
if (users.find(name) == users.end())//没有这个名字 { m_lock.lock();//操作数据库,互斥 int res = mysql_query(mysql, sql_insert);//数据库,没有给mysql变量赋一个连接啊? users.insert(pair<string, string>(name, password));//map m_lock.unlock();
voidinit(int port , string user, string passWord, string databaseName, int log_write , int opt_linger, int trigmode, int sql_num, int thread_num, int close_log, int actor_model);
classSolution { public: boolexist(vector<vector<char>>& board, string word){ n = board.size(); m = board[0].size();//初始化行列 for(int i=0;i<n;i++) for(int j=0;j<m;j++) if(dfs(board,word,i,j,0))//对每个位置都dfs,0表示单词开始,如果找到则直接返回true returntrue; returnfalse; } private: int n, m;//声明行列 booldfs(vector<vector<char>>& board, string word, int i, int j, int k) { if(i<0||j<0||i>=n||j>=m||board[i][j]!=word[k]) returnfalse;//越界或不对应则剪枝 if(k==word.size()-1) returntrue;//没越界且对应,长度也对应,成功 //标记 board[i][j] = '\0'; //向上下左右出发,k+1 bool res = dfs(board, word, i+1, j, k+1)||dfs(board, word, i, j+1, k+1)|| dfs(board, word, i-1, j, k+1)||dfs(board, word, i, j-1, k+1); board[i][j] = word[k];//标记回来 return res; } }; /* 执行用时:520 ms, 在所有 C++ 提交中击败了18.67%的用户 内存消耗:5.9 MB, 在所有 C++ 提交中击败了98.27%的用户 */
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m-1] 。请问 k[0]\*k[1]\*...*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
classSolution { public: intcuttingRope(int n){ if (n <= 3) return n - 1;//必须切分一次 long ret = 1; if (n % 3 == 1){ ret = 4;//最后的4变成2*2 n = n - 4; } if (n % 3 == 2){ ret = 2;//最后的2留着 n = n - 2; } while (n) { ret = ret * 3 % 1000000007;//这里可以取模的原因是,跟max不同,ret是已经确定好的答案,只是一直没算完, //先模后模的结果是一样的 n = n - 3; } return (int)ret; } }; /* 执行用时:0 ms, 在所有 C++ 提交中击败了100.00%的用户 内存消耗:5.7 MB, 在所有 C++ 提交中击败了86.22%的用户 */
voidsaveNum(string &number)//这个函数主要是把number前面多余的0去掉 { string s = "0"; int len = number.size(); int notzero = len;//如果都为0则notzero不会被重新赋值,这会使后面那个循环直接跳过,使得s不变就是"0"
classSolution { public: intmaxSubArray(vector<int>& nums){ int n = nums.size(); int pre = nums[0]; int res = pre; for(int i=1;i<n;i++) { /* 等价于: cur = max(pre,0)+nums[i]; pre = cur; */ pre = max(pre,0)+nums[i];//其实就是pre = cur = max(pre,0)+nums[i]; cur完全不需要。 res = max(res,pre); } return res; } }; /* 执行用时:12 ms, 在所有 C++ 提交中击败了95.96%的用户 内存消耗:22.3 MB, 在所有 C++ 提交中击败了88.01%的用户 */
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3 输出:Reference of the node with value = 8 输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
classSolution { public: vector<int> singleNumbers(vector<int>& nums){ //先遍历异或找出z int z = 0;//初始为0,因为0异或谁结果就是谁 for(int num : nums) z ^= num;//注意这里是^=,z=z异或num //找出z为1的第m位 int m = 1;//00000....00001 while((z&m) == 0) m <<= 1;//如果与运算是0,说明还没到1的那位,m左移把1对过去,注意这里是<<=,m等于m左移一位
//现在知道m了,边分组边异或 int x=0, y=0;//初始化同z for(int num : nums) { if(num&m) x ^= num;//第m位为1的异或 else y ^= num;//第m位为0的异或 //两个数字肯定不在一起异或,因为第m位不同 } return vector<int> {x,y}; } }; /* 执行用时:12 ms, 在所有 C++ 提交中击败了89.84%的用户 内存消耗:15.6 MB, 在所有 C++ 提交中击败了85.82%的用户 */
classSolution { public: intlastRemaining(int n, int m){ int x = 0;//n=1时的结果 for(int i=2;i<=n;i++)//从n=1递推到n=2,一直递推到n x = (x+m)%i; return x; } }; /* 执行用时:4 ms, 在所有 C++ 提交中击败了93.52%的用户 内存消耗:5.7 MB, 在所有 C++ 提交中击败了94.35%的用户 */
classSolution { public: //分为无进位加法结果n和进位结果c,则a+b=n+c intadd(int a, int b){ //位运算,把a当结果,把b加到a上 int c;//存储进位,无进位加法结果直接存a上,相当于n=a^b,下一轮两个加数是n和c,则n=a,b=c;n可以用a替代 while(b)//b不为0时进行,b为0说明加完了 { //c++不支持负数左移,要转unsigned,因为整个过程只是bit串运算,不用管正负,不需要c++去解释正负 c = (unsignedint)(a&b) << 1;//两数的每个bit的进位
//无进位加法,加完再和进位加就可以 a = a^b;//对于加法,都是1就进位,结果是0,都是0那结果也是0。都是1时进位在c那 b=c;//c已经左移过了,本身是要a+c,但也不能用加法,所以还是要异或,a+c就像a+b一样,一直循环直到没进位 } return a; } }; /* 执行用时:0 ms, 在所有 C++ 提交中击败了100.00%的用户 内存消耗:5.7 MB, 在所有 C++ 提交中击败了69.28%的用户 */
classSolution { public: intnumSubarrayProductLessThanK(vector<int>& nums, int k){ //滑动窗口 int i=0, n=nums.size(); int pro = 1; int res = 0; //根据右边界来计数,每移动一次j都要更新值,所以用for的形式移动 for(int j=0;j<n;j++) { pro *= nums[j]; //i能等于j是为了能跳过某个本身就大于k的数,此时i=j+1,更新计数j-i+1也是0,然后就从下一个数开始 while(i<=j && pro >= k)//如果pro较大,移动左边界直到窗口符合条件 { pro /= nums[i]; i++; } //有符合的窗口 res += j-i+1; } return res; } }; /* 执行用时:64 ms, 在所有 C++ 提交中击败了71.68%的用户 内存消耗:59.7 MB, 在所有 C++ 提交中击败了65.21%的用户 */
classSolution { public: intpivotIndex(vector<int>& nums){ //实际上就是遍历i,看每个i能不能当中心下标 //那么在遍历的时候,累加前缀和和累减后缀和就可以判断了 int after = 0; int pre = 0; int res = -1; for(int num:nums) after += num; for(int i=0;i<nums.size();i++) { after -= nums[i];//首先要减去这个值,把i空出来 if(pre == after)//然后pre先别加再判断 { res = i; break;//找最左边的 } pre += nums[i];//往后移,pre填上 } return res; } }; /* 执行用时:12 ms, 在所有 C++ 提交中击败了97.48%的用户 内存消耗:30.1 MB, 在所有 C++ 提交中击败了92.36%的用户 */